使用賽靈思Vivado設計套件的九大理由

您的開發團隊是否需要在極短的時間內打造出既復雜又富有競爭力的新一代系統?賽靈思All Programmable器件可助您一臂之力,它相對傳統可編程邏輯和I/O,新增了軟件可編程ARM®處理系統、可編程模擬混合信號(AMS)子系統和不斷豐富的高復雜度的IP,支持開發團隊突破原有的種種設計限制。賽靈思有多種All Programmable器件可供用戶選擇,構成這些器件的各種硅片組合使用賽靈思獨特的高性能3D堆疊硅片互聯技術彼此互聯。這些領先一代的All Programmable器件為用戶提供的功能,遠超常規可編程邏輯所能及,為用戶開啟了一個全面可編程系統集成的新時代。
本文引用地址:http://www.j9360.com/article/185311.htmAll Programmable抽象化與自動化

All Programmable抽象化與自動化有何意義?
其意義在于采用賽靈思All Programmable器件,用戶的開發團隊可以用更少的部件實現更多系統功能,提升系統性能,降低系統功耗,減少材料清單(BOM)成本,同時滿足嚴格的產品上市時間要求。但如果不借助強大的硬件、軟件、系統設計工具和設計流程,則無法將這些優勢交到您的設計團隊的手中,您也不可能實現這些優勢。賽靈思把所需的這些硬件、軟件和系統設計開發流程統稱為“All Programmable 抽象化 (All Programmable Abstraction)”。
在這種使用All Programmable抽象化進行先進的領先一代的硬件、軟件和系統開發過程中,起著核心作用的是賽靈思Vivado®設計套件。Vivado設計套件是一種以IP和系統為中心的、領先一代的全新SoC增強型綜合開發環境,可解決用戶在系統級集成和實現過程中常見的生產力瓶頸問題。
就在同類競爭解決方案還在試圖通過擴展過時且松散連接的分立工具來跟上片上集成的高速發展的時候,Vivado設計套件憑借業界最先進的SoC增強型設計方法和算法,提供了獨特、高度集成的開發環境,為設計者帶來了設計生產力的極大提升。Vivado設計套件將硬件、軟件和系統工程師的生產力提升到了一個全新的水平。
以下九大理由,將讓您了解到Vivado設計套件為何能夠提供領先一代的設計生產力、簡便易用性, 以及強大的系統級集成能力:
加快系統實現
理由一:突破器件密度極限:在單個器件中更快速集成更多功能。
如果設計工具能夠讓All Programmable器件集成更多功能,用戶就能夠在系統設計中選擇盡可能小的器件,從而直接帶來系統成本和功耗的下降。Vivado設計套件提供一種集成環境,能夠讓架構、軟件和硬件開發人員在通用設計環境中協作工作,從而最大程度地提升設計效率,充分發揮All Programmable器件的可編程邏輯架構及其專用片上功能模塊的潛力。
以OpenCores.org的以太網MAC(媒體訪問控制器)模塊設計為例。作為實驗,賽靈思反復原樣復制OpenCores以太網MAC,直至它們填充帶有693,120個邏輯單元的Virtex®-7 690T FPGA。賽靈思又以類似的方法填充帶有622,000個邏輯單元的同類競爭器件。下圖顯示的是實驗結果。
按邏輯單元數量來衡量(一個“標準”的邏輯單元由一個4輸入LUT(查找表)和一個觸發器組成),賽靈思Virtex-7 690T器件的原始容量比同類競爭器件(帶有622,000個邏輯單元)高出11%。但如圖1所示,如果用Vivado設計套件將所有這些以太網MAC模塊實例填充到賽靈思Virtex-7 690T器件中,賽靈思Virtex-7 690T器件要比同類競爭器件容納的實例數多出36%。這個實驗表明,Vivado設計套件與賽靈思7系列FPGA架構結合使用所產生的效率,要遠高于同類競爭工具/器件組合所產生的效率。
(注:圖1根據LUT和Slice計數結果,對賽靈思7系列All Programmable器件和同類競爭可編程邏輯器件進行比較。賽靈思7系列All Programmable器件slice含四個6輸入LUT、八個觸發器以及相關的多路復用器和算術進位邏輯,相當于1.6個邏輯單元。)
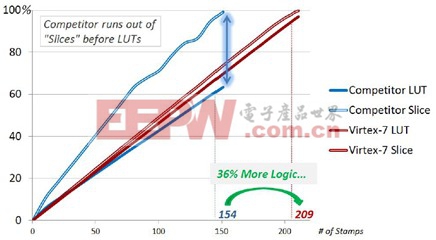
圖1:復制次數與架構資源利用率的對比
Vivado設計套件如何最大化器件利用率
Vivado設計套件之所以能夠實現更高的器件利用率,是因為它采用高級擬合算法,而且賽靈思7系列可編程邏輯架構在每個Slice內采用真正獨立的LUT。值得注意的是,圖1詳盡地體現了賽靈思7系列的LUT和Slice擬合結果,兩者均實現了近100%的利用率。而同類競爭的可編程邏輯器件在器件利用率僅達到63%就用盡了可用的Slice。產生這種低利用率的根源歸咎于該競爭器件的可編程邏輯架構,這種架構在許多情況下不允許把兩個LUT捆綁成一個物理集群。在完整的設計中,這顯然會產生大量未充分利用的集群。這是由于為了滿足架構的引腳共享要求,只有一個LUT得到使用,而另一個LUT則不能再用于設計中其余的邏輯。這項實驗清楚地表明,用戶可以使用更小的7系列All Programmable來實現更大的系統設計。
在這個IP模塊擬合實驗中,Vivado設計套件與同類可編程器件形成了鮮明的對:Vivado設計套件實現了99%的LUT利用率,而且即便在如此高利用率水平下,它還能在完成設計布局布線的同時,滿足時序約束。Vivado布局布線算法旨在處理高密度、高難度設計,便于用戶將更多邏輯置于該器件中,從而降低用戶的系統材料清單(BOM)成本和系統功耗。
理由二:Vivado以可預測的結果提供穩健可靠的性能和低功耗
出于納米級IC設計的物理原因,互聯已經成為28nm及更高工藝節點的可編程邏輯器件架構的性能瓶頸。Vivado設計套件采用先進的布局布線算法,可突破該性能瓶頸,而且點擊鼠標即可得到高性能結果。
Vivado設計套件的分析型布局布線算法能夠同步優化包括時序、互聯使用和走線長度在內的多重變量,提供可預測的設計收斂。同時,Vivado的實現引擎可保證在邏輯利用率高的大型器件上得到的結果和在器件利用率較低的設計上得到的結果一樣優異。此外,在系統設計規模隨著系統功能的增加而逐步增大的情況下,Vivado既能保持高性能結果,還能提高各次運行結果間的一致性。
如圖2所示,與同類競爭工具相比,Vivado設計套件可隨著利用率的提升提供更出色的性能,同時還能處理更大規模的設計。

c++相關文章:c++教程









評論