加速基于 Arm Neoverse N2 的大語言模型推理

人工智能 (AI) 正在眾多行業掀起浪潮,尤其是在大語言模型 (LLM) 問世后,AI 發展呈現井噴之勢。LLM 模型不僅極大改變了我們與技術的交互方式,并且在自然語言理解和生成方面展現出了驚人的能力。雖然 GPU 在訓練生成式 AI 模型方面發揮了重要作用,但在推理領域,除了 GPU 和加速器之外,還有其他可行的選擇。長期以來,CPU 一直被用于傳統的 AI 和機器學習 (ML) 用例,由于 CPU 能夠處理廣泛多樣的任務且部署起來更加靈活,因此當企業和開發者尋求將 LLM 集成到產品和服務中時,CPU 成了熱門選擇。
本文引用地址:http://www.j9360.com/article/202407/460787.htm在本文中,我們將探討基于 Arm Neoverse N2 的阿里巴巴倚天 710 CPU 在運行 Llama 3 [1] 和 Qwen1.5 [2] 等業內標準 LLM 時所展現的靈活性和可擴展性。此外,本文還將通過比較分析,展示倚天 710 CPU 相較于其他基于 CPU 架構的服務器平臺所具備的主要優勢。
阿里云倚天 710 云實例上的 LLM 性能
通用矩陣乘法 (General Matrix Multiplications, GEMM) 是深度學習計算(包括 LLM 中的計算)中廣泛使用的一項基本運算。它對兩個輸入矩陣進行復雜的乘法運算,得到一個輸出。Armv8.6-A 架構增加了 SMMLA 指令,該指令將第一個源矢量中的 2x8 有符號 8 位整數值矩陣與第二個源矢量中的 8x2 有符號 8 位整數值矩陣相乘。然后將生成的 2x2 的 32 位整數矩陣乘積加到目標矢量中的 32 位整數矩陣累加器中。這相當于對每個目標元素執行 8 路點積運算。SMMLA 指令已添加到基于 Neoverse N2 的阿里巴巴倚天 710 CPU 中。
在過去幾個月內,Arm 軟件團隊與合作伙伴緊密協作,利用上述 SMMLA 指令,優化了在 llama.cpp 中實現的 int4 和 int8 GEMM 內核。最近,我們在阿里云倚天 710 云實例上進行了多次實驗,采用了最新的優化 [3][4] ,以評估 llama.cpp 在不同場景下的性能表現。
所有實驗均在阿里云 ecs.g8y.16xlarge 實例上進行,該實例帶有 64 個虛擬 CPU (vCPU) 和 256 GB 的內存。所用的模型是經過 int4 量化的 Llama3-8B 和 Qwen1.5-4B。
提示詞處理
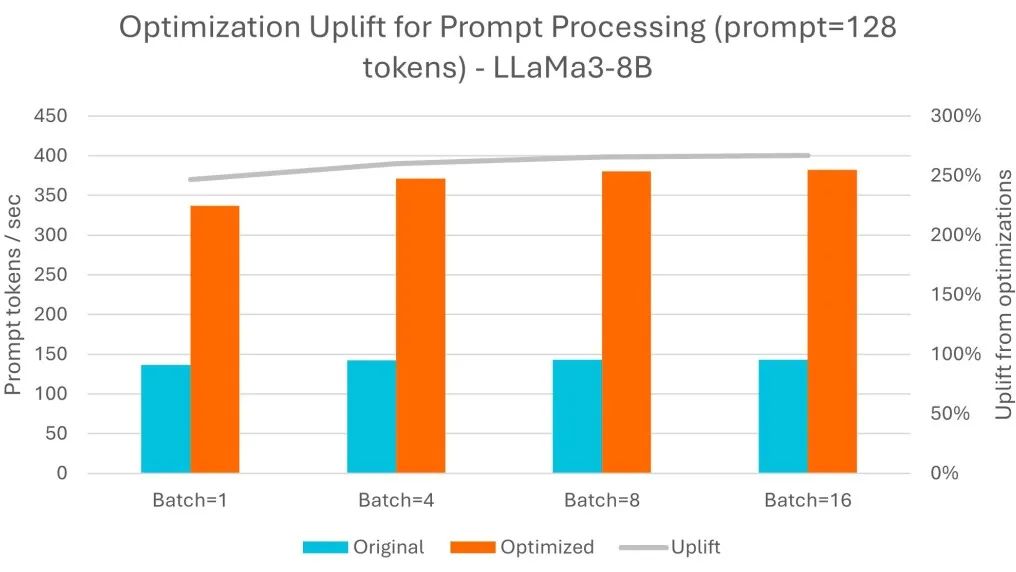
提示詞詞元 (Token) 通常是并行處理的,即使對于單次操作 (batch=1),也會使用所有可用核心,而且隨著批量大小的增加,提示詞處理速率基本不變。在這方面,經過 Arm 優化,每秒處理的詞元數提升了 2.7 倍。
詞元生成
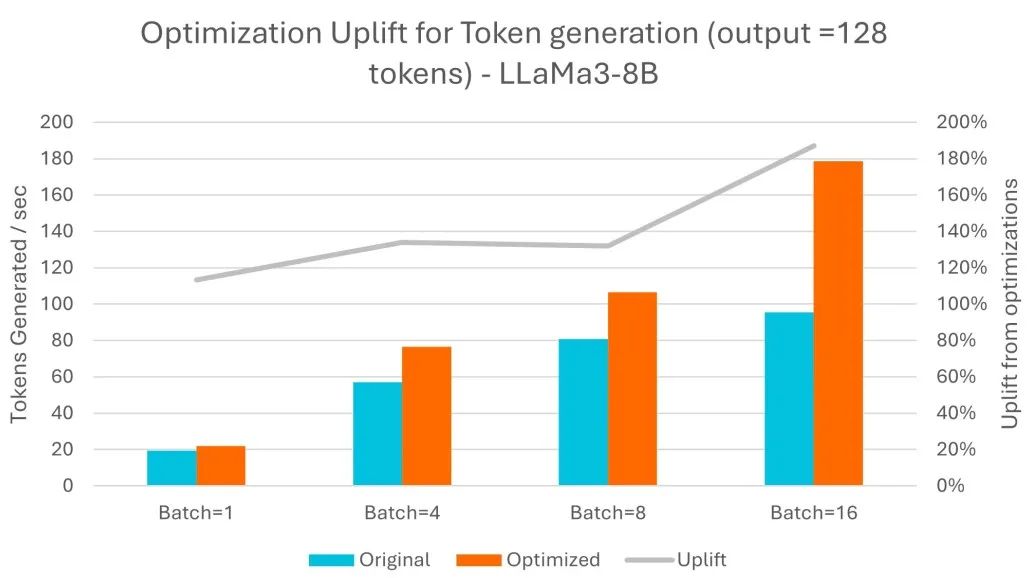
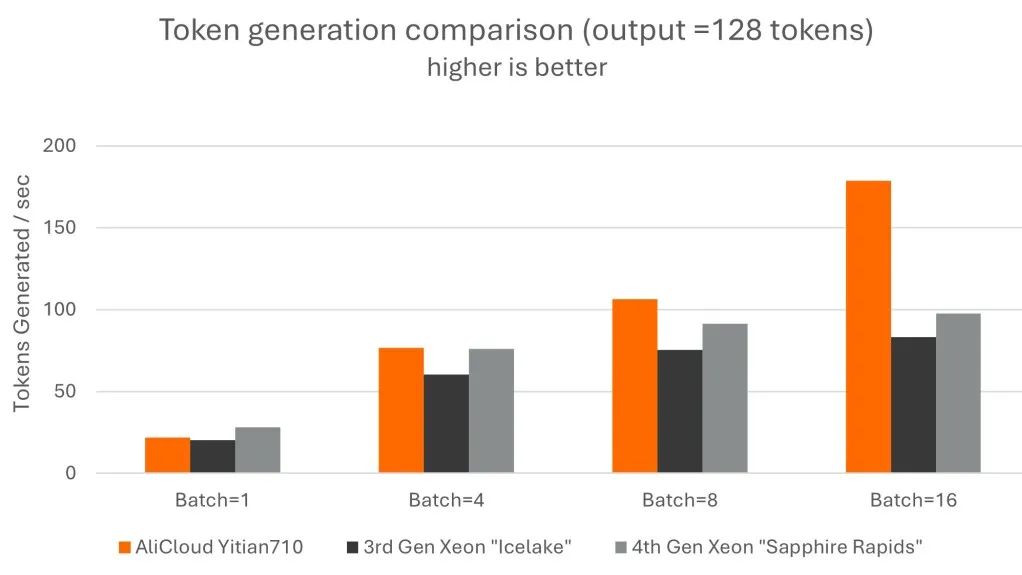
詞元生成以自回歸的方式進行,詞元生成的總時間與需要生成的輸出長度相關。在這方面,經過 Arm 優化,在處理更大批量的數據時提升效果更為明顯,吞吐量最多可提高 1.9 倍。
延遲
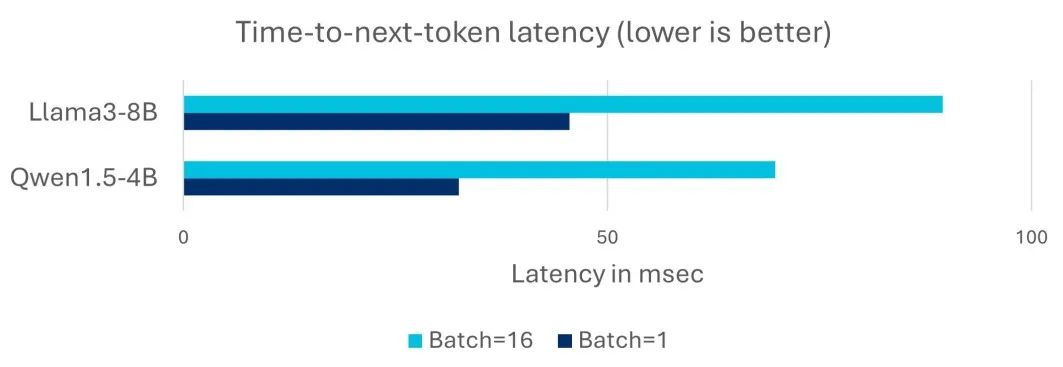
詞元生成的延遲對 LLM 的交互式部署非常重要。對于下個詞元響應時間 (time-to-next-token),100ms 的延遲是關鍵的目標指標,這是基于人們每秒 5-10 個單詞的典型閱讀速度計算得出的。在下方圖表中,我們看到在單次操作和批量處理的場景下,阿里云倚天 710 云實例都能滿足 100ms 的延遲要求,因此是常規體量 LLM 的合適部署目標。我們使用了兩組不同的新模型 Llama3-8B 和 Qwen1.5-4B,以展示實際部署中不同體量的常規 LLM 的延遲情況。
性能比較
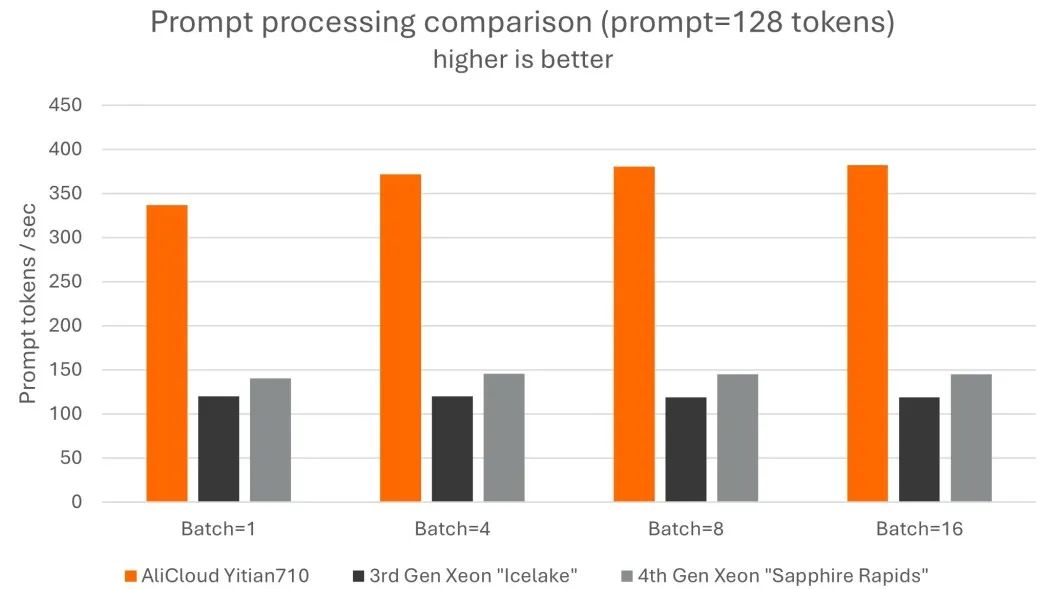
此外,我們使用經過 int4 量化的 Llama3-8B 模型,比較了它在倚天 710 與在阿里云上其他服務器 CPU 的性能 [注] 。
阿里云倚天 710:ecs.g8y.16xlarge,64 個 vCPU,256 GB 內存,12.8 人民幣/小時
Intel Icelake:ecs.g7.16xlarge,64 個 vCPU,256 GB 內存,16.74 人民幣/小時
Intel Sapphire Rapids:ecs.g8i.16xlarge,64 個 vCPU,256 GB 內存,17.58 人民幣/小時
[注] 阿里云倚天 710 采用了 [3][4] 中的優化,Intel Icelake 和 Sapphire Rapids 使用了現有的 llama.cpp 實現。
我們發現,與其他兩款 CPU 相比,阿里云倚天 710 的提示詞處理表現出最高達 3.2 倍的性能優勢,詞元生成性能最高達 2.2 倍的優勢。
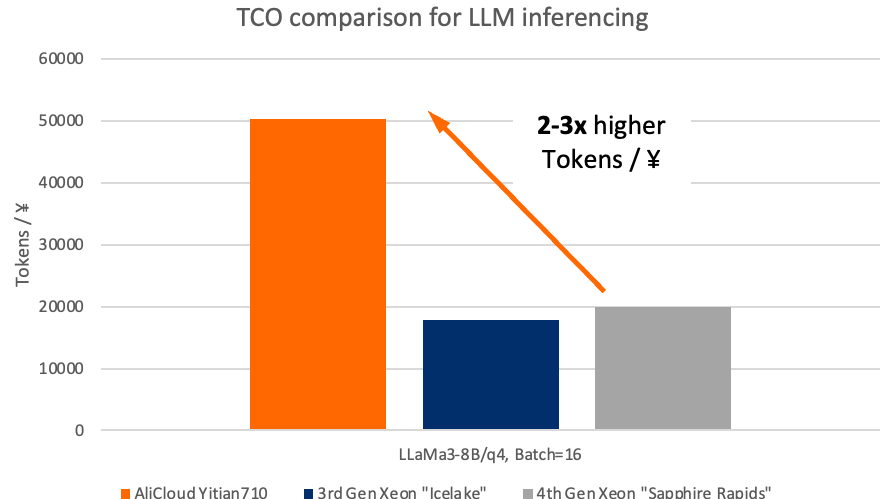
同樣值得注意的是,阿里云倚天 710 平臺的成本效益高于 Icelake 和 Sapphire Rapids,這在阿里云倚天 710 實例相對較低的定價中就有所體現。這使得阿里云倚天 710 在 LLM 推理的總體擁有成本方面具有顯著優勢,與其他兩款 CPU 相比,每元詞元數量最高多了近三倍,這為希望在采用 LLM 的過程中逐步擴大規模的用戶提供了令人信服的優勢。
結論
當開發者想要在應用中部署專用 LLM 時,服務器 CPU 為開發者提供了靈活、經濟和簡化的部署流程。Arm 集成了幾項關鍵的增強功能,大幅提高了 LLM 的性能。得益于此,基于 Arm Neoverse 的服務器處理器(如阿里云倚天 710)能夠提供優于其他服務器 CPU 的 LLM 性能。此外,它們還有助于降低采用 LLM 的門檻,使更多應用開發者能夠輕松將 LLM 部署于各種場景。







評論