OpenVINO? 2025.1 正式發(fā)布!

我們很高興地宣布 OpenVINO? 2025 的最新版本正式發(fā)布!本次更新帶來了來自工程團(tuán)隊(duì)的更多增強(qiáng)功能和新特性。每一次發(fā)布,我們都在不斷適應(yīng)日新月異的 AI 發(fā)展趨勢(shì),迎接層出不窮的新機(jī)遇與復(fù)雜挑戰(zhàn)。在此次版本中,我們重點(diǎn)增強(qiáng)了新模型的覆蓋和實(shí)際應(yīng)用場(chǎng)景的支持,同時(shí)在性能優(yōu)化上也進(jìn)行了深度打磨,幫助你的 AI 解決方案運(yùn)行得更快、更高效。
本文引用地址:http://www.j9360.com/article/202504/469504.htm新模型和應(yīng)用場(chǎng)景
在 2025.1 版本中,我們新增了以下模型的支持: Phi-4 Mini、Jina CLIP v1 和 BCE Embedding Base v1。其中,Phi-4 Mini 來自微軟最新發(fā)布的開源小模型 Phi 系列。你可以在 GitHub 上嘗試這個(gè)模型用它構(gòu)建 LLM 聊天機(jī)器人或探索其他眾多 LLM 模型。我們也非常高興地宣布支持 Jina CLIP v1,這是一種多模態(tài) AI 模型,可連接圖像與文本數(shù)據(jù),廣泛應(yīng)用于視覺搜索、多模態(tài)問答及內(nèi)容生成等場(chǎng)景。我們?cè)?GitHub 上提供了新的交互式示例供開發(fā)者上手體驗(yàn)。下圖展示了該模型的輸出效果:
(https://github.com/openvinotoolkit/openvino_notebooks/tree/0284702fb1c15ac768dd25b72cd824fb79ace4d6/notebooks/llm-chatbot)
(https://github.com/openvinotoolkit/openvino_notebooks/tree/442edcdf618126dd966eed5c687455edba332257/notebooks/jina-clip)
圖片1: 使用 Jina CLIP 以及 OpenVINO? 的 CLIP 模型
(https://github.com/openvinotoolkit/openvino_notebooks/tree/442edcdf618126dd966eed5c687455edba332257/notebooks/jina-clip)
在上一版本中,我們預(yù)覽發(fā)布了 OpenVINO? GenAI 圖像到圖像(image-to-image)轉(zhuǎn)換與修復(fù)(inpainting)功能的支持。本次更新,這兩項(xiàng)功能已全面支持,你可以通過 OpenVINO? 快速部署如 Flux.1 和 Stable Diffusion v3 等圖像生成模型的端到端流程。
OpenVINO? 模型服務(wù)器(OVMS) 現(xiàn)已支持視覺語言模型(VLMs),如 Qwen2-VL、Phi-3.5-Vision 和 InternVL2。借此你可以在對(duì)話場(chǎng)景中發(fā)送圖像進(jìn)行推理,就像處理 LLM 一樣。我們提供了連續(xù)批處理(continuous batching)下 VLM 部署的演示示例。此外,現(xiàn)在你還可以使用 OVMS 將 LLM 與 VLM 模型部署到 NPU 加速器上,在 AI PC 上實(shí)現(xiàn)高能效的低并發(fā)應(yīng)用。我們提供了在 Docker 與裸機(jī)環(huán)境下部署 NPU 上 LLM 與 NPU 上 VLM 的完整示例代碼。
(https://github.com/openvinotoolkit/model_server/tree/main/demos/continuous_batching/vlm)
(https://github.com/openvinotoolkit/model_server/tree/main/demos/llm_npu)
(https://github.com/openvinotoolkit/model_server/tree/main/demos/vlm_npu)

圖2:使用 OpenVINO? GenAI Notebook 生成不同強(qiáng)度的圖像到圖像輸出示例
(https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/image-to-image-genai/image-to-image-genai.ipynb)
(https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/image-to-image-genai/image-to-image-genai.ipynb)
性能提升
我們的開發(fā)團(tuán)隊(duì)也在英特爾? 酷睿? Ultra 200H 系列處理器上進(jìn)一步優(yōu)化了 LLM 性能。與上一版 2025.0 相比,在 2025.1 版本中 GPU 上的第二個(gè) token 吞吐量提高了 1.4 倍,具體基準(zhǔn)測(cè)試結(jié)果見下圖。
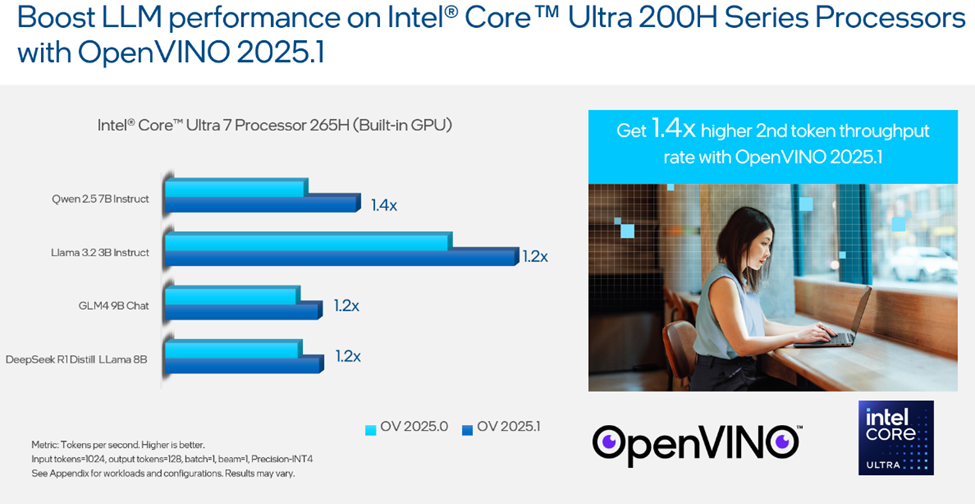
圖3:OpenVINO? 2025.1 提升英特爾? 酷睿? Ultra 200H 系列處理器上 LLM 性能,詳見附錄中的負(fù)載與配置。結(jié)果可能因場(chǎng)景而異。
本次更新的一個(gè)重要亮點(diǎn)是預(yù)覽支持 Token Eviction(token 清除)機(jī)制,用于智能管理 KV 緩存大小。該機(jī)制可自動(dòng)保留重要 token、清除不必要信息,在保證模型表現(xiàn)的同時(shí),大幅降低內(nèi)存占用,尤其適用于處理長輸入提示的 LLM 和 VLM 應(yīng)用。Token 被清除后,KV 緩存會(huì)自動(dòng)“重排”以保持上下文連貫性。
Executorch
對(duì)于 PyTorch 模型,Executorch 提供了在邊緣設(shè)備上高效運(yùn)行模型的能力,適用于計(jì)算資源與內(nèi)存受限的場(chǎng)景。在此次 OpenVINO? 新版本中,我們引入了 Executorch 的 OpenVINO? 后端預(yù)覽支持,可加速推理并提升模型在英特爾 CPU、GPU 與 NPU 上的執(zhí)行效率。如需開始使用 OpenVINO? 后端運(yùn)行 Executorch,請(qǐng)參考 GitHub 上的相關(guān)文檔。
(https://github.com/pytorch/executorch/blob/main/docs/source/build-run-openvino.md)
OpenVINO? 模型中心(OpenVINO? Model Hub)
如果你對(duì)性能基準(zhǔn)感興趣,可以訪問全新上線的 OpenVINO? 模型中心(Model Hub)。這里提供了在 Intel CPU、集成 GPU、NPU 及其他加速器上的模型性能數(shù)據(jù),幫助你找到最適合自己解決方案的硬件平臺(tái)。
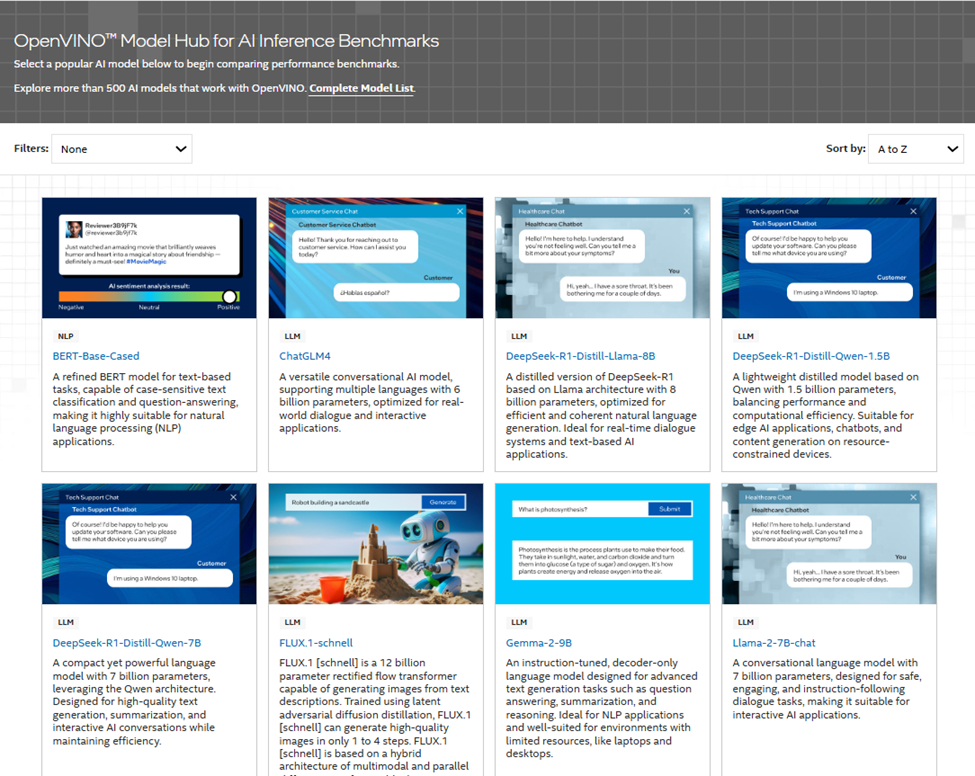
圖4:OpenVINO? 模型中心展示 AI 推理基準(zhǔn)性能
小結(jié)
感謝你關(guān)注并參與 OpenVINO? 的最新版本發(fā)布。我們始終致力于推動(dòng) AI 無處不在。
附錄



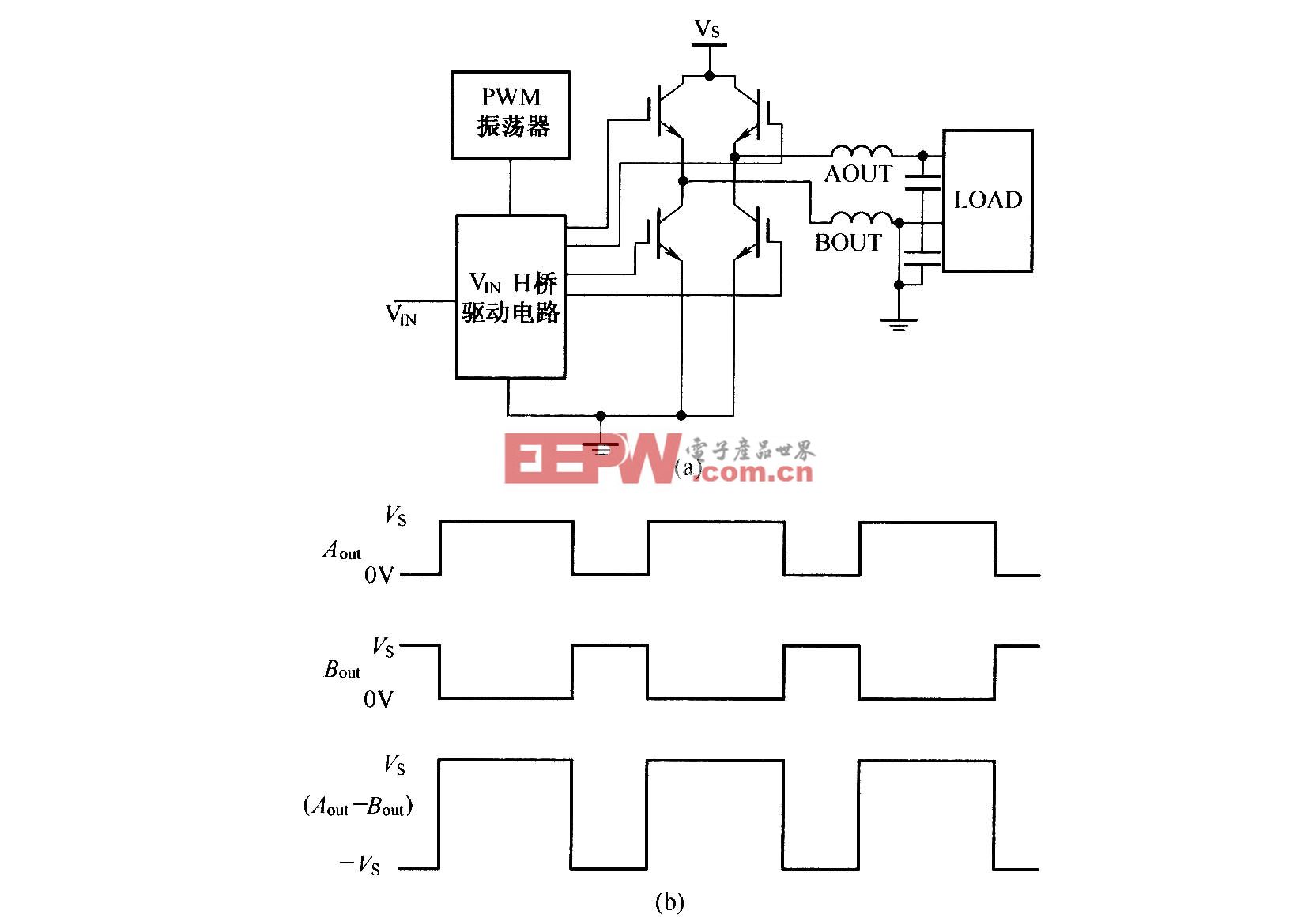




評(píng)論