基于虛擬化與分布式技術的存儲系統

摘要:介紹了一套基于云計算(cloud computing)技術的數據應用平臺系統設計方案。該系統由多組服務器集群組成,可提供數據存儲、備份和并行運算服務。并可采用虛擬化應用端與分布式(Hadoop)技術相結合的方式為用戶提供高容量和異構應用存儲系統,以便結合iSCSI協議在硬件層獲得更靈活的部署。
關鍵詞:虛擬化;數據處理;分布式存儲;云計算
0 引言
通過FreeBSD系統搭建開源的Hadoop存儲應用基礎,依托在服務器虛擬化(VMware)的平臺上進行運行,這樣能夠擁有更快、更穩定、更安全的硬件保障,使用iSCSI技術,盡可能降低存儲部署成本。本系統利用VMware虛擬化平臺將服務器硬件存儲資源進行整合,通過建立Lun將服務器的磁盤陣列進行劃分,組成多個磁盤邏輯,然后通過在Lun上安裝FreeBSD操作系統及搭建iSCSI服務器端,使得存儲硬件資源能夠靈活地應用在Hadoop系統中。Hadoop將部署在虛擬化硬件平臺上構成一個分布式的文件系統,通過WebDAV協議建立與客戶端服務器的應用通信。用戶可以通過訪問客戶端服務器,將文件通過WebDAV以HTTPS方式傳輸到Hadoop存儲集群中保存。
該平臺的設計充分利用了虛擬化與分布式技術的特點,采用多層次的模塊化應用將整個存儲系統從硬件架構到軟件應用方式都變得靈活和易擴展,同時又因為虛擬化與分布式技術本身的安全特性,系統在數據安全性上具有先天優勢,從而實現數據存儲服務的低成本部署。
1 系統設計原理
存儲系統采用底層云存儲技術與應用層iSCSI技術來為用戶提供跨系統應用平臺支持。其工作原理如圖1所示。
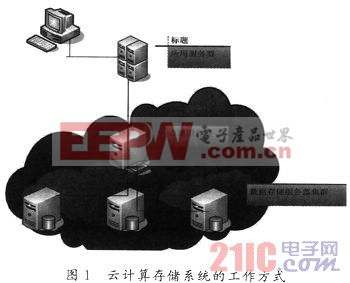
系統首先由多臺數據存儲服務器通過iSCSI網絡構成一個龐大的數據存儲服務集群,每一臺數據服務器的配置是相同的。當數據達到存儲池飽和狀態時,可以將同樣配置的服務器加入到這個存儲網絡中,在不改變原有系統運行狀態下實現擴容。
系統采用VMware ESXi Server虛擬系統作為應用服務器集群底層系統,各應用服務器系統可在VMware虛擬系統之上建立邏輯上的關聯。 VMware允許多個操作系統并行運行于一臺高性能服務器之上和多個高性能服務器運行同一任務,同時通過網絡對操作系統進行備份和管理,能夠依據應用服務使用狀況對操作系統實施遷移和復制,從而擴大網絡應用處理帶寬。
在VMware層上安裝FreeBSD系統平臺搭建Hadoop分布式存儲系統,Hadoop系統能將數據同時分割成許多小塊和備份,通過點播服務器(NameNode)存放于不同的數據存儲服務器中。在Hadoop系統中,會有一臺Master,主要負責NameNode的工作以及JobTracker的工作。Job Tracker的主要職責就是啟動、跟蹤和調度各個Slave的任務執行。還會有多臺Slave,每一臺Slave通常具有DataNode的功能并負責Task Tracker的工作。TaskTracker根據應用要求來結合本地數據執行Map任務以及Reduce任務。
在NameNode上部署WebDAV應用,實現應用服務器對存儲資源的通信,從而讓用戶調用Hadoop上的數據。WebDAV(Web-based Distributed Authoring and Versioning)是基于HTTP 1.1的一個通信協議。它為HTTP 1.1添加了一些擴展(就是在GET、POST、HEAD等幾個HTTP標準方法以外添加了一些新的方法),使得應用程序可以直接將文件寫到Web Server上,從而替代傳統的FTP傳輸文件模式。
2 系統關鍵技術實現
存儲平臺通過在Hadoop上部署WebDAV,可實現客戶端(應用服務器)對服務器端(Hadoop節點服務器)的復制和移動文件,并可進行多用戶同時讀取一個文件等操作。
實施步驟(以四臺服務器為例,結合局域網內DNS服務器):
第一步:Hadoop環境搭建使用Hadoop的用戶,機器名和IP依次為域名vc1(192.168.1.1),域名vc2(192.168.1.2),域名vc3(19 2.168.1.3)和域名vc4(192.168.1.4)。這是因為四臺機器中vc3作為Hadoop的Namenode,其他的作為Datanode。
詳細環境配置介紹如下:
Hadoop版本為0.20.2;
JDK版本為1.6.0;
操作系統為FreeBSD8.0(最小化安裝)。
ve3(192.168.1.3)是NameNode(Master),其他三臺作為DateNode(slave).
Hadoop是Java語言編寫的機群程序,它的安裝是建立在ssh和JDK之上的,所以在配置Hadoop之前首先要對系統進行ssh和JDK的安裝與配置。
(1)通過ssh來實現Hadoop節點之間用戶的無密碼訪問
①在各個節點的/etc/hosts文件中添加節點IP及對應機器名,并在各個節點上建立相同用戶名與密碼的賬戶。
修改/etc/hosts文件如下:
192.168.1.1 vc1
192.168.1.2 vc2
192.168.1.3 vc3
192.168.1.4 vc4
修改成功后就可以實現IP地址與機器名的對應解析。
在各個節點建立用戶名為Hadoop,密碼為123456的用戶。






評論