Xilinx UltraScale?:為您未來架構而打造的新一代架構

UltraScale架構與Vivado™設計套件結合使用可提供如下這些新一代系統級功能:
本文引用地址:http://www.j9360.com/article/147542.htm 針對寬總線進行優化的海量數據流,可支持數Tb級吞吐量和最低時延
高度優化的關鍵路徑和內置高速存儲器,級聯后可消除DSP和包處理中的瓶頸
增強型DSP slice包含27x18位乘法器和雙加法器,可以顯著提高定點和IEEE 754標準浮點算法的性能與效率
第二代3D IC系統集成的晶片間帶寬以及最新3D IC寬存儲器優化接口均實現階梯式增長
類似于ASIC的多區域時鐘,提供具備超低時鐘歪斜和高性能擴展能力的低功耗時鐘網絡
海量I/O和存儲器帶寬,用多個硬化的ASIC級100G以太網、Interlaken和PCIe® IP核優化,可支持新一代存儲器接口功能并顯著降低時延
電源管理可對各種功能元件進行寬范圍的靜態與動態電源門控,實現顯著節能降耗
新一代安全策略,提供先進的AES比特流解密與認證方法、更多密鑰模糊處理功能以及安全器件編程
通過與Vivado工具協同優化消除布線擁塞問題,實現了90%以上的器件利用率,同時不降低性能或增大時延
系統設計人員將這些系統級功能進行多種組合,以解決各種問題。下面的寬數據路徑方框圖可以很好地說明這一問題。見圖3.
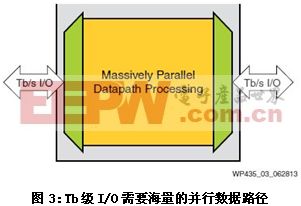
圖中,數據速率高達Tbps的數據流從從左側流入再從右側流出。系統必須在左右兩側的I/O端口之間傳輸數據流,同時還要執行必要的處理工作。可以通過高速串行收發器來進行I/O傳輸,運行速率高達數Gbps。一旦數Gbps的串行數據流進入器件,就必須扇出(fan out),以便與片上資源的數據流、路由和處理能力相匹配。
Tb級系統的設計挑戰:時鐘歪斜與海量數據流
舉一個現實的實例,假設左側和右側I/O端口的帶寬為100Gb/s。這意味著片上資源也必須要處理至少100Gb/s的流量。設計人員一般采用512至1024位的寬總線或數據路徑來處理相關的數據吞吐量,產生一個與片上資源功能相匹配的系統時鐘。如果線速提高到400Gb/s,那么總線寬度達到1024至2048位也并不少見。
現在考慮一下這類總線的時鐘要求。在UltraScale架構推出之前,高系統時鐘頻率運行會使這些海量數據路徑上的時鐘歪斜程度增大,甚至達到整個系統時鐘周期的將近一半。時鐘歪斜幾乎占用一半的時鐘周期,這種情況下設計方案需要依靠大量流水線才有可能達到目標系統性能。只剩下一半的時鐘周期可用于計算,因此得到可行解決方案的幾率就會很低。大量使用流水線不僅會占用大量寄存器資源,而且還會對系統的總時延造成巨大影響,這也再次證明了這種方法在當今的高性能系統中不可行。
UltraScale架構提供類似ASIC時鐘功能
多虧UltraScale架構提供類似ASIC的多區域時鐘功能,使得設計人員現在可以將系統級時鐘放在整個晶片的任何最佳位置上,從而使系統級時鐘歪斜降低多達50%。將時鐘驅動的節點放在功能模塊的幾何中心并且平衡不同葉節點時鐘單元(leaf clock cell)的時鐘歪斜,這樣可以打破阻礙實現多Gb系統級性能的一個最大瓶頸。系統總體時鐘歪斜降低后,就無需再使用大量流水線,并可消除隨之而來的時延問題。UltraScale架構中類似于ASIC的時鐘功能不僅能移除時鐘布置方面的限制,還能在系統設計中實現大量獨立的高性能、低歪斜時鐘源。這與前幾代可編程邏輯器件中所采用的時鐘方案完全不同。從系統設計人員的角度出發,這種解決方案能輕松解決時鐘歪斜問題。
從容應對海量數據流挑戰
極高性能應用一般采用寬總線或寬數據路徑來匹配路由到片上處理資源的數據流。然而采用寬總線來擴展性能時,除了要簡單處理時鐘歪斜問題外,還要應對一系列自身挑戰。眾所周知,同類競爭架構經證實其適用于高性能設計的布線資源非常有限且缺乏靈活性。如果FPGA的互連架構性能較低,那么用它來實現100Gb/s吞吐量的應用時,需要將數據總線提升到1536至2048位的寬度。
盡管更寬的總線實現方案可以降低系統時鐘頻率,但由于缺乏支持寬總線系統所需的布線資源,因此會產生嚴重的時序收斂問題。而且有些FPGA廠商采用的是過時的模擬退火布局布線算法,不考慮擁塞程度和總線路長度等全局設計指標,因此會進一步加劇時序收斂問題。這樣,設計人員就不得不進行多方面權衡,包括降低系統性能(通常不可取);使用大量流水線,不惜增大時延;或者降低可用器件資源利用率。在任何情況下,經證明這些解決方案都是不佳或存在欠缺的方案。最重要的是,傳統FPGA中布線資源(用于滿足100Gb/s應用的要求)的局限性幾乎可以說明它們不可能適用新一代多Tb應用的要求,即便能適用,但器件的利用率會非常低,時延極高。

存儲器相關文章:存儲器原理




評論