32位內核與基于微控制器存儲架構的集成

32 位 MCU 性能差異
微控制器(MCU)領域如今仍由 8 位和 16 位器件控制,但隨著更高性能的 32 位處理器開始在 MCU 市場創(chuàng)造巨大收益,在系統設計方面,芯片架構師面臨著 PC 設計人員早在十年前便遇到的挑戰(zhàn)。盡管新內核在速度和性能方面都在不斷提高,一些關鍵支持技術卻沒有跟上發(fā)展的步伐,從而導致了嚴重的性能瓶頸。
很多 MCU 完全依賴于兩種類型的內部存儲器件。適量的 SRAM 可提供數據存儲所需的空間,而 NOR 閃存可提供指令及固定數據的空間。
在新 32 位內核的尺寸和運行速度方面,嵌入式 SRAM 技術正在保持同步。成熟的 SRAM 技術在 100MHz 的運行范圍更易于實現。對 MCU 所需的典型 RAM 容量來說,這個速度級別也更具成本效益。
但是標準的 NOR 閃存卻落在了基本 32 位內核時鐘速度之后,幾乎相差一個數量級。當前的嵌入式 NOR 閃存技術的存取時間基本為 50ns (20 MHz)。這在閃存器件和內核間轉移數據的能力方面造成了真正的瓶頸,因為很多時鐘周期可能浪費在等待閃存找回特定指令上。
標準MCU 執(zhí)行模型——XIP (eXecute In Place)更加劇了處理器內核速度和閃存存取時間之間的性能差距。
大容量存儲中的應用容錯及 SRAM較高的成本是選擇直接從閃存執(zhí)行的兩個主要原因。存儲在閃存內的程序基本不會被系統內的隨機錯誤破壞,如電源軌故障。利用閃存直接執(zhí)行還無需為MCU器件提供足夠的 SRAM,來將應用從一個 ROM 或閃存器件復制至目標 RAM 執(zhí)行空間。
消除差距
理想的情況是,改進閃存技術,以匹配32位內核的性能。雖然當前的技術有一定的局限,仍有一些有效的方法,可幫助架構師解決性能瓶頸問題。
簡單的指令預取緩沖器和指令高速緩存系統在32位MCU設計中的采用,將大大提高MCU的性能。下面將介紹系統架構師如何利用這些技術將16位的MCU架構升級至32位內核CPU。
在 MCU 設計中引入 32位內核
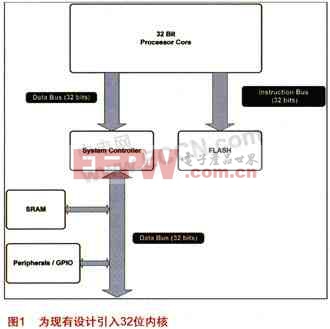
圖 1 介紹了將現有16位設計升級至基本32位內核的情況,顯示了新32 位內核及其基本外設集合之間的基本聯系。由于我們在討論將新的32位處理器內核集成至新的 MCU 設計,我們假設可采用新32位內核采用以下規(guī)范。
32 位內核——改良的哈佛架構
與很多 MCU 一樣,新的 32位 內核也采用改良的哈佛架構。因此,程序存儲和數據存儲空間是在兩個獨立的總線構架上執(zhí)行。一個純哈佛設計可防止數據在程序存儲空間被讀取,該內核改良的哈佛架構設計仍可實現這樣的操作,同時,該32位內核設計還可實現程序指令在數據存儲空間的執(zhí)行。
在標準總線周期內,程序和數據存儲器接口允許插入等待狀態(tài),有助于響應速度緩慢的存儲或存儲映射器件。
32位內核——工作頻率
新內核的最高工作時鐘頻率為120MHz,是被替代的16位內核速度的六倍。
32位內核——指令存儲器接口
指令存儲系統接口有一個32位寬的數據總線,以及一個總共地址空間為1MB的20位寬的地址總線。盡管 32位內核具備更大的地址空間,而這足夠滿足這個MCU的目標應用空間。標準的控制信號同樣具備為緩慢的存儲器件插入等待狀態(tài)的能力。
該設計的閃存器件與16位設計采用的技術一樣,最高運行速度達20 MHz。
32 位內核——數據存儲器接口
系統 SRAM 和存儲器映射外設都通過系統控制器與處理器數據總線相連。系統控制器可提供額外的地址解碼及其他控制功能,幫助處理器內核正確訪問數據存儲器或存儲器映射外設,而無需處理特定的等待狀態(tài)、不同的數據寬度或每個映射到數據存儲空間的器件的其他特殊需求。
系統控制器和處理器內核之間的數據總線為 32 位寬,與系統控制器和SRAM 間的數據總線寬度相同。系統控制器和外設以及 GPIO 端口間的數據總線寬度可為 8 位、16 位或 32 位,視需求而定。
目標設計采用的 SRAM 與 16 位設計采用的類型相同,在 120 MHz時可實現 0 等待狀態(tài)操作。
初步分析
目前系統的性能由幾個因素控制。處理器內核與閃存器件速度的差異可極大地影響性能,因為至少有五個等待狀態(tài)必須添加到每個指令提取中。根據粗粒經驗法則,至少每十個指令有一個讀取或存儲。每條指令加權平均周期(CPI)的典型順序為:
CPI = (9 inst * 6 閃存周期 + 1 inst *1 SRAM周期) / 10 指令
CPI = 5.5
內核的吞吐量由閃存接口的速度決定,因此以前所有的32位內核都是數據通道寬度的兩倍。
在這種情況下,SRAM接口無關緊要。雖然某些問題很有可能源于存儲接口方面,如中斷延遲和原子位處理,SRAM存儲器的零等待狀態(tài)操作可以忽略。關注的重點是通過采用目前可用的、具有成本效益的技術,來提高指令存儲接口的性能。
提高CPU內核性能——閃存接口
來自高性能計算環(huán)境的一個通用概念是高速緩存,在主要存儲器件和處理器內核之間采用更小及更快的內存存儲,可以實現突發(fā)數據或程序指令的更快訪問。
設計和實現高速緩存可能非常復雜——需要考慮高速緩存標記、N-Way級聯和普通高速緩存控制等問題——僅關注程序指令存儲器可讓這項工作變得非常簡單。這是因為對此特定的 32 位內核來說,對程序存儲器的訪問是一個嚴格的只讀操作。在這種情況下,我們只需考慮一個方向的數據流可以減少緩沖器和高速緩存系統的復雜性。
預取緩沖器
增加閃存接口總體帶寬的一個簡單方法是擴展處理器和閃存器件間的通道寬度。假定閃存的速度一定,增加帶寬的另外一個方法是擴展接口寬度,以實現一次提取更多指令,創(chuàng)造一個更為快速的閃存接口外觀。
這是預取緩沖器的一個基本前提。它利用了連接閃存的更寬接口的優(yōu)勢,可在同樣的時鐘周期數內讀取更大的數據量,這通常只要花閃存讀一個字的時間。
因此,預取緩沖器還定義了新數據通道的最小尺寸,原因顯而易見。

圖2.1顯示了我們的120 MHz內核連接到20 MHz閃存陣列的情況。采用兩個系統間的速度比作為起始值,我們可以確定預取緩沖器、閃存接口讀取的寬度,假設我們需要在無需等待狀態(tài)的情況下讀取指令。
在這種情況下,預取/閃存數據通道將是:
(120/20)X32位=192位寬
預取緩沖器控制邏輯不斷對存取緩沖器的讀取數進行標記。最后一次存取后,它將使下一個周期從閃存重新加載整個緩沖器。
預取緩沖器控制邏輯還可識別緩沖器每次進入的有效地址。它還將提供適當的解碼,根據正確的順序指令顯示處理器數據總線,當一個執(zhí)行分支需要完整的新的順序指令時,將重新加載緩沖器。
當然,在提取新的指令時,分支將造成一些額外的延遲。但是由于相比處理器內核,預取緩沖器實現六合一方法在數據通道寬度方面具有絕對的優(yōu)勢,為該分支問題的最終平衡的結果付出的代價是值得的。
更多經驗法則分析都顯示,一個典型的嵌入式應用有20%發(fā)生分支的機會,每五個周期相當于一個分支。采用之前的方法,CPI值現在為:
CPI = (4指令*1周期+1指令*6周期)/5指令
CPI = 2.0
我們已經看到利用基本實現方法,整個系統周期效率有了大幅提高。
圖2.1還顯示了一個更為現實解決方案方法,即將六個獨立的閃存系統的32位總線加在一起,而不是重新設計一個新的、極寬的數據總線閃存系統。預取緩沖器控制邏輯將自動創(chuàng)建六個連續(xù)的程序地址,然后允許一個正常的讀取周期同時訪問所有六個組。在讀取周期的末尾,預取緩沖器現在可保持六個新的指令,而非一個,模擬的零等待狀態(tài)系統。
指令高速緩存
形式指令高速緩存賦予預







評論