一文讀懂|什么是機器學習

機器學習定義
本文引用地址:http://www.j9360.com/article/202502/467133.htm機器學習(Machine Learning)本質上就是讓計算機自己在數據中學習規律,并根據所得到的規律對未來數據進行預測。機器學習包括如聚類、分類、決策樹、貝葉斯、神經網絡、深度學習(Deep Learning)等算法。
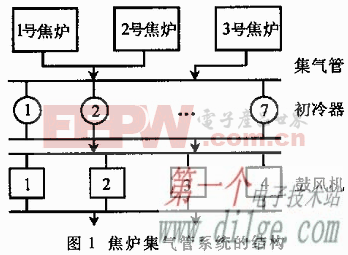
機器學習的基本思路是模仿人類學習行為的過程,如我們在現實中的新問題一般是通過經驗歸納,總結規律,從而預測未來的過程。機器學習的基本過程如下:

機器學習基本過程
機器學習發展簡史
從機器學習發展的過程上來說,其發展的時間軸如下所示:

機器學習發展歷程
從上世紀50年代的圖靈測試提出、塞繆爾開發的西洋跳棋程序,標志著機器學習正式進入發展期。
· 60年代中到70年代末的發展幾乎停滯。
· 80年代使用神經網絡反向傳播(BP)算法訓練的多參數線性規劃(MLP)理念的提出將機器學習帶入復興時期。
· 90年代提出的“決策樹”(ID3算法),再到后來的支持向量機(SVM)算法,將機器學習從知識驅動轉變為數據驅動的思路。
· 21世紀初Hinton提出深度學習(Deep Learning),使得機器學習研究又從低迷進入蓬勃發展期。
從2012年開始,隨著算力提升和海量訓練樣本的支持,深度學習(Deep Learning)成為機器學習研究熱點,并帶動了產業界的廣泛應用。
機器學習分類
機器學習經過幾十年的發展,衍生出了很多種分類方法,這里按學習模式的不同,可分為監督學習、半監督學習、無監督學習和強化學習。
監督學習
監督學習(Supervised Learning)是從有標簽的訓練數據中學習模型,然后對某個給定的新數據利用模型預測它的標簽。如果分類標簽精確度越高,則學習模型準確度越高,預測結果越精確。
監督學習主要用于回歸和分類。

常見的監督學習的回歸算法有線性回歸、回歸樹、K鄰近、Adaboost、神經網絡等;常見的監督學習的分類算法有樸素貝葉斯、決策樹、SVM、邏輯回歸、K鄰近、Adaboost、神經網絡等。
半監督學習
半監督學習(Semi-Supervised Learning)是利用少量標注數據和大量無標注數據進行學習的模式,側重于在有監督的分類算法中加入無標記樣本來實現半監督分類。
常見的半監督學習算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
無監督學習
無監督學習(Unsupervised Learning)是從未標注數據中尋找隱含結構的過程,主要用于關聯分析、聚類和降維。
常見的無監督學習算法有稀疏自編碼(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
強化學習
強化學習(Reinforcement Learning)類似于監督學習,但未使用樣本數據進行訓練,是通過不斷試錯進行學習的模式,常用于機器人避障、棋牌類游戲、廣告和推薦等應用場景中。
在強化學習中,有兩個可以進行交互的對象:智能體(Agnet)和環境(Environment),還有四個核心要素:策略(Policy)、回報函數(收益信號,Reward Function)、價值函數(Value Function)和環境模型(Environment Model),其中環境模型是可選的。
為了便于讀者理解,用灰色圓點代表沒有標簽的數據,其他顏色的圓點代表不同的類別有標簽數據。監督學習、半監督學習、無監督學習、強化學習的示意圖如下所示:

機器學習應用之道
機器學習是將現實中的問題抽象為數學模型,利用歷史數據對數據模型進行訓練,然后基于數據模型對新數據進行求解,并將結果再轉為現實問題的答案的過程。機器學習一般的應用實現步驟如下:
· 將現實問題抽象為數學問題
· 數據準備
· 選擇或創建模型
· 模型訓練及評估
· 預測結果

這里我們以Kaggle上的一個競賽Cats vs. Dogs(貓狗大戰)為例來進行簡單介紹,感興趣的可親自實驗。
1. 現實問題抽象為數學問題
現實問題:給定一張圖片,讓計算機判斷是貓還是狗?
數學問題:二分類問題,1表示分類結果是狗,0表示分類結果是貓。
2. 數據準備
下載kaggle貓狗數據集解壓后分為3個文件train.zip、test.zip和sample_submission.csv。
數據下載地址:https://www.kaggle.com/c/dogs-vs-cats
train訓練集包含了25000張貓狗的圖片,貓狗各一半,每張圖片包含圖片本身和圖片名。命名規則根據“type.num.jpg”方式命名。

訓練集示例
test測試集包含了12500張貓狗的圖片,沒有標定是貓還是狗,每張圖片命名規則根據“num.jpg”命名。

測試集示例
sample_submission.csv需要將最終測試集的測試結果寫入.csv文件中。

sample_submission示例
我們將數據分成3個部分:訓練集(60%)、驗證集(20%)、測試集(20%),用于后面的驗證和評估工作。

3. 選擇模型
機器學習有很多模型,需要選擇哪種模型,需要根據數據類型,樣本數量,問題本身綜合考慮。
如本問題主要是處理圖像數據,可以考慮使用卷積神經網絡(Convolutional Neural Network, CNN)模型來實現二分類,因為選擇CNN的優點之一在于避免了對圖像前期預處理過程(提取特征等)。
4. 模型訓練及評估
我們預先設定損失函數Loss計算得到的損失值,通過準確率Accuracy來評估訓練模型。損失函數LogLoss作為模型評價指標:


準確率(accuracy)來衡量算法預測結果的準確程度:

TP(True Positive)是將正類預測為正類的結果數目
FP(False Positive)是將負類預測為正類的結果數目
TN(True Negative)是將負類預測為負類的結果數目
FN(False Negative)是將正類預測為負類的結果數目

訓練過中的 loss 和 accuracy
5. 預測結果
訓練好的模型,我們載入一張圖片,進行識別,看看識別效果:

機器學習趨勢分析
機器學習正真開始研究和發展應該從80年代開始,我們借助AMiner平臺,將近些年機器學習論文進行統計分析所生成的發展趨勢圖如下所示:

可以看出,深度神經網絡(Deep Neural Network)、強化學習(Reinforcement Learning)、卷積神經網絡(Convolutional Neural Network)、循環神經網絡(Recurrent Neural Network)、生成模型(Generative Model)、圖像分類(Image Classification)、支持向量機(Support Vector Machine)、遷移學習(Transfer Learning)、主動學習(Active Learning)、特征提取(Feature Extraction)是機器學習的熱點研究。
以深度神經網絡、強化學習為代表的深度學習相關的技術研究熱度上升很快,近幾年仍然是研究熱點。




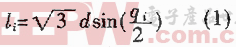
評論