使用移動端神經網絡實現實時弱光視頻增強

作者:Arm 戰略與生態部工程師 Ayaan Masood
本文引用地址:http://www.j9360.com/article/202411/464514.htm作為通訊工具,視頻會議幾乎隨處可見,尤其適用于遠程辦公和社交互動。但其使用體驗并非總是簡單直接、即開即用,可能需要進行調整,確保音頻視頻設置良好。其中,照明便是一個難以把握的因素。在會議中,光線充足的視頻畫面會顯得得體大方,而糟糕的照明條件則會顯得不夠專業,還會分散其他與會者的注意力。有時,改變光照情況并不可行,特別是在光線昏暗的冬季或照明不足的地點。
在本文中,我們將探討如何構建一個演示移動端應用,以解決弱光條件下的視頻照明問題。我們將介紹支持該應用的神經網絡模型及其機器學習 (ML) 管線、性能優化等。
找到合適的神經網絡
我們采用基于神經網絡的解決方案改善視頻照明。因此,這項工作的核心在于找到適合當前任務的神經網絡。目前,市面上有很多出色的開源模型可供使用,而為本項目找到合適的候選模型至關重要。我們在評估模型時主要關注以下三項要求:性能良好、照明質量出色、視頻處理表現優異。
我們的目標是實現移動端實時推理,這意味著,每幀處理時間只有嚴格控制在 33 毫秒內,才能實現每秒 30 幀的流暢播放。其中包括預處理/后處理步驟以及神經網絡運行所需的時間。視頻畫質增強是另一項重要標準。該模型可智能化增強暗像、還原細節,確保視頻幀之間暫時保持連貫,避免畫面閃爍。
模型架構
所選模型來自 2021 年研究論文《用于弱光圖像/視頻增強的語義引導零樣本學習》 [1] 。在包含混合曝光和照明條件的復雜數據集上進行測試時,該模型的弱光增強質量非常出色。暗像中不清晰的細節和結構突然變得清晰起來。該模型的另一個優點是尺寸極小,僅有一萬個網絡參數,因此推理速度很快。在模型架構方面,輸入的圖像張量被縮小并傳遞到卷積層棧。這些層會預測逐像素增強因子,然后在模型后處理模塊中,將增強因子以乘法方式應用到原始圖像像素上,從而生成增強的圖像。
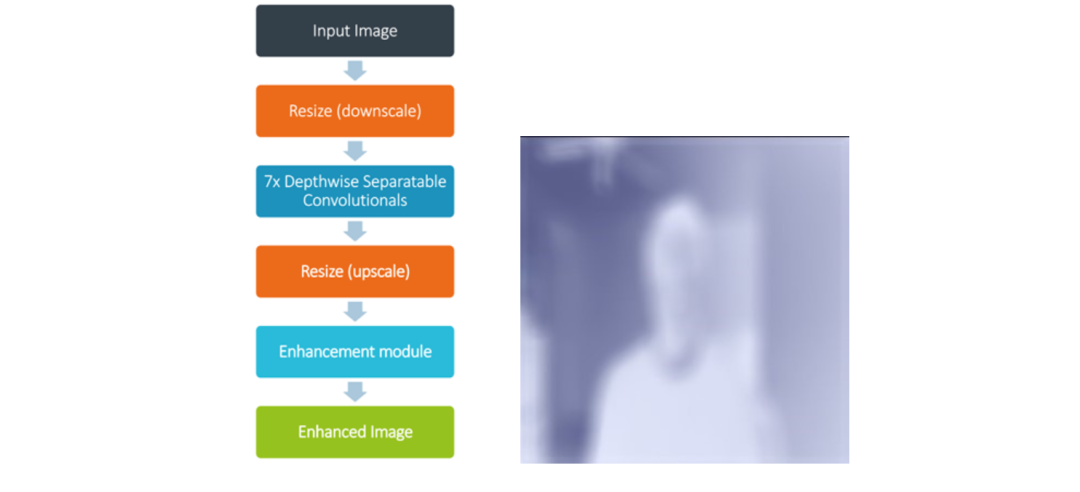
圖:模型架構和增強模塊可視化
值得一提的是,訓練采用包含兩千張合成圖像的小型數據集,這就表明,如果數據集規模更大,模型就還有更大提升空間。我們增強了真實參照圖像,生成一系列統一曝光值,從而調整圖像明暗。該模型的訓練不受監督,無需標簽,而是通過一個指導訓練的損失函數來學習如何增強弱光圖像。這個損失函數是多個獨立損失的組合,它們分別負責圖像的各個方面,如顏色、亮度和語義信息。
ML 管線
該應用的 ML 管線從輸入幀開始,根據模型輸入張量要求加以處理,然后推理并向用戶顯示輸出。攔截相機幀進行推理是 CameraX 庫的內置功能,通過安卓的“圖像分析”API 實現。
我們采用了兩種不同的 ML 推理引擎:ONNX runtime和 TensorFlow Lite。將 Pytorch 模型導出為 ONNX 模型是 Pytorch 庫自帶的功能,而導出到 TensorFlow Lite 則困難得多。該模型的有效導出器為 Nobuco,其工作機制是先創建可轉換為 TFLite 的 Keras 模型。
模型推理產生的輸出格式取決于 ML 運行時。如果采用 ONNX,則為 NCHW(即數量、通道、高度、寬度);如果采用 TFLite,則為 NHWC,其中通道排在末尾。這影響了后處理步驟的完成方式,即將整數 RGB 值的輸出緩沖區解包,以創建終末位圖,并顯示在屏幕上。
結果呈現
點擊圖片,查看弱光增強前后對比




<< 滑動解鎖更多示例 >>
性能優化
在 Kotlin 中將 RGBA 位圖轉換為 RGB 的計算成本很高。當性能預算限制在 33 毫秒以內時,僅轉換過程就需要花費幾十毫秒。為了加快速度,我們使用了 C++ 語言,并對編譯器進行了全面優化。但是,要從 Kotlin 代碼調用 C++ 代碼,就得用到 Java 原生接口 (JNI)。通過 JNI 傳遞一個 3x512x512 大小的浮點數緩沖區成本很高,因為必須復制兩次,先從 Kotlin 復制到 C++,處理完后再復制回 Kotlin。為了解決這個問題,我們使用了 Java 直接緩沖區。傳統緩沖區的內存由安卓運行時在堆上分配,C++ 不容易訪問。而直接緩沖區必須按照系統的正確字節順序分配,而一旦分配好了,內存就能以操作系統和 C++ 易于訪問的方式分配。這樣,我們就省去了復制到 JNI 的時間,并能夠利用高度優化的 C++ 代碼。
量化
該模型使用量化技術進行優化。量化就是使用較低精度表示神經網絡的權重和激活值,從而在略微犧牲模型質量的情況下提高推理速度。量化用的數據類型通常比較小,例如 INT8,它占用的空間只有原來 32 位浮點數 (FP32) 的四分之一。模型量化有兩種:動態量化和靜態量化。動態量化僅量化模型權重,并在運行時,針對激活值確定量化參數。靜態量化則事先使用代表性數據集量化權重和激活值,所以在推理方面更快。對于這個模型,靜態量化提高了推理速度,而輸出照明增強效果則略暗一些,這樣的取舍是值得的。
模型推理時間
圖:模型推理時間 Pixel 7
上圖比較了使用 ONNX runtime 和 TensorFlow Lite 對弱光增強模型進行模型推理的時間。在 Pixel 7 上的分辨率為 512x512。 我們先將 ONNX runtime 作為推理引擎。在 CPU 上運行時,FP32 的模型推理時間為 40 毫秒。當量化到 INT8 時,這一時間縮短到 32 毫秒。性能原本有望獲得大幅提升,但使用可視化工具 Netron 分析模型文件后發現,模型圖中增加了額外的量化/反量化算子,從而增加了計算開銷。使用 XNNPack 和 INT8 模型的 TensorFlow Lite 在 CPU 上的表現稍慢于 ONNX runtime,推理時間接近 70 毫秒。不過,TensorFlow Lite 在使用 GPU 處理時,超越了之前所有推理引擎和模型類型的組合。對于 512x512 輸入圖像的推理,TensorFlow Lite 僅需 11 毫秒,因此我們選擇它作為運行模型的后端,以實現實時照明增強。
安卓性能提示 API
想要重復對演示應用進行基準測試,就必須要用 ADB 命令來開啟安卓固定性能模式。這是因為每次測試時,CPU 的頻率可能會變來變去,ADB 命令可以固定 CPU 頻率。我們發現,在使用這種固定性能模式后,幀時間減少了。但這也讓應用開發者左右為難,因為他們沒法控制 CPU 頻率,但又不能指望終端用戶會使用 ADB。不過,安卓性能提示 API 可以解決這個問題。該 API 主要用于游戲,其工作原理是設定目標幀時間并將該指標報告回安卓系統,由安卓系統調整時鐘頻率,嘗試達到該目標。這使得幀時間得到了與固定性能模式相當的良好改善。
幀率
當弱光增強功能打開時,應用會顯示幀時序。盡管幀率約為 37 FPS,但攝像頭幀速率會根據硬件和照明情況受到限制(在極弱光條件下,安卓系統會降低相機 FPS 以提高亮度)。在 Pixel 7 上,向用戶顯示的幀速率(默認的安卓攝像頭 API)上限為 30 FPS。更快的推理并不會帶來更好的用戶體驗,因此保留了一個 7 FPS 的性能緩沖。
進一步的模型訓練
盡管原始模型在暗場景下的照明增強效果相當不錯,但圖像有時會出現過度曝光的情況。為了解決這個問題,我們采用了一個包含兩萬張合成圖像的大型數據集進行訓練,此前的研究論文僅使用了兩千張圖像。
不過,基于大型數據集的訓練時間會變長。經過調查,性能下降的原因是每批量八張圖像超出了 GPU VRAM 容量,并溢出到系統內存中。為了在不增加 VRAM 使用量的情況下提高有效批次大小,我們采用了梯度累積技術,無需針對每個批量計算梯度,而是累積多個批量后再計算梯度。在我們的案例中,我們可以使用的批量上限是六張圖像,而采用梯度累積技術后,我們能夠使用的批量是 60 張圖像。
結論
我們在本文中展示了一個可運行的演示移動端應用,用于實時改善移動端視頻的照明效果。基于 Arm 平臺優化并運行 ML 模型的過程非常順暢,得益于量化和各種推理引擎等技術的運用,該模型能夠在 33 毫秒的嚴苛性能限制下順利運行。









評論