DeepSeek引爆 AI,國產 GPU 集體撐腰

近日,想必諸多用戶都懷揣著這樣的疑惑:我的手機為何頻頻推送關于 DeepSeek 的資訊?這 DeepSeek 究竟是什么?它又為何能在問世之際,就引發如此熱烈的關注與轟動?
本文引用地址:http://www.j9360.com/article/202502/466733.htmDeepSeek,全稱杭州深度求索人工智能基礎技術研究有限公司,其起源于一家中國的對沖基金公司 High-Flyer。2023 年 5 月 High-Flyer 剝離出一個獨立實體,也就是 DeepSeek。這是一家致力于打造高性能、低成本的 AI 模型。它的目標是讓 AI 技術更加普惠,讓更多人能夠用上強大的 AI 工具。
DeepSeek-V3 與 DeepSeek-R1 的核心差異
去年 12 月 26 日,DeepSeek AI 正式發布了其最新的大型語言模型 DeepSeek-V3。這款開源模型采用了高達 6710 億參數的 MoE 架構,每秒能夠處理 60 個 token,比 V2 快了 3 倍。一經發布,就在 AI 領域引起了軒然大波。
時隔不足一個月,在今年 1 月 20 日,深度求索又正式發布推理大模型 DeepSeek-R1。DeepSeek-R1 的發布,再次震撼業界!
1 月 27 日,DeepSeek 應用登頂蘋果中國區和美國區應用商店免費 App 下載排行榜。1 月 31 日,英偉達、亞馬遜和微軟這三家美國科技巨頭,在同一天宣布接入 DeepSeek-R1。
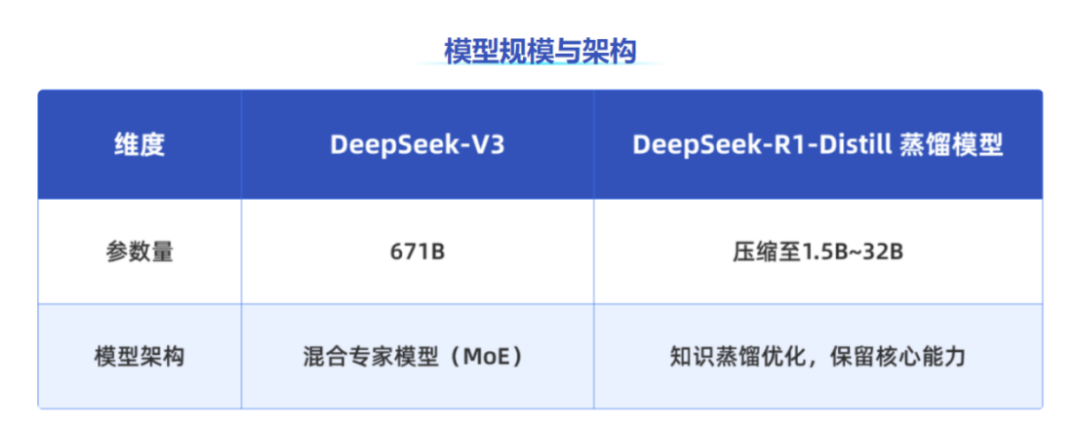
關于 DeepSeek-V3 與 DeepSeek-R1-Distill 蒸餾模型的區別:
DeepSeek-V3
適合復雜任務處理和高精度場景,如長文檔分析、多模態推理、科研計算等。
支持千卡級訓練,滿足超大規模集群分布式訓練需求。
DeepSeek-R1-Distill 蒸餾模型
適合輕量級部署和資源受限場景,如邊緣設備推理、中小企業快速驗證 AI 應用。
在顯存和算力要求上更為靈活,適配入門級硬件。
來源:Gitee AI
近日,硅谷頂尖風險投資家、a16Z 聯合創始人 Marc Andreessen 發文引用 SensorTower 數據:目前 DeepSeek 日活用戶數已經達到了 ChatGPT 的 23%,并且應用每日下載量接近 500 萬。
2 月 5 日,京東云宣布正式上線 DeepSeek-R1 和 DeepSeek-V3 模型,支持公有云在線部署、專混私有化實例部署兩種模式。前幾日,阿里云、百度智能云、華為云、騰訊云、火山引擎、天翼云已接入了 DeepSeek 模型。海外的亞馬遜 AWS、微軟 Azure 等云巨頭同樣官宣支持。
那么,DeepSeek 究竟是以何種獨特魅力,贏得了廣大用戶的青睞與喜愛呢?
DeepSeek 的兩大優勢
市場熱捧的產品,往往有個顯著共性:能幫用戶降本增效。這,同樣是 DeepSeek 的優勢所在。
首先在低成本與高效能方面,DeepSeek-V3 的訓練成本僅為 557.6 萬美元(約為 GPT-4 的二十分之一),卻能在邏輯推理、代碼生成等任務中達到與 GPT-4o、Claude-3.5-Sonnet 相近的性能,甚至超越部分開源模型(如 Llama-3.1-405B)。其技術核心在于算法優化(如 MoE 架構、動態學習率調度器)和數據效率提升,而非依賴算力堆疊。
作為對比,GPT-5 一次為期 6 個月的訓練僅計算成本就高達約 5 億美元。
其次,開源與靈活部署也是 DeepSeek 的突出優勢之一。DeepSeek 選擇將模型權重開源,并公開訓練細節,這為全球的 AI 研究者打開了一扇通往模型內部的大門,讓他們能夠深入了解模型的訓練過程、所采用的算法以及遇到的問題和解決方案。
360 集團創始人周鴻祎指出,DeepSeek 真正踐行了開放的精神。與 OpenAI 等關閉模式平臺相比,DeepSeek 允許開發者利用其開源模型進行技術挖掘和創新,這是對技術共享理念的有力支持。OpenAI 雖然以「開源」自居,但隨著商業化的推進,越來越多地選擇封閉式策略,這與其創立初衷背道而馳。
此外,周鴻祎特別提到 DeepSeek 的模型蒸餾技術,他認為這是一種極具前瞻性的實踐。在他看來,DeepSeek 對模型蒸餾的開放態度,展示了其自信與無私。相較之下,OpenAI 對用戶蒸餾其模型的限制,顯示出其對競爭對手的排斥和對自身優勢的維護。
DeepSeek 所需的 GPU,主要來源于英偉達
早期對 AI 技術和硬件基礎設施的戰略投資,為 DeepSeek 的成功奠定了基礎。
據 SemiAnalysis 評估,DeepSeek 擁有大約 50,000 個 Hopper 架構的 GPU,其中包括 10,000 個 H800 和 10,000 個 H100 型號。此外,他們還訂購了大量的 H20 型號 GPU,這些 GPU 專為中國市場設計。盡管 H800 與 H100 具有相同的計算能力,但其網絡帶寬較低。H20 是當前唯一對中國模型提供商可用的型號。這些 GPU 不僅用于 DeepSeek,也服務于 High-Flyer,地理上分散部署,支持交易、推理、訓練和研究等多種任務。
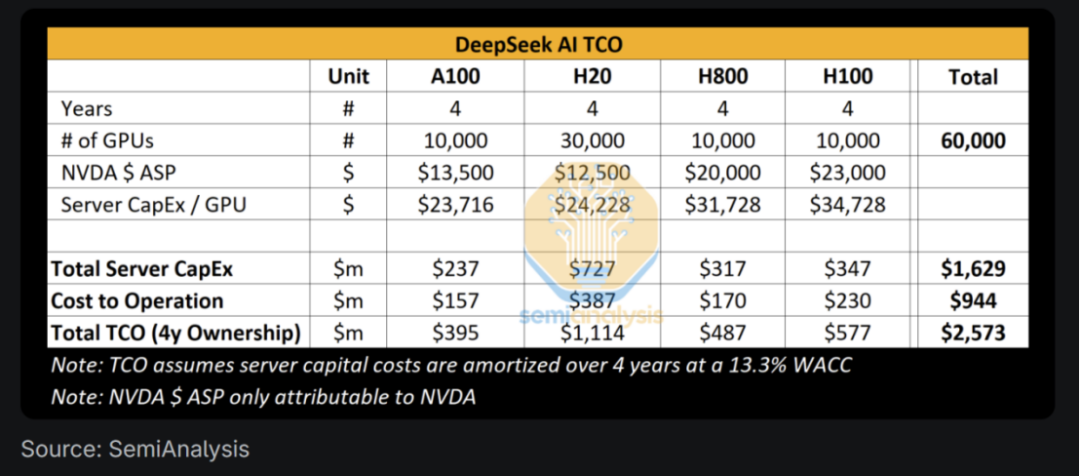
至于 DeepSeek 如何獲得如此多數量的 Hopper GPU。
早在 2021 年 High-Flyer 就看好 AI 的發展潛力并果斷投資購買了 10,000 個 A100 GPU,用于大規模模型訓練實驗。這項戰略決策后來被證明是非常成功的,為公司帶來了顯著的競爭優勢。
在 1 月 25 日新年前,AMD 就官宣將 DeepSeek-V3 模型集成到了 Instinct MI300X GPU 上。
隨后在 1 月 31 日,AI 芯片龍頭英偉達也官宣其 NVIDIA NIM 微服務預覽版對于 DeepSeek-R1 模型的支持。NIM 微服務基于 HGX H200 系統,每秒能夠處理 3872 個 tokens。開發者們可以調用 API 進行測試和試驗,該 API 后續會作為英偉達 AI 企業軟件平臺的一部分提供。
同日,英特爾宣布 DeepSeek 能夠在搭載酷睿處理器的 AI PC 上離線使用。在酷睿 Ultra 200H(Arrow Lake H)平臺上,DeepSeek-R1-1.5B 模型能夠本地離線運行,做翻譯、做會議紀要、進行文檔撰寫等任務。
要知道 DeepSeek 在算力芯片受限的不利因素下,達到 OpenAI 等頂級模型的水平,是國內 AI 生態級的突破。如今,隨著 DeepSeek 這類模型的發展,對 GPU 需求持續攀升。國產 GPU 廠商也敏銳捕捉到這一機遇,正在積極進行適配工作。他們深知,適配成功不僅能助力 DeepSeek 等模型更好地發展,也能為自身打開更廣闊的市場空間,提升國產 GPU 在 AI 領域的影響力。
11 大國產 AI 芯片公司,宣布適配 DeepSeek
僅在 2 月 1 日至 2 月 7 日這短短 7 天內,就有 11 家國產 AI 芯片公司宣布完成對 DeepSeek 的適配。
DeepSeek 系列新模型正式上線昇騰社區
2 月 1 日,華為云宣布與硅基流動聯合首發并上線基于華為云昇騰云服務的 DeepSeek R1/V3 推理服務。得益于自研推理加速引擎加持,該服務支持部署的 DeepSeek 模型可獲得持平全球高端 GPU 部署模型的效果。
2 月 5 日,華為宣布,DeepSeek-R1、DeepSeek-V3、DeepSeek-V2、Janus-Pro 于 2 月 4 日正式上線昇騰社區,支持一鍵獲取 DeepSeek 系列模型,支持昇騰硬件平臺上開箱即用,推理快速部署,帶來更快、更高效、更便捷的 AI 開發和應用體驗。
摩爾線程實現對 DeepSeek 蒸餾模型推理服務的高效部署
2 月 4 日,摩爾線程發文稱已快速實現對 DeepSeek 蒸餾模型推理服務的高效部署,旨在賦能更多開發者基于摩爾線程全功能 GPU 進行 AI 應用創新。

此外,用戶也可以基于 MTT S80 和 MTT S4000 進行 DeepSeek-R1 蒸餾模型的推理部署。
通過 DeepSeek 提供的蒸餾模型,能夠將大規模模型的能力遷移至更小、更高效的版本,在國產 GPU 上實現高性能推理。摩爾線程基于自研全功能 GPU,通過開源與自研雙引擎方案,快速實現了對 DeepSeek 蒸餾模型的推理服務部署,為用戶和社區提供高質量服務。
DeepSeek V3 和 R1 模型完成海光 DCU 適配并正式上線
2 月 4 日晚間,海光信息宣布公司技術團隊成功完成 DeepSeek V3 和 R1 模型與海光 DCU(深度計算單元)的適配,并正式上線。
DeepSeek V3 和 R1 模型采用了 Multi-Head Latent Attention(MLA)、DeepSeekMoE、多令牌預測、FP8 混合精度訓練等創新技術,顯著提升了模型的訓練效率和推理性能。
DCU 是海光信息推出的高性能 GPGPU 架構 AI 加速卡,致力于為行業客戶提供自主可控的全精度通用 AI 加速計算解決方案。憑借卓越的算力性能和完備的軟件生態,DCU 已在科教、金融、醫療、政務、智算中心等多個領域實現規模化應用。
隨著海光等專注于 GPU 研發的公司紛紛表示已完成對 DeepSeek V3 的適配。從這一現象來看,DeepSeek 模型在業界或許正逐漸獲得較高的認可度與通用性。
那么,海光 DCU 的哪些硬件特性和架構設計使得它能夠很好地支持 DeepSeek V3 和 R1 模型的高效運行?
有業內人士表示,海光 DCU 采用了 GPGPU 架構,從而保證在面對新型應用的時候具備極好的兼容性與適配性;同時 DCU 配套的軟件棧也經過了多年的積累,相應軟件生態成熟豐富,在與新模型、應用適配的時候具備完備的軟件支撐能力。以上共同保障了對于 DeepSeek V3/R1 為代表的新模型能夠提供高效的兼容與支撐能力。
值得注意的是,海光本次適配并沒有用到額外的中間層工具,依托現有 DCU 軟件棧就可以實現快速的支撐。這主要得益于 DCU 的 GPGPU 架構通用性和自身對主流生態的良好兼容,從而大幅提升了大模型等人工智能應用的部署效率。
天數智芯聯合 Gitee AI 正式上線 DeepSeek R1 模型服務
2 月 4 日,天數智芯與 Gitee AI 聯合發布消息,在雙方的高效協作下,僅用時一天,便成功完成了與 DeepSeek R1 的適配工作,并且已正式上線多款大模型服務,其中包括 DeepSeek R1-Distill-Qwen-1.5B、DeepSeek R1-Distill-Qwen-7B、DeepSeek R1-Distill-Qwen-14B 等。
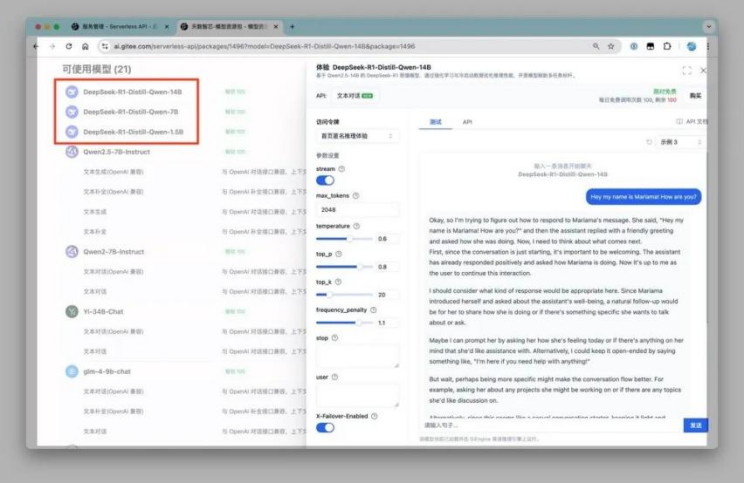
Gitee AI 與沐曦攜手首發 DeepSeek R1 系列千問蒸餾模型
2 月 2 日,Gitee AI 正式推出了四個輕量級版本的 DeepSeek 模型,分別為 DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-14B 和 DeepSeek-R1-Distill-Qwen-32B。尤為引人注目的是,這些模型均部署在國產沐曦曦云 GPU 上。
上文曾提到,與全尺寸 DeepSeek 模型相比,較小尺寸的 DeepSeek 蒸餾版本模型更適合企業內部實施部署,可以降低落地成本。
同時,這次 Deepseek R1 模型 + 沐曦曦云 GPU + Gitee AI 平臺,更是實現了從芯片到平臺,從算力到模型全國產研發。

隨后在 2 月 5 日 Gitee AI 宣布再次將 DeepSeek-V3 滿血版(671B)上線到平臺上(滿血版目前僅供大家體驗用途)。這也是 Gitee AI 繼全套千問蒸餾模型上線沐曦 GPU 卡之后的又一大的更新。
壁仞 AI 算力平臺上線 DeepSeek R1 蒸餾模型推理服務,支持云端體驗
2 月 5 日,壁仞科技宣布,憑借自主研發的壁礪系列 GPU 產品出色的兼容性能,只用數個小時,就完成對 DeepSeek R1 全系列蒸餾模型的支持,涵蓋從 1.5B 到 70B 各等級參數版本,包括 LLaMA 蒸餾模型和千問蒸餾模型。
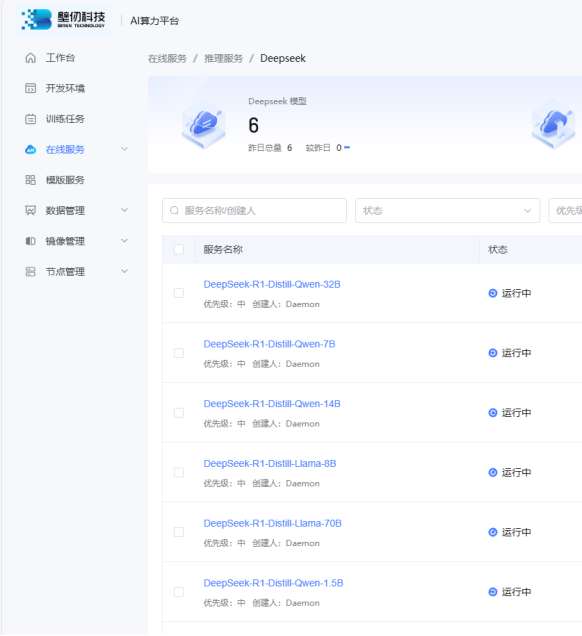
目前,壁仞科技已構建起從底層硬件到模型服務的完整 AI 技術棧,可為中小企業和研究機構提供「芯片+模型」的端到端解決方案。
云天勵飛 DeepEdge10 已完成 DeepSeek R1 系列模型適配
2 月 5 日,云天勵飛宣布,其芯片團隊完成 DeepEdge10「算力積木」芯片平臺與 DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B 大模型的適配,可以交付客戶使用。DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B 大模型、DeepSeek V3/R1 671B MoE 大模型也在有序適配中。適配完成后,DeepEdge10 芯片平臺將在端、邊、云全面支持 DeepSeek 全系列模型。
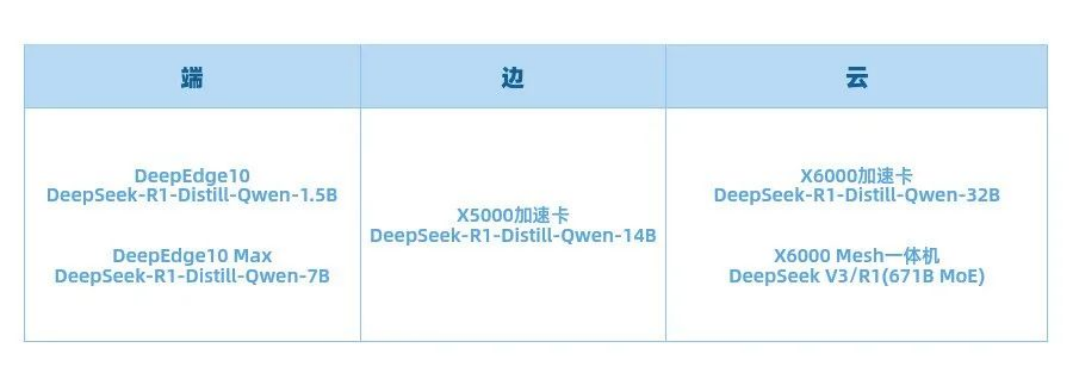

DeepEdge10 系列芯片是專門針對大模型時代打造的芯片,支持包括 Transformer 模型、BEV 模型、CV 大模型、LLM 大模型等各類不同架構的主流模型;基于自主可控的先進國產工藝打造,采用獨特的「算力積木」架構,可靈活滿足不同場景對算力的需求,為大模型推理提供強大動力。
基于太初 T100 加速卡 2 小時適配 DeepSeek-R1 系列模型
2 月 5 日,太初元碁 Tecorigin 表示,基于通用的異構眾核芯片架構和深厚的軟件生態積累,在太初 T100 加速卡上僅用 2 小時便完成 DeepSeek-R1 系列模型的適配工作,快速上線包括 DeepSeek-R1-Distill-Qwen-7B 在內的多款大模型服務,為人工智能應用的創新發展提供了強有力的技術支撐和自動可控的算力設施保障。
目前,太初元碁正積極攜手京算、是石科技、神威數智、龍芯中科等合作伙伴,全力打造 DeepSeek 系列模型的云端推理平臺。企業用戶只需通過簡單的操作,即可在云端快速獲取太初 T100 加速卡的強大推理能力,輕松實現智能化轉型,提升生產效率和創新能力,以在激烈的市場競爭中脫穎而出。同時,太初元碁也聯合龍芯中科提供面向政務信創的國密云端推理平臺,以滿足信創剛需。
燧原科技實現全國各地智算中心 DeepSeek 的全量推理服務部署
2 月 6 日,燧原科技宣布完成對 DeepSeek 全量模型的高效適配,包括 DeepSeek-R1/V3 671B 原生模型、DeepSeek-R1-Distill-Qwen-1.5B/7B/14B/32B、DeepSeek R1-Distill-Llama-8B/70B 等蒸餾模型。整個適配進程中,燧原 AI 加速卡的計算能力得到充分利用,能夠快速處理海量數據,同時其穩定性為模型的持續優化和大規模部署提供了堅實的基礎。
目前,DeepSeek 的全量模型已在慶陽、無錫、成都等智算中心完成了數萬卡的快速部署,將為客戶及合作伙伴提供高性能計算資源,提升模型推理效率,同時降低使用門檻,大幅節省硬件成本。
昆侖芯全面適配 DeepSeek
2 月 6 日,昆侖芯科技宣布,在 DeepSeek-V3/R1 上線不久,昆侖芯便率先完成全版本模型適配,這其中包括 DeepSeek MoE 模型及其蒸餾的 Llama/Qwen 等小規模 dense 模型。
昆侖芯 P800 可以較好的支撐 DeepSeek 系列 MoE 模型大規模訓練任務,全面支持 MLA、多專家并行等特性,僅需 32 臺即可支持模型全參訓練,高效完成模型持續訓練和微調。
P800 顯存規格優于同類主流 GPU20%-50%,對 MoE 架構更加友好,且率先支持 8bit 推理,單機 8 卡即可運行 671B 模型。正因如此,昆侖芯相較同類產品更加易于部署,同時可顯著降低運行成本,輕松完成 DeepSeek-V3/R1 全版本推理任務。
龍芯處理器成功運行 DeepSeek 大模型
2 月 7 日,龍芯中科宣布,日前,龍芯聯合太初元碁等產業伙伴,僅用 2 小時即在太初 T100 加速卡上完成 DeepSeek-R1 系列模型的適配工作,快速上線包含 DeepSeek-R1-Distill-Qwen-7B 在內的多款大模型服務。
此外,采用龍芯 3A6000 處理器的誠邁信創電腦和望龍電腦已實現本地部署 DeepSeek,部署后無需依賴云端服務器,避免了因網絡波動或服務器過載導致的服務中斷,可高效完成文檔處理、數據分析、內容創作等多項工作,顯著提升工作效率。
DeepSeek 給國產芯片公司,帶來新契機
DeepSeek 的橫空出世宛如一顆投入平靜湖面的石子,在行業中激起層層漣漪,為國產芯片公司帶來新的發展契機。
首先,隨著大模型應用的遍地開花,對芯片的需求也水漲船高。無論是模型訓練時所需的強大算力,還是推理過程中對低延遲、高效率的追求,都為國產芯片公司打開了新的市場空間。以往,由于高昂的大模型使用成本,許多潛在的應用場景被抑制,如今 DeepSeek 打破了這一僵局,國產芯片公司得以憑借自身產品在新興的細分市場中嶄露頭角,滿足不同行業對于大模型運算的芯片需求。
其次,DeepSeek 大模型與國產 AI 芯片適配的逐步成熟,是另一個關鍵契機。此前,國產 AI 芯片在發展過程中,常面臨與主流大模型適配度不佳的問題,這限制了其市場推廣與應用拓展。而 DeepSeek 的出現改變了這一局面,它為國產 AI 芯片提供了一個更為契合的適配平臺。
當國產 AI 芯片能夠與 DeepSeek 大模型良好適配后,可以加快國產 AI 芯片在國內大模型訓練端和推理端的應用,使得國產芯片在本土市場中獲得更多實踐機會,通過不斷優化和改進,提升產品性能。
最后,隨著 DeepSeek 與國產芯片的適配,將與其他國產軟硬件廠商形成協同效應,構建起完整的生態閉環,這將推動國產芯片在人工智能領域的應用,加速國產芯片生態體系的建設。

評論