Nvidia 征服了最新的 AI 測試

多年來,英偉達在許多機器學習基準測試中占據主導地位,現在它又多了兩個檔次。
MLPerf,有時被稱為“機器學習的奧林匹克”的人工智能基準測試套件,已經發布了一套新的訓練測試,以幫助在競爭計算機系統之間進行更多更好的同類比較。MLPerf 的一項新測試涉及對大型語言模型的微調,該過程采用現有的訓練模型,并用專業知識對其進行更多訓練,使其適合特定目的。另一個是圖神經網絡,一種機器學習,一些文獻數據庫背后的一種機器學習,金融系統中的欺詐檢測,以及社交網絡。
即使使用谷歌和英特爾的人工智能加速器的計算機增加和參與,由英偉達的Hopper架構驅動的系統再次主導了結果。一個包含 11,616 個 Nvidia H100 GPU 的系統(迄今為止最大的集合)在九個基準測試中名列前茅,其中五個(包括兩個新基準測試)創下了記錄。
“如果你只是把硬件扔到這個問題上,你就不能肯定地要改進。—DAVE SALVATOR,英偉達
11,616-H100系統是“我們做過的最大系統”,英偉達加速計算產品總監Dave Salvator說。它在不到 3.5 分鐘的時間內就完成了 GPT-3 訓練試驗。相比之下,512 GPU 系統大約需要 51 分鐘。(請注意,GPT-3 任務不是完整的訓練,可能需要數周時間并花費數百萬美元。取而代之的是,計算機在完成之前在商定的點上對數據的代表性部分進行訓練。
與英偉達去年在 GPT-3 上最大的參賽者——一臺 3,584 臺 H100 計算機相比,3.5 分鐘的結果代表了 3.2 倍的改進。你可能會從這些系統大小的差異中預料到這一點,但在人工智能計算中,情況并非總是如此,Salvator解釋說。“如果你只是把硬件扔到這個問題上,你就不能肯定地要改進,”他說。
“我們基本上是線性擴展的,”Salvator 說。他的意思是,兩倍的 GPU 會導致訓練時間減半。“[這]代表了我們工程團隊的一項偉大成就,”他補充道。
競爭對手也越來越接近線性縮放。這一輪英特爾部署了一個使用 1,024 個 GPU 的系統,該系統在 67 分鐘內執行了 GPT-3 任務,而計算機的大小僅為六個月前 224 分鐘的四分之一。谷歌最大的 GPT-3 條目使用了 12 倍的 TPU v5p 加速器作為其最小條目,執行任務的速度是其 9 倍。
Salvator 說,線性擴展對于即將擁有 100,000 個或更多 GPU 的“AI 工廠”尤為重要。他表示,預計今年將有一個這樣的數據中心上線,另一個使用英偉達的下一個架構Blackwell的數據中心將在2025年啟動。
英偉達的連勝勢頭仍在繼續
盡管使用與去年訓練結果相同的架構 Hopper,Nvidia 仍繼續延長訓練時間。這一切都歸功于軟件的改進,Salvator 說。“通常,在新架構發布后,我們會從軟件中獲得 2-2.5 倍的 [提升],”他說。
對于 GPT-3 訓練,Nvidia 比 2023 年 6 月的 MLPerf 基準測試提高了 27%。Salvator說,在提升的背后有幾個軟件變化。例如,Nvidia 工程師通過修剪 8 位和 16 位數字之間不必要的轉換,并更好地確定神經網絡的哪些層可以使用較低精度的數字格式,調整了 Hopper 對不太準確的 8 位浮點運算的使用。他們還找到了一種更智能的方法來調整每個芯片計算引擎的功率預算,并加快了GPU之間的通信速度,Salvator將其比作“在烤面包機中涂黃油”。
此外,該公司還實施了一項稱為“閃光關注”的計劃。閃速注意力是由Samba Nova創始人Chris Re在斯坦福大學實驗室發明的,是一種通過最大限度地減少對內存的寫入來加速Transformer網絡的算法。當它首次出現在 MLPerf 基準測試中時,閃光注意力比訓練時間縮短了 10%。(英特爾也使用了 flash attention 的一個版本,但不是 GPT-3。相反,它將該算法用于其中一個新基準測試,即微調。
與 2023 年 11 月提交的相比,使用其他軟件和網絡技巧,Nvidia 在文本到圖像測試 Stable Diffusion 中實現了 80% 的加速。
新基準
MLPerf 添加了新的基準并升級了舊的基準,以保持與 AI 行業正在發生的事情相關。今年增加了微調和圖神經網絡。
微調需要已經訓練過的 LLM,并將其專門用于特定領域。例如,英偉達(Nvidia)采用了一個經過訓練的430億參數模型,并在GPU制造商的設計文件和文檔上對其進行了訓練,以創建ChipNeMo,這是一種旨在提高其芯片設計人員生產力的AI。當時,該公司的首席技術官比爾·達利(Bill Dally)表示,培訓法學碩士就像給它提供文科教育,而微調就像把它送到研究生院。
MLPerf 基準測試采用預訓練的 Llama-2-70B 模型,并要求系統使用政府文檔數據集對其進行微調,以生成更準確的文檔摘要。
有幾種方法可以進行微調。MLPerf 選擇了一種稱為低秩適應 (LoRA) 的方法。據該組織稱,該方法最終只訓練了 LLM 參數的一小部分,與其他方法相比,硬件負擔降低了 3 倍,內存和存儲的使用量減少了 3 倍。
另一個新的基準測試涉及圖神經網絡(GNN)。這些是針對可以由一組非常大的互連節點表示的問題,例如社交網絡或推薦系統。與其他 AI 任務相比,GNN 需要計算機中節點之間的大量通信。
該基準測試在一個數據庫上訓練了 GNN,該數據庫顯示了學術作者、論文和機構之間的關系——一個具有 5.47 億個節點和 58 億條邊的圖形。然后對神經網絡進行訓練,以預測圖中每個節點的正確標簽。
未來的戰斗
2025 年的訓練輪可能會看到比較 AMD、英特爾和 Nvidia 的新加速器的正面交鋒。AMD 的 MI300 系列大約在六個月前推出,計劃于 2024 年底對 MI325x 進行內存增強升級,下一代 MI350 計劃于 2025 年推出。英特爾表示,今年晚些時候向計算機制造商推出的Gaudi 3將出現在MLPerf即將推出的推理基準測試中。英特爾高管表示,新芯片有能力在訓練LLM時擊敗H100。但勝利可能是短暫的,因為英偉達已經推出了一種新的架構Blackwell,該架構計劃于今年晚些時候推出。






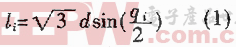



評論