2080億晶體管,英偉達推出最強AI芯片GB200

目前,英偉達位居人工智能世界之巔,擁有人人都想要的數據中心 GPU。其 Hopper H100 和 GH200 Grace Hopper 超級芯片需求量很大,為世界上許多最強大的超級計算機提供動力。
本文引用地址:http://www.j9360.com/article/202403/456553.htm今天,首席執行官黃仁勛投下了 Blackwell B200 炸彈,這是下一代數據中心和 AI GPU,將提供計算能力的巨大代際飛躍。
Blackwell 架構和 B200 GPU 取代了 H100/H200。Blackwell 包含三個部分:B100、B200 和 Grace-Blackwell Superchip (GB200)。
新一代人工智能芯片 BLACKWELL GPU

新的 B200 GPU 擁有 2080 億個晶體管,可提供高達 20petaflops 的 FP4 算力,而 GB200 將兩個 GPU 和一個 Grace CPU 結合在一起,可為 LLM 推理工作負載提供 30 倍的性能,同時還可能大大提高效率。英偉達表示,與 H100 相比,它的成本和能耗"最多可降低 25 倍"。
英偉達聲稱,訓練一個 1.8 萬億個參數的模型以前需要 8000 個 Hopper GPU 和 15 兆瓦的電力。如今,2000 個 Blackwell GPU 就能完成這項工作,耗電量僅為 4 兆瓦。
在具有 1750 億個參數的 GPT-3 LLM 基準測試中,GB200 的性能是 H100 的 7 倍,而英偉達稱其訓練速度是 H100 的 4 倍。
Blackwell B200 并不是傳統意義上的單一 GPU。相反,它由兩個緊密耦合的芯片組成,盡管根據英偉達的說法,它們確實充當一個統一的 CUDA GPU。這兩個芯片通過 10 TB/s NV-HBI(英偉達高帶寬接口)連接進行連接,以確保它們能夠作為單個完全一致的芯片正常運行。
這種雙芯片配置的原因很簡單:Blackwell B200 將使用臺積電的 4NP 工藝節點,這是現有 Hopper H100 和 Ada Lovelace 架構 GPU 使用的 4N 工藝的改進版本。

B200 將使用兩個全標線尺寸的芯片,每個芯片都有四個 HMB3e 堆棧,每個堆棧容量為 24GB,每個堆棧在 1024 位接口上具有 1 TB/s 的帶寬。
英偉達 NVLINK 7.2T
AI 和 HPC 工作負載的一大限制因素是不同節點之間通信的多節點互連帶寬。隨著 GPU 數量的增加,通信成為嚴重的瓶頸,占用的資源和時間高達 60%。通過 B200,英偉達推出了第五代 NVLink 和 NVLink Switch 7.2T。
新的 NVLink 芯片具有 1.8 TB/s 的全對全雙向帶寬,支持 576 個 GPU NVLink 域。它是在同一臺積電 4NP 節點上制造的 500 億個晶體管芯片。該芯片還支持 3.6 teraflops 的 Sharp v4 片上網絡計算,這有助于高效處理更大的模型。

上一代支持高達 100 GB/s 的 HDR InfiniBand 帶寬,因此這是帶寬的巨大飛躍。與 H100 多節點互連相比,新的 NVSwitch 速度提高了 18 倍。這應該能夠顯著改善更大的萬億參數模型人工智能網絡的擴展性。
與此相關的是,每個 Blackwell GPU 都配備了 18 個第五代 NVLink 連接。這是 H100 鏈接數量的十八倍。每個鏈路提供 50 GB/s 的雙向帶寬,或每個鏈路 100 GB/s
英偉達 B200 NVL72

將以上內容組合在一起,您就得到了英偉達的新 GB200 NVL72 系統。
這些基本上是一個全機架解決方案,具有 18 臺 1U 服務器,每臺服務器都有兩個 GB200 超級芯片。然而,在 GB200 超級芯片的構成方面,與上一代相比存在一些差異。圖像和規格表明,兩個 B200 GPU 與單個 Grace CPU 相匹配,而 GH100 使用較小的解決方案,將單個 Grace CPU 與單個 H100 GPU 放在一起。
最終結果是 GB200 超級芯片計算托盤將配備兩個 Grace CPU 和四個 B200 GPU,具有 80 petaflops 的 FP4 AI 推理性能和 40 petaflops 的 FP8 AI 訓練性能。這些是液冷 1U 服務器,它們占據了機架中提供的典型 42 個單位空間的很大一部分。
除了 GB200 超級芯片計算托盤外,GB200 NVL72 還將配備 NVLink 交換機托盤。這些也是 1U 液冷托盤,每個托盤有兩個 NVLink 交換機,每個機架有 9 個這樣的托盤。每個托盤提供 14.4 TB/s 的總帶寬,加上前面提到的 Sharp v4 計算。
總的來說,GB200 NVL72 擁有 36 個 Grace CPU 和 72 個 Blackwell GPU,具有 720 petaflops 的 FP8 和 1,440 petaflops 的 FP4 計算能力。多節點帶寬為 130 TB/s,英偉達表示 NVL72 可以為 AI LLM 處理多達 27 萬億個參數模型。
英偉達表示,亞馬遜、Google、微軟和甲骨文都已計劃在其云服務產品中提供 NVL72 機架。
Blackwell 平臺表現如何?
雖然英偉達在人工智能基礎設施市場占據主導地位,但它并不是唯一一家在行動的公司,英特爾和 AMD 推出新的 Gaudi 和 Instinct 加速器、云提供商推動定制芯片,以及像 Cerebras 和 Samba Nova 這樣的人工智能初創公司都在爭奪 AI 市場的一杯羹。
預計到 2024 年,人工智能加速器的需求將遠遠超過供應,贏得份額并不總是意味著擁有更快的芯片,而僅僅意味著擁有可交付的芯片。
雖然我們對英特爾即將推出的 Guadi 3 芯片還知之甚少,但我們可以將其與 AMD 去年 12 月推出的 MI300X GPU 進行一些比較。
MI300X 使用先進的封裝將八個 CDNA 3 計算單元垂直堆疊到四個 I/O 芯片上,從而在 GPU 和 192GB HBM3 內存之間提供高速通信。
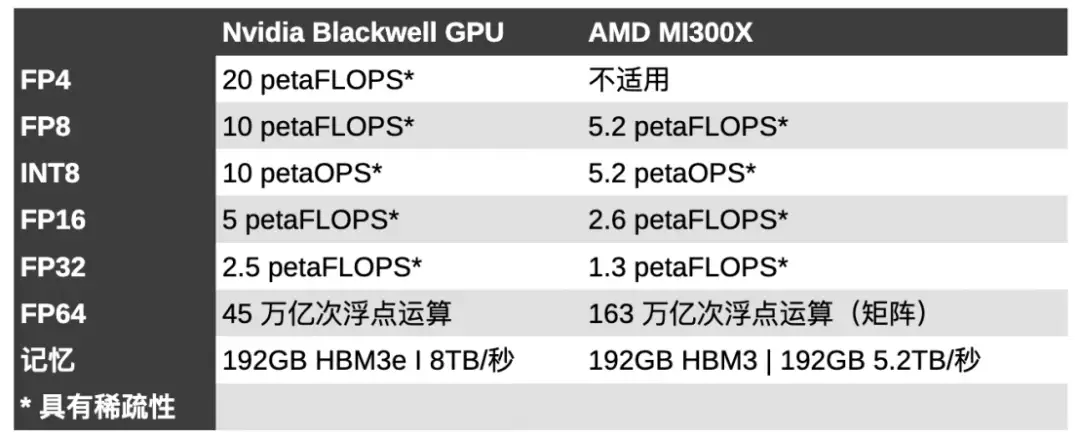
在性能方面,與英偉達的 H100 相比,MI300X 在 FP8 浮點計算方面具有 30% 的性能優勢,在以 HPC 為中心的雙精度工作負載方面具有近 2.5 倍的領先優勢。
將 750W MI300X 與 700W B100 進行比較,英偉達芯片的稀疏性能快了 2.67 倍。雖然這兩款芯片現在都配備了 192 GB 高帶寬內存,但 Blackwell 部分的內存速度快了 2.8 TB/s。
內存帶寬已被證明是人工智能性能的主要指標,特別是在推理方面。英偉達的 H200 本質上是帶寬增強的 H100。然而,盡管與 H100 的 FLOPS 相同,英偉達聲稱在 Meta 的 Llama 2 70B 等模型中速度是 H100 的兩倍。
雖然英偉達在較低精度方面擁有明顯領先優勢,但這可能是以犧牲雙精度性能為代價的,而雙精度性能是 AMD 近年來表現出色的領域,贏得了多個備受矚目的超級計算機獎項。
據英偉達稱,Blackwell GPU 能夠提供 45 teraFLOPS 的 FP64 張量核心性能。這與 H100 提供的 67 teraFLOPS FP64 矩陣性能相比略有下降,并且與 AMD 的 MI300X(81.7 teraFLOPS FP64 矢量和 163 teraFLOPS FP64 矩陣)相比處于劣勢。
還有 Cerebras,它最近展示了其第三代 Waferscale AI 加速器。怪物 90 萬核心處理器只有餐盤大小,專為 AI 訓練而設計。
Cerebras 聲稱這些芯片中的每一個都可以在 23kW 的功率下實現 125 petaFLOPS 的高度稀疏 FP16 性能。Cerebras 表示,與 H100 相比,該芯片在半精度下速度快了約 62 倍。
然而,將 WSE-3 與英偉達的旗艦 Blackwell 部件進行比較,領先優勢大幅縮小。據我們了解,英偉達的頂級規格芯片應能提供約 5 petaFLOPS 的稀疏 FP16 性能。這將 Cerebra 的領先優勢縮小至 25 倍。但正如我們當時指出的那樣,所有這一切都取決于您的模型能否利用稀疏性。
臺積電和 Synopsys 正推進部署使用英偉達的計算光刻平臺
英偉達今天宣布,臺積電和 Synopsys 將使用英偉達的計算光刻平臺投入生產,以加速制造并突破下一代先進半導體芯片的物理極限。
全球領先的代工廠臺積電 (TSMC) 和芯片到系統設計解決方案的領導者新思科技 ( Synopsys) 已將英偉達 cuLitho 與其軟件、制造工藝和系統集成,以加快芯片制造速度,并在未來支持最新一代 英偉達 Blackwell 架構 GPU。
英偉達創始人兼首席執行官黃仁勛表示:「計算光刻是芯片制造的基石。」「我們與臺積電和新思科技合作,在 cuLitho 上開展工作,應用加速計算和生成式 AI 來開辟半導體縮放的新領域。」
英偉達還推出了新的生成式 AI 算法,增強了 cuLitho(GPU 加速計算光刻庫),與當前基于 CPU 的方法相比,顯著改進了半導體制造工藝。
計算光刻是半導體制造過程中計算最密集的工作負載,每年在 CPU 上消耗數百億小時。芯片的典型掩模組(其生產的關鍵步驟)可能需要 3000 萬小時或更多小時的 CPU 計算時間,因此需要在半導體代工廠內建立大型數據中心。通過加速計算,350 個 英偉達 H100 系統現在可以取代 40,000 個 CPU 系統,加快生產時間,同時降低成本、空間和功耗。
臺積電首席執行官 CC Wei 博士表示:「我們與英偉達合作,將 GPU 加速計算集成到臺積電工作流程中,從而實現了性能的巨大飛躍、吞吐量的顯著提高、周期時間的縮短以及功耗要求的降低。」「我們正在將 英偉達 cuLitho 轉移到臺積電生產,利用這種計算光刻技術來驅動半導體微縮的關鍵組件。」
自去年推出以來,cuLitho 使臺積電為創新圖案技術開辟了新的機遇。在共享工作流程上測試 cuLitho 時,兩家公司共同實現了曲線流程的 45 倍加速以及傳統曼哈頓式流程近 60 倍的改進。這兩種類型的流不同,對于曲線,掩模形狀由曲線表示,而曼哈頓掩模形狀被限制為水平或垂直。
Synopsys 總裁兼首席執行官 Sassine Ghazi 表示:「二十多年來,Synopsys Proteus 掩模合成軟件產品一直是加速計算光刻(半導體制造中要求最高的工作負載)的經過生產驗證的選擇。」「隨著向先進節點的轉變,計算光刻的復雜性和計算成本急劇增加。我們與臺積電和 英偉達的合作對于實現埃級擴展至關重要,因為我們開創了先進技術,通過加速計算的力量將周轉時間縮短了幾個數量級。」






評論