想從事深度學習工作的進來看,經典面試問題幫你整理好了

更新幾個面試被問到或者聯想出來的問題,后面有時間回答
本文引用地址:http://www.j9360.com/article/201709/364073.htmSGD 中 S(stochastic)代表什么
個人理解差不多就是Full-Batch和Mini-Batch
監督學習/遷移學習/半監督學習/弱監督學習/非監督學習?
本筆記主要問題來自以下兩個問題,后續會加上我自己面試過程中遇到的問題。
深度學習相關的職位面試時一般會問什么?會問一些傳統的機器學習算法嗎?
如果你是面試官,你怎么去判斷一個面試者的深度學習水平?
以下問題來自@Naiyan Wang
CNN最成功的應用是在CV,那為什么NLP和Speech的很多問題也可以用CNN解出來?為什么AlphaGo里也用了CNN?這幾個不相關的問題的相似性在哪里?CNN通過什么手段抓住了這個共性?
Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
Learn TensorFlow and deep learning, without a Ph.D.
The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
以上幾個不相關問題的相關性在于,都存在局部與整體的關系,由低層次的特征經過組合,組成高層次的特征,并且得到不同特征之間的空間相關性。如下圖:低層次的直線/曲線等特征,組合成為不同的形狀,最后得到汽車的表示。

CNN抓住此共性的手段主要有四個:局部連接/權值共享/池化操作/多層次結構。
局部連接使網絡可以提取數據的局部特征;權值共享大大降低了網絡的訓練難度,一個Filter只提取一個特征,在整個圖片(或者語音/文本) 中進行卷積;池化操作與多層次結構一起,實現了數據的降維,將低層次的局部特征組合成為較高層次的特征,從而對整個圖片進行表示。如下圖:
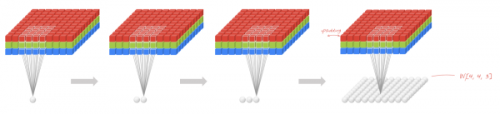
上圖中,如果每一個點的處理使用相同的Filter,則為全卷積,如果使用不同的Filter,則為Local-Conv。
為什么很多做人臉的Paper會最后加入一個Local Connected Conv?
DeepFace: Closing the Gap to Human-Level Performance in Face Verification
以FaceBook DeepFace 為例:

DeepFace 先進行了兩次全卷積+一次池化,提取了低層次的邊緣/紋理等特征。
后接了3個Local-Conv層,這里是用Local-Conv的原因是,人臉在不同的區域存在不同的特征(眼睛/鼻子/嘴的分布位置相對固定),當不存在全局的局部特征分布時,Local-Conv更適合特征的提取。
以下問題來自@抽象猴
什麼樣的資料集不適合用深度學習?
數據集太小,數據樣本不足時,深度學習相對其它機器學習算法,沒有明顯優勢。
數據集沒有局部相關特性,目前深度學習表現比較好的領域主要是圖像/語音/自然語言處理等領域,這些領域的一個共性是局部相關性。圖像中像素組成物體,語音信號中音位組合成單詞,文本數據中單詞組合成句子,這些特征元素的組合一旦被打亂,表示的含義同時也被改變。對于沒有這樣的局部相關性的數據集,不適于使用深度學習算法進行處理。舉個例子:預測一個人的健康狀況,相關的參數會有年齡、職業、收入、家庭狀況等各種元素,將這些元素打亂,并不會影響相關的結果。
對所有優化問題來說, 有沒有可能找到比現在已知算法更好的算法?
機器學習-周志華
沒有免費的午餐定理:
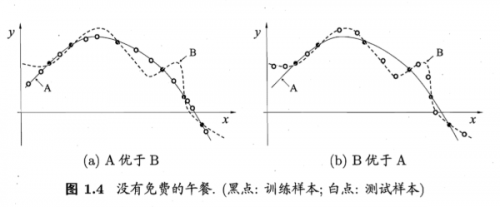
對于訓練樣本(黑點),不同的算法A/B在不同的測試樣本(白點)中有不同的表現,這表示:對于一個學習算法A,若它在某些問題上比學習算法 B更好,則必然存在一些問題,在那里B比A好。
也就是說:對于所有問題,無論學習算法A多聰明,學習算法 B多笨拙,它們的期望性能相同。
但是:沒有免費午餐定力假設所有問題出現幾率相同,實際應用中,不同的場景,會有不同的問題分布,所以,在優化算法時,針對具體問題進行分析,是算法優化的核心所在。
用貝葉斯機率說明Dropout的原理
Dropout as a Bayesian Approximation: Insights and Applications
何為共線性, 跟過擬合有啥關聯?
Multicollinearity-Wikipedia
共線性:多變量線性回歸中,變量之間由于存在高度相關關系而使回歸估計不準確。
共線性會造成冗余,導致過擬合。
解決方法:排除變量的相關性/加入權重正則。
說明如何用支持向量機實現深度學習(列出相關數學公式)
這個不太會,最近問一下老師。
廣義線性模型是怎被應用在深度學習中?
A Statistical View of Deep Learning (I): Recursive GLMs
深度學習從統計學角度,可以看做遞歸的廣義線性模型。
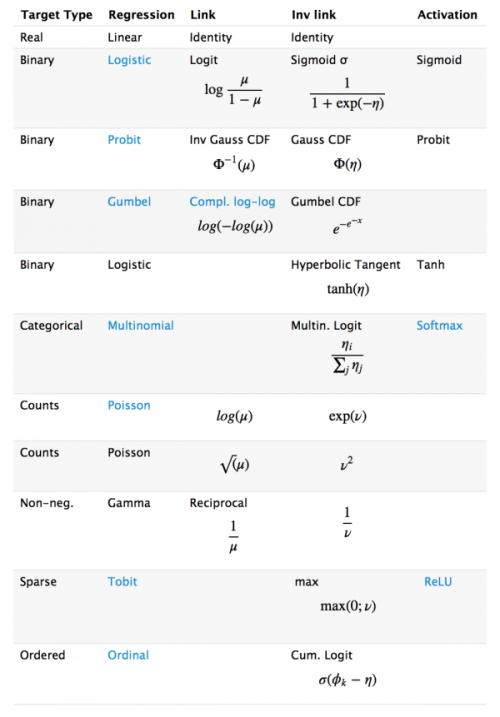
廣義線性模型相對于經典的線性模型(y=wx+b),核心在于引入了連接函數g(.),形式變為:y=g?1(wx+b)。
深度學習時遞歸的廣義線性模型,神經元的激活函數,即為廣義線性模型的鏈接函數。邏輯回歸(廣義線性模型的一種)的Logistic函數即為神經元激活函數中的Sigmoid函數,很多類似的方法在統計學和神經網絡中的名稱不一樣,容易引起初學者(這里主要指我)的困惑。下圖是一個對照表:
什麼造成梯度消失問題? 推導一下
Yes you should understand backdrop-Andrej Karpathy
How does the ReLu solve the vanishing gradient problem?
神經網絡的訓練中,通過改變神經元的權重,使網絡的輸出值盡可能逼近標簽以降低誤差值,訓練普遍使用BP算法,核心思想是,計算出輸出與標簽間的損失函數值,然后計算其相對于每個神經元的梯度,進行權值的迭代。
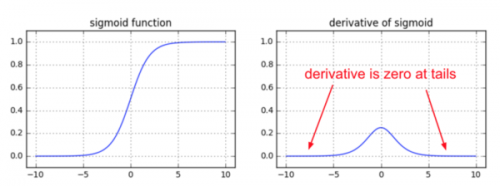
梯度消失會造成權值更新緩慢,模型訓練難度增加。造成梯度消失的一個原因是,許多激活函數將輸出值擠壓在很小的區間內,在激活函數兩端較大范圍的定義域內梯度為0。造成學習停止
以下問題來自匿名用戶
Weights Initialization. 不同的方式,造成的后果。為什么會造成這樣的結果。
幾種主要的權值初始化方法: lecun_uniform / glorot_normal / he_normal / batch_normal
lecun_uniform:Efficient BackProp
glorot_normal:Understanding the difficulty of training deep feedforward neural networks
he_normal:Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
batch_normal:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
為什么網絡夠深(Neurons 足夠多)的時候,總是可以避開較差Local Optima?
The Loss Surfaces of Multilayer Networks
Loss. 有哪些定義方式(基于什么?), 有哪些優化方式,怎么優化,各自的好處,以及解釋。
Cross-Entropy / MSE / K-L散度
Dropout。 怎么做,有什么用處,解釋。
How does the dropout method work in deep learning?
Improving neural networks by preventing co-adaptation of feature detectors
An empirical analysis of dropout in piecewise linear networks
Activation Function. 選用什么,有什么好處,為什么會有這樣的好處。
幾種主要的激活函數:Sigmond / ReLU /PReLU
Deep Sparse Rectifier Neural Networks
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification







評論