Google大腦工程師詳解:深度學習技術能帶來哪些新產品?

那么,“深度學習的最新進展能帶來哪些產品上的突破?”
Quora上就有這樣一個問題,而Google Brain的研究工程師Eric Jiang也給出一個最高贊的答案。下面就是Jiang的回答,大周末的,讓我們一起來漲漲姿勢:
Deep Learning是指包含以下特征的一類機器學習技術:
· 大規模神經網絡(包含百萬級的自由變量);
· 高性能計算(上千個并行處理器);
· 大數據(例如百萬級的彩色圖像、棋譜等)
目前,深度學習技術已經在眾多領域達到了先進水平,例如視覺、聲音、機器人、自然語言處理。深度學習最近的進展吸收了統計學習[1, 2]、增強學習和數值優化的思想。關于這個領域的概況,見參考文獻[9, 10]。
我下面列出一些借助目前的深度學習技術才可能實現的產品類別,排名不分先后:
定制化數據壓縮、壓縮感知、數據驅動的傳感器校準、離線AI、人機交互、游戲、藝術助手、非結構化數據挖掘、語音合成。
定制化數據壓縮
假設你在設計一個視頻直播應用,希望用一套有損編碼方案來減少需要向互聯網上傳的包。
你可以用H.264這樣現成的編碼解碼器,但是H.264并不是最理想的解決方案,因為它是為通用視頻校準的,也就是從貓咪視頻到故事片都能用。改用為FaceTime視頻而校準的編解碼器可能會更好,因為當我們利用了“屏幕中間總是有張臉”這一點,能省下更多流量。
然而,設計一個這樣的編碼方案是有難度的。我們要怎樣說明臉在什么位置,視頻對象有多少根眉毛、眼睛是什么顏色、下巴是什么形狀等等特征?如果頭發擋住了眉毛怎么辦?圖像中沒有臉或者有多個人的臉怎么辦?
這時候,深度學習就派上用場了。自動編碼器是一種神經網絡,只是它的輸出和輸入數據一樣而已。學習這個“恒等映射(identity mapping)”之所以重要,是因為這個自動編碼器的隱藏層神經網絡比輸入層要小。這個“信息瓶頸”迫使自動編碼器在隱藏層中學習一種數據的壓縮表示(compressed representation),這種壓縮表示還將被神經網絡的其它層解碼回原始形態。
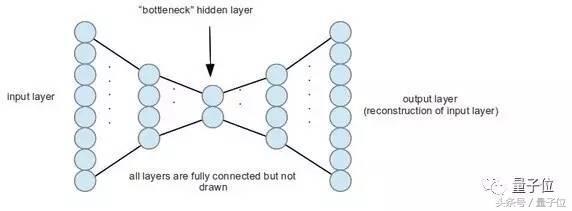
通過端到端的訓練,自動編碼器等深度學習技術可以適應你數據的細微差別。不同于主成分分析法(PCA),編解碼步驟不受(線性)仿射變換的限制。PCA學習的是一種“編碼線性變換”,自動編碼器學習的是“編碼程序”。
這讓神經網絡更加強大,能用于更復雜的、特定領域的壓縮,從在Facebook上存大量自拍到加載速度更快的YouTube視頻,科學數據壓縮再到降低你個人iTunes資料庫所占的空間,都能用上這種技術。設想一下,假如你的iTunes資料庫為了讓你的音樂少占一點空間,它可能專門學習一種“鄉村歌曲編碼器”哦!
壓縮感知
壓縮感知和有損壓縮的解碼方面緊密相關。很多有趣的信號都有特定的結構,也就是說,信號的分布并不完全是任意的。這說明實際上,我們不需要為了獲取信號的完美重建而在奈奎斯特極限采樣,只要我們的解碼算法可以正確地找出它的結構。
深度學習適用于這個任務,因為我們不需要人工標注特征就能用神經網絡來學習稀疏結構。以下是一些產品應用:
超分辨率算法(waifu2X),就是美劇CSI邁阿密里“增強”按鈕的真實版;
使用WiFi無線電波干擾可以透視墻壁另一側的人(MIT Wi-Vi);
基于不完全觀察(例如2D圖像、部分遮擋的圖像)解譯3D結構;
聲納、激光雷達信息的更精確重現。
數據驅動的傳感器校準
好的傳感器和測量裝置通常依賴于昂貴、精密的部件。
我們以數碼相機為例。數碼相機假設鏡頭中的玻璃鏡片遵循一種精密的幾何結構,拍照時,內置的處理器負責用光線通過透鏡的等式,來計算出最終的圖像。

如果透鏡有刮痕、彎曲、變形,就打破了相機原本的假設,圖像的質量也不會好。
再舉一個例子。為了便于計算,我們目前用在MRI和心電圖中的解碼模型會假設頭蓋骨是一個正球體。這在一定程度上是可行的,但有時,檢測出的腫瘤位置會有幾毫米的誤差。
更精確的攝影和MRI成像技術應該對幾何誤差進行補償,無論這些誤差來自潛在錯誤源還是制造缺陷。
幸運的是,深度學習給了我們借助數據校準解碼算法的能力。
不同于“均碼”的解碼模型(例如卡爾曼濾波器),我們可以針對每個受體或者測量儀器進行調整,從而表示出更復雜的偏差。如果相機鏡頭有刮痕,我們可以訓練解碼軟件對變化了的幾何形態進行補償。也就是說,我們不再需要以極高的精度制造和排列傳感器,也就節約了大量資金。
某些情況下,我們可以在完全去除了硬件的情況下,讓算法去進行補償。哥倫比亞大學的計算攝影學實驗室開發了一種沒有鏡片的相機,也就是軟件定義成像(software-defined imaging)
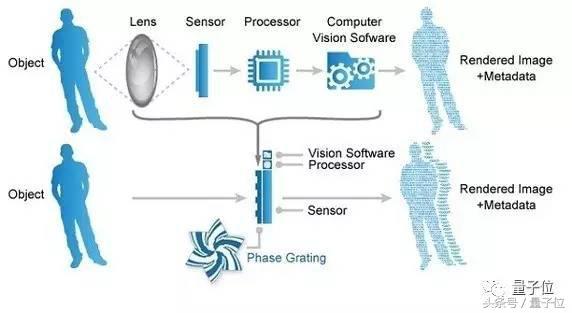
離線AI
能在不聯網的情況下運行AI算法,對要求低延遲(例如機器人、自動駕駛汽車)或者沒有穩定網絡連接(如旅行方面)的應用來說至關重要。
深度學習在這方面尤其合適。訓練階段結束后,神經網絡的前饋環節運行得非常快,另外,把大型神經網絡一直縮小到可以在智能手機上運行也很簡單,雖然準確率上會有所損失。
Google在Google Translate應用的離線拍照翻譯功能上已經這么做了。








評論