IBM訪談:如何用物聯網拯救 PM2.5?

人無時不刻不在呼吸,而動輒爆表的 PM2.5,掙扎的霧霾讓我們不禁憂慮起自身的健康來。
本文引用地址:http://www.j9360.com/article/201611/339849.htm在一年以前,IBM 研究院推出了 Green Horizon項目,雷鋒網此前也做過報道。Green Horizon 利用IBM的機器學習技術及物聯網技術(IoT),從大數據中挖掘從天氣到污染指數的一系列海量信息,以反復的迭代及自適應的調整系統,鍛造出世界上最為精確的能源和環境預測系統。
IBM 首先把試點城市選在了南非的約翰內斯堡,與當地的研究機構進行協作。面對不斷惡化的大氣環境及氣候變化,它們又會做出怎樣的嘗試呢?日前,駐該機構的 IBM 科學家 Tapiwa Chiwewe 與 IBM的 Chris Sciacca 進行了一次訪談,雷鋒網摘編如下,未經許可不得轉載。

Tapiwa Chiwewe
Chris Sciacca(下稱 Sciacca):
目前這個環境預測系統進行到了怎樣的階段?
Tapiwa Chiwewe(下稱 TC):
此前試點城市能夠成功預測明天的環境狀況,不過經過我們的努力,能夠將這一時間延長到七天。
Sciacca:
那么,這個預測系統目前達到了怎樣的精度?
TC:
現在能夠達到 10 km*10 km 的空間分布率,而如果能增加更多的計算源,這一數字還能提升到 1 km*1 km 的高分辨率。
Sciacca:
如果要用預測結果做決策,精度要達到怎樣的水平?
TC:
如果這些判斷要用于決策的話,準確度能達到 70% 以上(包括一些明顯的、肉眼可排除的錯誤)就可以稱得上是很不錯的結果了。而預測污染指數為環境提供公共預警信號肯定是大有裨益。
Sciacca:
我們都知道,在一天內或者一個地點中污染物的數量不可避免地會存在一定波動,那么這一數字與預測結果相比存在多少誤差?
TC:
污染情況的波動取決于特定的天氣狀況。一些會造成強烈影響的天氣狀況(如強風、降雨、低氣壓等)能夠在幾個小時內迅速改變污染指數。而空氣質量的預測主要借助的是天氣模型來捕獲上述容易影響污染狀況的信息并做出調整,因此誤差的規模就會減小很多。
Sciacca:
目前階段及未來,我們是否能準確判斷污染源?
TC:
污染源對于預測系統而言是另一個全新的命題,因為它需要對每個污染源進行判斷,包括直接排放量、天氣影響,伴隨化學反應產生的二次污染等。
我們實際上可以追蹤污染源來自什么樣的地點。但它需要大量的數據源模型,且不能包含目前的試點。不過它可能是未來商業化的一個變現手段。另外,風是一個比較簡單的判斷因素,如果我們只考慮污染物的飄散狀況,這個模型就會相對簡單。
Sciacca:
要讓這個系統順利運轉,我們需要什么樣的支持?
TC:
實時傳感器的數據當然必不可少。日常的天氣預測可以以三天為界,并通過在線站點進行分析與整合。
Sciacca:
數據的來源是什么,又是如何進行收集的?
TC:
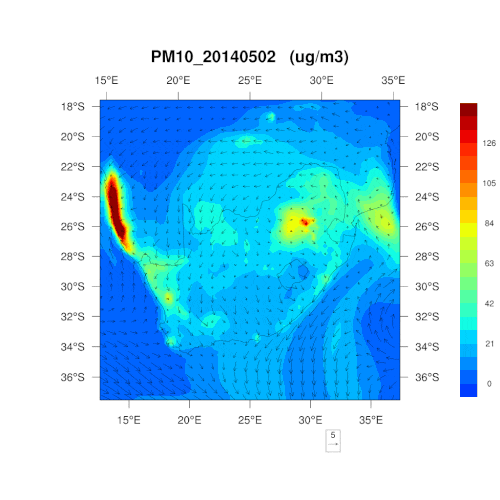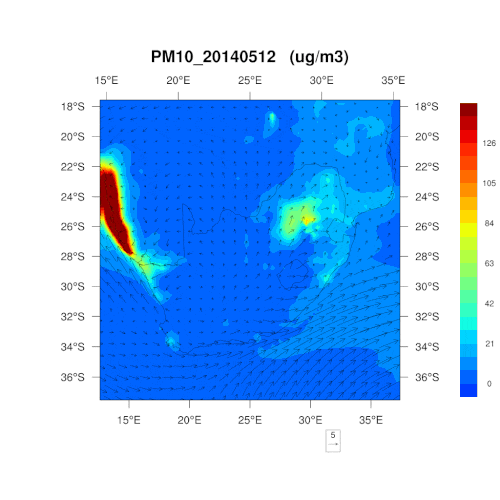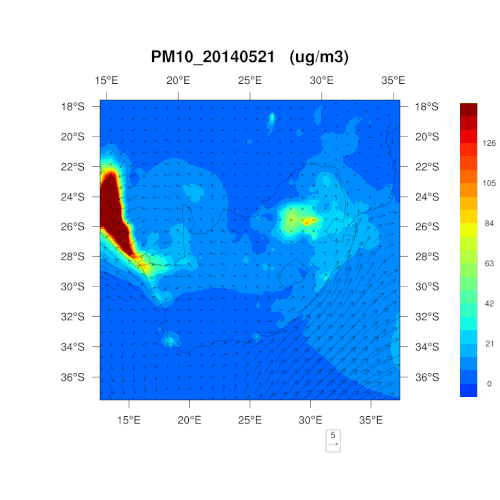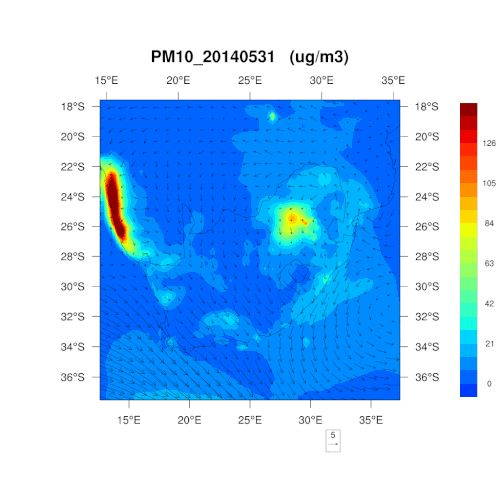
數據源于三個南非的空氣監測網絡,為約翰內斯堡、Thswane及瓦爾河監測中心。在三個網絡點間,有 21 個監測站,按照南非空氣質量數據中心的要求收集數據。我們準備將這一功能增加到 IBM 的 The Weather Company 商業計劃中。
Sciacca:
是否能為我們解釋一下采用 PM10、PM2.5和二氧化氮這三個指標的原因?可否簡單理解為,這三項為最“簡單粗暴”的判斷標準?
TC:
在監測之時,那些容易對人類、野生動植物及環境的健康造成影響的污染物自然首當其沖。南非通常每五年就會重新制定一次空氣質量管理計劃,明確首要關注的污染物,考慮所可能造成的危害,對干預策略的有效性進行判斷,以控制空氣污染。
Sciacca:
約翰內斯堡的哪些信息能夠作為數據源?
TC:
數據的質量會以多種形式從不同站點收集,包括讀數記錄、采樣間隔的時間、還有讀數的準確性。這些都受監測站設備維護狀況的影響。
Sciacca:
后續將有什么研究計劃?
TC:
除了收集更多的數據,我們計劃推出API,開發人員能夠基于此創建為消費者和企業使用的應用程序。
如果你對他的研究感興趣,歡迎閱讀他的論文:Machine Learning Based Estimation of Ozone Using Spatio-Temporal Data from Air Quality Monitoring Stations







評論