基于CAPI FPGA的醫學超聲成像算法異構加速

摘要:在醫學超聲成像算法中,最經典和最廣泛使用的是延遲疊加算法。延遲疊加算法在超聲成像、雷達信號發射、接收以及天線信號波束形成等方面有著廣泛的應用。雖然該算法并不是典型的性能需求型算法,但是在醫學成像云計算服務的新需求下,需要提高該算法的計算速度,以克服云計算中網絡傳輸速度相對較慢的約束。然而,以中央處理器作為主要計算資源的傳統云計算框架無法滿足醫學超聲圖像快速生成的性能需求,因此,本文中使用以現場可編程邏輯門陣列作為異構加速資源的SuperVessel云平臺作為并行延遲疊加算法的實現平臺。當包括現場可編程邏輯門陣列和中央處理器之間的數據傳輸時間在內時,SuperVessel云平臺上該算法異構實現的運行速度相較于中央處理器中該算法的運行速度提升了約22倍。
本文引用地址:http://www.j9360.com/article/201609/310488.htm引言
延遲疊加算法是醫學超聲成像算法中最經典和最廣泛使用的基本算法,在眾多應用場景中有著廣泛的運用,例如醫學超聲成像[1]、雷達信號的發射和接收[2]以及天線信號波束形成[3]等。同時,該算法可以在眾多不同的設備中實現,例如在臨床和便攜嵌入式醫學超聲實時成像設備中均有延遲疊加算法的實現。然而,當我們考慮醫學成像云計算服務的全新應用場景時,傳統計算設備的計算速度并不能滿足實時成像的計算需求。因此,有必要研發更快的、更有效的延遲疊加算法云實現。
傳統的延遲疊加算法實現一般是采用基于中央處理器結構的串行計算模式實現。對于某些應用來說,中央處理器的計算速度可以滿足其計算需求,然而對于醫學成像云服務應用來說,中央處理器的計算速度還是相對太慢。另一方面,使用現場可編程邏輯門陣列(Field-Programmable Gate Array,FPGA)可以滿足并行實現的計算需求,而SuperVessel平臺正是第一個將FPGA加速融入到云計算中的計算平臺,因此,適合在該平臺上實現和評測并行延遲疊加算法。
本文將詳細描述SuperVessel云平臺[4]上使用FPGA加速的并行延遲疊加算法的設計和實驗評測。
1 延遲疊加算法及其并行實現方案
1.1 延遲疊加算法
圖1中的代碼為醫學超聲成像中串行延遲疊加算法的核心代碼。在該算法中,首先計算接收到的回聲超聲信號的延遲量,進而將延遲后的回聲信號疊加,得到增強的回聲信號輸出,即超聲成像圖像中一個像素點的亮度值。
延遲疊加算法包含三個循環,如圖1中所示。該算法的時間復雜度為:
![]() (1)
(1)
其中變量LC(Line Count)表示輸出圖像中垂直的圖像線條數,變量RC(Rows Count)表示輸出圖像中的行數,變量PA(Probe Amount)表示接收回聲超聲信號的探頭陣元數量。
在本文的設計和實驗中,LC設定為64,RC設定為1024,PA設定為64,所以每生成一幅超聲圖像需要計算4194304次延遲量計算和疊加計算。此外,在實時成像的情況下,要求形成流暢的實時成像視頻需要每秒24幀圖像的幀率。因此,定義TC為上述每一次延遲量計算和疊加計算共需要消耗的時間,則:
![]() (2)
(2)
對上式進行移項,可得:
 (3)
(3)
在本文的設計和實驗中,為了實現實時成像,根據公式(3)演算出TC的最大值為9.93×10-9秒。此外,隨著輸入數據集的增大,實時成像的實現難度也相應提升,因此,需要考慮并行實現方案。
1.2 延遲疊加算法的并行實現
如圖1所示,串行延遲疊加算法的核心代碼中,核心操作是對延遲后輸入數據的疊加。針對于最終生成圖像中的一個特定像素點(i, j),存在PA次輸入數據信號的疊加,疊加的公式如下:
![]() (4)
(4)
其中,i、j和k分別是LC、RC和PA的累加變量,而d是延遲量的數值,可以通過特定i、j和k變量的相關計算得到。當變量i為一個特定值ifixed時,最終圖像中第ifixed列上像素點的亮度值可以通過如下公式計算:
 (5)
(5)
通過對延遲疊加算法進行分析,得出計算不同圖像線上的image(ifixed, j)時并不存在相互間的數據依賴。因此,延遲疊加算法的計算過程可以并行化實現。

2 SuperVessel云平臺上的算法實現
本文使用SuperVessel云平臺實現的并行延遲疊加算法需要滿足以下計算需求:1、在一個時鐘周期內計算特定像素點image(i, j)的值;2、實現足夠精確的浮點數計算;3、FPGA上全流水線化計算。
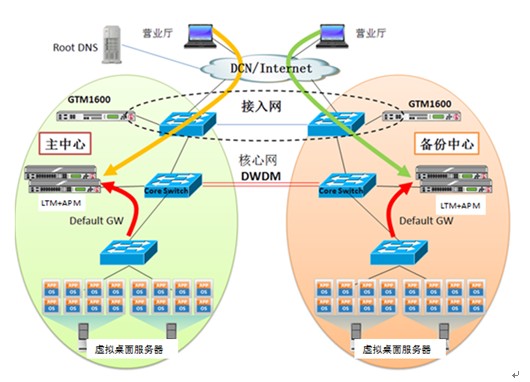
本文使用CAPI FPGA實現并行延遲疊加算法的設計框圖如圖2所示。該設計包含五個主要部分:輸入數據分離器、RowsCount循環生成器、延遲信號選擇器、疊加器和數據輸出控制器。以下是這五個部分設計原理和實現模式的詳細描述:
輸入數據分離器: CAPI傳輸總線的帶寬是256位,而每一個延遲信號選擇器僅需要32位的帶寬,以供傳輸標準的單精度浮點數。由圖2可以看出該設計中包含64個延遲信號選擇器,因此,需要將CAPI總線的256位輸入數據分離,并且規劃好輸入數據讀取的順序。輸入數據讀取過程的規劃如下:
第一步:在T時鐘周期內,第0個至第7個延遲信號選擇器讀取一個CAPI輸入信號數據;在(T+1)時鐘周期內,第8個至第15個延遲信號選擇器讀取下一個CAPI輸入信號數據;以此類推,直到在(T+7)時鐘周期內,第56個至第63個延遲信號選擇器讀取下一個CAPI輸入信號數據。
第二步:重復第一步所描述的步驟,直到生成一幅圖像中某一列像素點所需要的所有輸入信號數據讀取完畢。
第三步:當圖像中某一列的所有像素點數值均計算完成,則回到第一步讀取生成圖像中下一列像素點所需要的輸入信號數據過程。
RowsCount循環生成器:當圖像中某一列像素點計算所需要的所有輸入信號數據讀取完畢時,循環生成器將開始生成RC循環變量j的值。變量j的初始值為0,在每一個時鐘周期內自增1,直到最大值1023。
延遲信號選擇器:延遲信號選擇器將計算對應像素點不同數據通道上的延遲量,并選擇對應的輸入信號數據。實現部分包含了一個延遲量計算器和一個BRAM存儲器,BRAM存儲器用于存儲某個數據輸入接收通道,接收通道接收到的輸入信號數據。
疊加器:在并行延遲疊加算法的CAPI FPGA設計中共有64個延遲信號選擇器,而這64個延遲信號選擇器的輸出值之和,即為image(i, j)的最終結果。計算兩個延遲信號選擇器輸出值之和需要一個加法器,對應地,計算64個延遲信號選擇器輸出值之和需要63個加法器。為了使加法器設計流水線化,疊加器模塊將加法器分為6個階段層次,每層分別使用32、16、8、4、2、1個加法器。
輸出數據控制器:由于CAPI總線提供的帶寬是256位,而本文所描述的設計每一個時鐘周期內輸出數據是一個32位的浮點數。因此,輸出的數據可以先存放于FPGA中,每8個時鐘周期通過CAPI總線接口向CPU輸出一次數據。
除了上述的五個主要實現模塊外,本設計方案中也使用了下面兩個設計模塊:
浮點數計算單元:本設計使用了Xilinx Vivado軟件中提供的浮點數IP核作為浮點數計算單元模塊。該類IP核遵循了IEEE-754的標準,因此,本文設計中的浮點數計算結果相較于CPU實現的浮點數計算結果而言,誤差很小。另一方面,該類IP核是全流水線化的,這也進一步提升了設計的吞吐量。
狀態控制器:在圖像像素點數值計算的過程中有兩個狀態階段:第一個階段是輸入信號數據的讀取過程,第二個階段是延遲量的計算和延遲后輸入信號數據的疊加過程。狀態控制器包含一個狀態標記變量,以指示當前計算的狀態階段。當第一階段的輸入信號數據讀取過程結束時,BRAM的寫入地址waddr的值將為2047。因此,可定義waddr==2047為第二階段開始的標記信號。當第二階段結束時,將waddr的值設為0,則將觸發第一階段重新開始,進行下一輪計算。此外,當圖像中所有的像素點計算完成時,輸出圖像的像素點數目為65536 。所以,可定義該數值為圖像計算完成的標志變量,標志著算法計算結束。
3 實驗和評測結果討論
3.1 SuperVessel平臺上使用CAPI FPGA加速器的流程
在SuperVessel平臺上使用CAPI FPGA加速器來加速算法應用,需要執行以下步驟:
1、使用Xilinx Vivado軟件設計FPGA加速器核心模塊;
2、在本地的x86機器上集成FPGA加速器核心模塊和CAPI仿真框架進行仿真驗證;
3、在本地機器上編譯FPGA加速器核心模塊和CAPI加速框架構成的加速器包,并生成對應的bitstream文件;
4、將加速器bitstream文件上傳到SuperVessel云平臺上;
5、在SuperVessel云平臺上申請虛擬機資源,并關聯對應的加速器bitstream文件,然后啟動虛擬機運行加速器。
另外需要注意以下兩點:
VPN網絡:SuperVessel云平臺上申請的虛擬機資源沒有對應的可直接訪問的公網IP,需要使用對應的VPN網絡。使用的VPN網絡在Windows、Linux、MacOS等主流操作系統中均有對應的軟件支持。
內存占用:編譯步驟3中所述的加速器包時需要大量本地機器內存,尤其在綜合和布線的階段;而且CAPI FPGA加速器設計越復雜,本地機器內存占用量就越大。在本文的實驗評測中觀察到,編譯階段的內存占用量最高達到了14GB。內存不足將導致編譯失敗,因此需要根據CAPI FPGA設計的大小配置足夠的內存資源。

3.2 仿真數據生成
本文的實驗過程中為了測試使用CAPI FPGA并行加速的延遲疊加算法,使用Field II醫學超聲信號模擬器[5]仿真了醫學超聲回波輸入數據。本文的醫學超聲圖像回波輸入數據仿真了128個陣元的超聲探頭,探頭間距為0.3048mm,采用5 kHz的脈沖發射頻率和40 MHz的回波接收采樣頻率。此外,超聲圖像的成像場景仿真了線形點陣列作為成像對象的散射源。
3.3 實驗結果討論
在實驗中,通過網絡將10份醫學超聲圖像的輸入信號數據載入SuperVessel云平臺,其中每份圖像的輸入信號數據對應于一張超聲圖像。在云平臺上通過CAPI加速架構提供的API,調用FPGA加速器,將數據從云平臺上CPU對應的DDR內存中傳輸到FPGA中的BRAM里;完成圖像像素點數值計算后再將數據傳回DDR內存。實測從數據傳輸開始到數據傳輸結束的時間,得到并行延遲疊加算法云計算應用運行的總時間。并行延遲疊加算法在FPGA上的計算時間通過統計算法執行的時鐘周期來確定,因此,還可推算出數據傳輸所消耗的時間。通過多次實驗求得各項時間參數的平均值,如表1所示。

與此同時,使用SuperVessel云平臺上CPU計算獲得同樣的10張醫學超聲圖像,其每張圖像計算的平均耗時為246 ms。由此計算可得,本文設計的CAPI FPGA并行延遲疊加算法實現的加速比達到了約22倍。此外,通過實驗推導出該設計的TC數值為秒,滿足1.1小節提出的實時成像要求。
4 結論和展望
本文描述了在SuperVessel云平臺上,設計和評測基于CAPI FPGA加速器技術的并行延遲疊加算法。實驗評測結果表明,SuperVessel云平臺上基于CAPI FPGA加速器的并行延遲疊加算法的運行速度相較于使用CPU計算的延遲疊加算法的運行速度提高了約22倍,該速度可以滿足醫學成像云計算服務的需求。
目前,本文設計中的超聲回波信號接收通道數為64。通道數越大時,得到的圖像越清晰,所以我們使用同樣的方案設計了96通道和128通道的成像方案,但由于資源限制的原因未能成功運行。我們將繼續優化當前的設計,降低資源占用并采用多片FPGA設計方案,進一步提高通道數量和數據處理能力。
另外,SuperVessel云平臺提供的CAPI加速技術可以應用于其他計算密集型算法加速,尤其是輸入輸出數據量小,而時間復雜度高的算法。我們將進一步把其他醫學超聲成像算法設計到SuperVessel云平臺上實現。
參考文獻:
[1] G. Matrone, A.S. Savoia, G. Caliano, and G. Magenes, “ The Delay Multiply and SumBeamforming Algorithm in Ultrasound B-Mode Medical Imaging,” IEEE Transactions onMedical Imaging, 2015, 34, (4), pp. 940-949.
[2] T. Sakamoto, T. Sato, P.J. Aubry, and A.G. Yarovoy, “Ultra-Wideband Radar ImagingUsing a Hybrid of Kirchhoff Migration and Stolt F-K Migration With an Inverse BoundaryScattering Transform,” IEEE Transactions on Antennas and Propagation, 2015, 63, (8),pp. 3502-3512.
[3] S.S. Tiang, M. Sadoon, T.F. Zanoon, M.F. Ain, and M.Z. Abdullah, “Radar sensingfeaturing biconical antenna and enhanced delay and sum algorithm for early stage breastcancer detection,” Progress In Electromagnetics Research B, 2013, 46, pp. 299-316.
[4] Y. Lin, and L. Shao, “SuperVessel: The Open Cloud Service for Open-POWER,” White paper, IBM corporation, 2015.
[5] J.A. Jensen, “Ultrasound fields from triangular apertures,” Journal of the Acoustical Society of America, 1996, 100, (4), pp. 2049-2056.
本文來源于中國科技期刊《電子產品世界》2016年第9期第41頁,歡迎您寫論文時引用,并注明出處。






評論