基于數據挖掘的入侵檢測系統的改進與實現

從Apriori算法執行過程可以了解到Apriori算法的缺點:一方面,在每一次產生候選項集時循環產生的組合過多,沒有具體考慮不符合閾值的組合;另一方面,對每個項集計算支持度時要對整個數據庫掃描一遍,對于分析網絡數據包這樣大型的數據庫會增加I/O開銷。這種開銷是隨著數據庫的記錄的增加呈幾何級數的增長。現階段人們開始探索一種能減少系統I/O開銷的更為快捷的算法,相繼提出了許多改進的算法。主要有Park等人提出的基于哈希技術的DHP算法,Savasere等人提出的基于劃分技術的Partition算法,Toivonen提出的抽樣算法,Sampling、Zaki等人提出的基于等價類和圖論的MaxCique系列算法,S.Agarwal等人提出的采用有序樹數據結構的TreeP-rojection算法以及Orlando等人提出的Apriori增強版的DCP算法等。而對于挖掘數據包是網絡數據包時,數據源的特征屬性較多而且數據包的記錄數較大,這就需要必須選擇合理的算法才能發現能描述用戶特征的規則。
1 引用作用度的Apriori_lift算法
1.1 作用度
作用度是采用相關分析描述規則內在價值的度量,它描述的是項集X對Y的影響力的大小。作用度越高表示X的出現對Y出現的可能性影響越大,作用度度量的是X與Y之間蘊涵的實際強度。
作用度表示為:
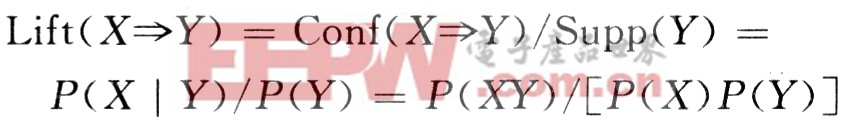
1.2 Aprior=>lift算法的描述
第一步:大項集的生成;
第二步:采用作用度找出強關聯規則。
使用第一步找到的所有頻繁項集產生期望的規則。為了獲取強有效關聯規則,在使用信任度的基礎上增加作用度計算來度量規則的有效性。具體描述過程如下:
(1)對于每個頻繁K(K≥2)項集L,產生L的所有非空子集S;
(2)對于項集L的每個非空子集S,規則:
如果lift[S=>(L-S)]>1,則規則“S=>(L-S)”是強有效關聯規則,輸出。
2 算法性能比較
在局域網環境中(如圖1所示)捕獲網絡數據包2 000個,分別采用Apriori,Apriori_lift算法挖掘,其挖掘過程及結果如下:
表3是實驗采用的兩個數據集Tcppro,Udppro。
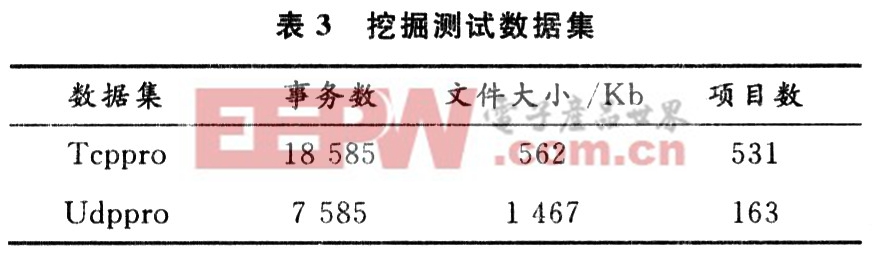
表4是二種算法在不同支持度(Supp)信任度(Conf)下的挖掘結果統計。
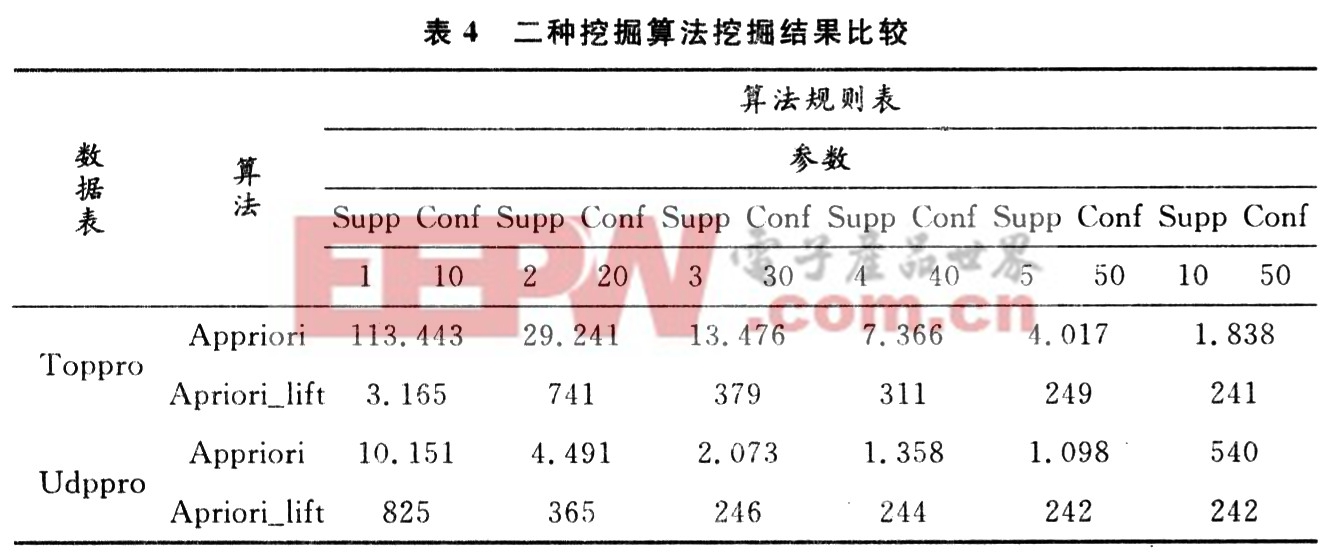
由表4可知,在相同的作用度與支持度的情況下,Apriori,Apriori_lift算法挖掘得到的規則逐漸遞減;在不同的作用度與支持度情況下,參數值越低挖掘出的規則越多,這主要體現在Apriori算法的挖掘上,而對于Apriori_lift算法當參數值達到一定閾值時,改變參數值對其挖掘結果影響不大,改善了挖掘規則遺漏的情況。
由表4可以看出,Apriori算法和Apriori_lift算法的運行時間隨挖掘規則變化的比較情況。Apriori算法隨著挖掘結果中規則數的增長,時間上有數量級的提高,而Apriori_lift隨著時間的增長,其挖掘出的規則數量增幅不大。而Apriori_lift存在額外的作用度比較的開銷,在高支持度時,由于要處理的頻繁項目及模式數目都較少,此時從挖掘結果上看Apriori_lift表現了比Apriori更好的性能。



評論