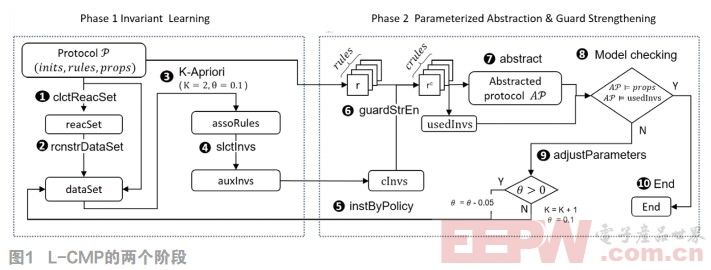
數據挖掘技術在中醫處方經驗研究中的應用

摘要:傳統的中醫藥科學在長期的醫療實踐中積累了海量的處方數據,數據挖掘是目前最有效的數據分析手段之一,利用數據挖掘技術從這些海量數據中發現蘊含其中的中醫藥知識,是一項極有價值的研究工作。本文主要采用數據挖掘中的Apriori關聯規則算法,對中醫處方數據進行挖掘和總結:首先對采集的中醫藥數據進行數字特征化處理;然后對中醫處方中藥物的頻繁項集和藥物之間的關聯關系進行研究,并獲得了普通處方分析較難獲得的用藥規律及經驗信息。研究成果對中醫臨床工作具有重要的指導意義。
本文引用地址:http://www.j9360.com/article/201603/287496.htm信息技術正在經歷著一次新的變革,互聯網、大數據等各種技術正在潛移默化的改變著人們的生活,數字化和數據化更是深深地影響著各行各業的每一個細節。很多信息早已開始儲存于各種類型的數據庫或者其他載體里,人們也已經開始從眾多數據中,找出有益的規律。人們的關注點已經由數據間的因果關系漸漸轉變為可以幫助我們捕獲現在和預測未來的相關關系[1],即挖掘事物之間的關聯性。中醫在長期的醫療實踐中積累了海量的處方數據,如何有效的分析這些數據并發現規律以指導臨床應用,成為中醫藥現代化研究中亟待解決的問題。數據挖掘作為一種有效的數據分析手段,已經在中醫藥領域中得到廣泛應用。
1 數據挖掘技術
1.1 數據挖掘概述
數據挖掘是從大量數據中挖掘有趣模式和知識的過程。從廣義上說,數據挖掘是對數據庫知識發現(Knowledge Discovery in Databases,KDD)的一個過程。作為一種通用技術,數據挖掘可以用于任何類型的數據,只要數據對目標應用是有意義的,數據源可以包括數據庫、數據倉庫、web、其他信息存儲庫或動態的流入系統的數據[2]。
1.2 中醫藥數據挖掘的意義
中醫藥領域的處方中通常包含大量的藥物及其劑量組成,伴隨著醫院信息化建設的大力推進,這些藥方多以數據庫形式被保存,運用數據挖掘技術對中藥數據進行科學分析,從而發現其中的配伍特點和規律成為很有現實意義的一項工作。
中醫藥數據挖掘的目的是通過對中醫處方中的中藥數據建立合適的模型,從而尋找藥物之間的頻繁模式和關聯規則,可以實現中醫用藥經驗的有效總結和傳承。
1.3 關聯規則算法
數據挖掘有很多模式,常見有關聯規則[3]、聚類算法[4]、分類算法[5]等。關聯規則挖掘最初僅限于事務數據庫的布爾型關聯規則,近年來廣泛應用于關系數據庫[6]。關聯規則反映一個事物與其他事物之間的相互依存性和關聯性。如果兩個或者多個事物之間存在一定的關聯關系,那么其中一個事物就能夠通過其他事物預測到。
關聯規則就是支持度和信任度分別滿足用戶給定閾值的規則。Apriori[7]是關聯規則模型中的經典算法。本文主要使用基于頻繁項集的Apriori算法進行數據建模,用以發現中藥配伍中的規律性。發現關聯規則需要經歷如下兩個步驟:
步驟一:通過迭代,檢索出事務數據庫中的所有頻繁項集,即支持度不低于用戶設定的閾值的項集;
步驟二:利用頻繁項集構造出滿足用戶最小信任度的規則。
2 數據特征化和預處理
2.1 實驗數據集
本文實驗數據來自河北中醫學院附屬醫院腎內科陳志強教授于2014年5月至2015年7月診治的早中期慢性腎衰竭患者的病案。采集的病案內容包括患者姓名、性別、年齡、原發病、癥狀、體征、腎功能指標、中醫證候、中藥處方等。摘取其中的中藥信息,按照《中藥大辭典》[8]統一藥物名稱。

2.2 數據特征化
統計數據集的全部223條中醫處方,共出現中藥194味,根據專業經驗,我們選取頻數在10%以上的中藥(視為高頻藥物)進行數據挖掘。由于中藥處方中的中藥名稱以中文形式表示,因此需要將其進行易于數據挖掘算法識別的數據特征化處理,方法如下:
(一) 藥物表的特征化方法
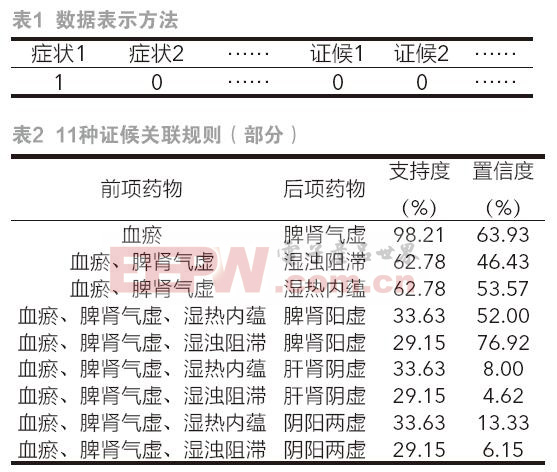
根據醫務工作者的經驗,將治療該病癥的常見中藥分為活血化瘀通經類、清熱祛濕泄濁類、行氣燥濕化痰類、益氣健脾溫陽類、補益脾腎之陽類、滋養肝腎之陰類等六大類。將高頻藥物分別歸于這六大類中,針對每大類建立相應的數據表。每條數據采用布爾常量的表示形式如圖1所示。
其中,第一項表示病人編號,每一條記錄表示一位病人的用藥信息,編號之后的每一位布爾數據表示某味中藥是否在該處方中出現,1表示出現,0表示未出現。
(二) 類別表的特征化方法
為了進一步分析各大類之間的關聯性,建立一個數據類別表(同一條處方中出現某一類藥物中兩味或兩味以上,即判定使用了該類別中藥)。每條記錄表示一位病人用藥的類別信息,其中第一項表示病人編號,編號之后的每一位表示該類別藥物是否在該處方中使用,1表示使用,0表示未使用。
按照上述方法建成中藥藥物數據庫,其中包括:包含所有藥物的處方數據集、統計藥物頻次的藥物計數數據集、由專業醫生按照性味、功用劃分的六種不同類別的高頻藥物數據集以及判斷處方中是否使用某類藥物的類別數據集。

3 中醫處方經驗的挖掘方法
3.1 對每一類藥物中包含的各味中藥進行關聯規則建模
首先對數據庫中的藥物進行頻數統計,即在處方中出現的次數;然后將數據庫中所有同類別的藥物按照其在整體處方中出現的頻數降序排列。如果藥物排列靠前說明其在處方中出現頻率較高,為醫生的常用中藥,具有較高的參考價值。同時,參考專業醫生的經驗,本文將支持度和置信度的閾值均設置為10%,將其視為指導臨床應用意義較大。對各類藥物數據采用Apriori算法建模,生成每一類別中藥間的關聯規則。
3.2 對六類藥物之間進行關聯性規則建模
逐條分析223條中藥處方中所包含的藥物類別(同一條處方中出現某一類藥物兩味或兩味以上,即認定含有該類別中藥),統計223條中藥處方中每一類別藥物的應用頻數,將其在數據庫中由高到低依次排列。根據專業醫生的經驗,設置支持度和置信度的閾值均為10%,將其視為指導臨床應用意義較大。對類別數據采用Apriori算法建模,生成六類中藥其類別之間的關聯規則。

4 關聯性分析
4.1 同類別中藥的關聯分析
將關聯規則按照支持度降序排序,體現出常用藥對以及多味中藥同時出現的規律。以第一大類藥物為例,通過對關聯規則的統計分析發現:在此類中藥處方中,三味中藥同時出現的概率高達65%;四味中藥中藥同時出現的概率大約在31%左右;五味中藥同時出現的概率減少到14%左右;六味中藥同時出現的概率驟減到1%;而七味及以上中藥同時出現的概率則為0。第一類藥物的部分關聯規則如表1。
對同一類藥物,本文采用定向網絡關系圖表示藥對之間的關系。連接兩位中藥之間的連線越粗,表明這個藥對出現在處方中的頻數越高;越細就表明這個藥對出現在處方中的頻率越低。圖2所示為輸出第一類藥物中頻數最高的中藥與其它各味中藥的關聯關系的定向網絡圖。
結論分析:
縱觀全部類別的所有頻繁項集,發現在各類藥物中,往往是同類別藥物多味聯用,以增強其功效;而在聯用時,又會有一定的味數限制,數目通常為三味至五味為多。通過定向網絡圖可以分析出針對某一種藥物與其它中藥成對出現的規律:由處方中頻數高的藥物組成的藥對,其之間的關聯關系更為密切。
4.2 不同類別藥物之間的關聯性分析
在223條有效的類別數據記錄中,生成的規則總數為154條,為了便于結果分析,將其按照支持度降序排列。通過對關聯規則的統計分析得出:前兩類藥的支持度高達95.5%;前三類藥的支持度為89%;前四類藥的支持度為70.9%;前五類藥的支持度驟減到25.6%;而全部六類藥的支持度僅為5.8%。現僅摘取前項含有前兩類中藥的關聯規則見表2。

結論分析:
前四類中藥之間的相互關系最為密切,其次是這四類中藥分別與第五、六類之間的關系,而第五、六類中藥之間關系的密切程度則大大降低。從關聯規則的結果可以分析得出前四個類別的藥物屬于常用和聯用的藥物。
5 結語
本文通過對中藥數據集的特征化處理,采用基于頻繁項集的Apriori經典關聯規則算法,對中醫處方中藥物的頻繁項集和藥物之間的關聯關系進行了有益的探索,發現了常用藥物組合及配伍特點,獲得了普通處方分析較難獲得的處方經驗信息。實驗結果證明:使用關聯規則對中藥數據庫建模,可以挖掘出中醫在治療某種疾病方面的用藥特點,為研究臨床用藥規律提供了有效方法。
參考文獻:
[1]Viktor Mayer-Schonberger Kenneth Cukier盛楊燕,周濤 譯 大數據時代[M].浙江人民出版社.2013.1
[2]jiaweihanMichelineKamber Jian Pei. 數據挖掘概念與技術[M].范明 孟曉峰 譯.機械工業出版社.2012: 243
[3]毛宇星,陳彤兵,施伯樂. 一種高效的多層和概化關聯規則挖掘方法[J].軟件學報, 2011,22(12):2965-2980.
[4] 陳克寒,韓盼盼,吳建.基于用戶聚類的異構社交網絡推薦算法[J]計算機學報,2013,36(2):350-359
[5]張琳,陳燕,李桃迎.決策樹分類算法研究[J].2011,37(13):66-68
[6]楊秀萍.大數據下關聯規則算法的改進及應用[J].計算機與現代化,2014,(12):23-27
[7] AGRWAL R,SRIKAN R.Fast algorithms for mining association rules in large databases[C]/Proceedings of the 20th International Conference on Very Large Data Bases.San Francisco: Morgan Kaufmann Publishers, 1994:487—499.
[8]江蘇新醫學院.中藥大辭典.上海:上海科學技術出版社,1986.
本文來源于中國科技期刊《電子產品世界》2016年第2期第37頁,歡迎您寫論文時引用,并注明出處。


評論