基于改進遺傳算法的支持向量機特征選擇

引言
本文引用地址:http://www.j9360.com/article/105942.htm支持向量機是一種在統計學習理論的基礎上發展而來的機器學習方法[1],通過學習類別之間分界面附近的精確信息,可以自動尋找那些對分類有較好區分能力的支持向量,由此構造出的分類器可以使類與類之間的間隔最大化,因而有較好的泛化性能和較高的分類準確率。由于支持向量機具有小樣本、非線性、高維數、避免局部最小點以及過學習現象等優點,所以被廣泛運用于故障診斷、圖像識別、回歸預測等領域。但是如果缺少了對樣本進行有效地特征選擇,支持向量機在分類時往往會出現訓練時間過長以及較低的分類準確率,這恰恰是由于支持向量機無法利用混亂的樣本分類信息而引起的,因此特征選擇是分類問題中的一個重要環節。特征選擇的任務是從原始的特征集合中去除對分類無用的冗余特征以及那些具有相似分類信息的重復特征,因而可以有效降低特征維數,縮短訓練時間,提高分類準確率。
目前特征選擇的方法主要有主成分分析法、最大熵原理、粗糙集理論等。然而由于這些方法主要依據繁復的數學理論,在計算過程中可能存在求導和函數連續性等客觀限定條件,在必要時還需要設定用來指導尋優搜索方向的搜索規則。遺傳算法作為一種魯棒性極強的智能識別方法,直接對尋優對象進行操作,不存在特定數學條件的限定,具有極好的全局尋優能力和并行性;而由于遺傳算法采用概率化的尋優方法,所以在自動搜索的過程中可以自主獲取與尋優有關的線索,并在加以學習之后可以自適應地調整搜索方向,不需要確定搜索的規則。因此遺傳算法被廣泛應用在知識發現、組合優化、機器學習、信號處理、自適應控制和人工生命等領域。
基于改進遺傳算法的特征選擇
遺傳算法是一種新近發展起來的搜索最優化算法[2~5]。遺傳算法從任意一個的初始生物種群開始,通過隨機的選擇、交叉和變異操作,產生一群擁有更適應自然界的新個體的新一代種群,使得種群的進化趨勢向著最優的方向發展。圖1中所示的是標準的遺傳算法的流程框圖。
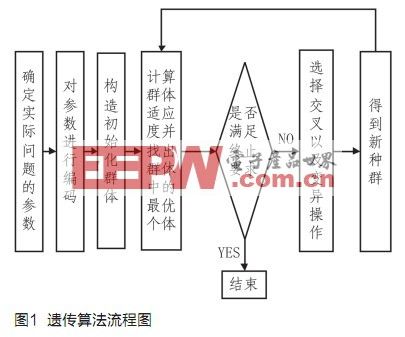
傳統的遺傳算法存在早熟收斂、非全局收斂以及后期收斂速度慢的缺點,為此本文提出了一種能夠在進化過程中自適應調節變異率,以及利用模擬退火防止早熟的改進遺傳算法,同時該算法利用敏感度信息可以有效地控制遺傳操作。圖2是改進遺傳算法的流程框圖。



評論