非特定人車載音響語音控制系統

隨著現代電子技術在汽車系統中的不斷應用,越來越多的車載電器加入到車身電子行列中,使得汽車的各種性能都得到了極大的改善,但汽車駕駛室的開關也越來越多,這就為駕駛員行車中對車載電器的操作提出了更高的要求,同時也給行車過程帶來了不安全的隱患。隨著語音識別算法的改進和新一代Soc專用語音處理芯片的問世,使用語音命令控制汽車電器的操作能夠部分用口代替手的功能,從而減輕駕駛員操作負擔,提高行車安全系數。
本文引用地址:http://www.j9360.com/article/270513.htm目前我國的車身電子語音控制主要集中在汽車導航系統的應用上,沒有充分發揮語音識別技術在車身電子中的應用價值。本文提出了一種的以專用語音處理芯片UniSpeech-SDA80D51為核心控制車載音響操作的設計方案,并在SL1102C1型車載音響上實現了對非特定人的語音識別與控制。
語音控制器硬件
車載語音控制器系統由定向拾音器、語音識別模塊、控制模塊和音響模塊組成。系統的功能是:由拾音器采集駕駛員發出的語音命令,利用語音識別模塊將拾音器輸出的語音物理聲音信號轉變成語音數字信號,并識別出語音命令對應的漢字或詞語,之后由控制模塊產生與之對應的詞條編碼指令,通過系統I/O口線將控制命令傳達給音響,車載音響接收到控制指令產生動作,響應駕駛員的語音命令,比如快進、快退或音量調節等。系統結構及原理框圖如圖1所示:
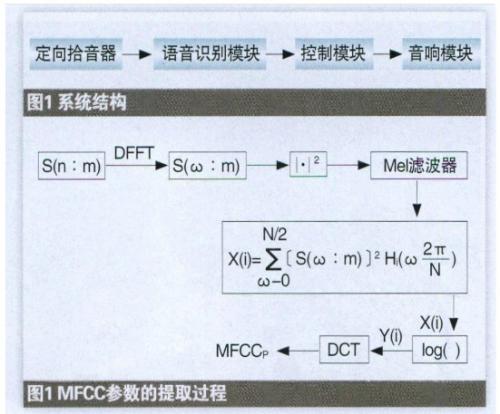
語音識別模塊主要由UniSpeech-SDA80D51芯片及外圍電路組成。本模塊主要實現對輸入的非特定人語音信號的識別和處理功能,輸出與語音命令對應的詞條編碼。
SDA80D51是Infineon公司專為語音識別和語音處理應用領域新推出的專用芯片,采用高集成度的Soc系統結構以0.18μm半導體工藝制造,擁有8位高速增強型M8051核心(25MIPS)和16位定點DSP核心OAK(100MIPS)的雙核架構,片內集成了直接雙訪問快速SRAM、2路ADC和2路DAC(有效精度為12Bit)、多種通信接口和通用GPIO等設備,外部只需擴展Flash存儲器等少量外圍電路即可構成完整應用系統。
控制模塊由MCU和模擬開關電路構成,本模塊主要完成對語音識別模塊輸出的識別結果——詞條編碼信號進行邏輯分析和處理,通過模擬開關電路產生對應功能的控制信號輸出到音響,控制音響的操作。其中MCU選用美國ATMEL公司產品AT89S51,由于車載音響SL1102C1上的按鍵控制面板為電阻式分流鍵盤電路,采用電壓采樣識別模式,對不同鍵值進行識別,綜合SDA80D51芯片輸出的I/O電壓特性,確定使用繼電器模擬SL1102C1控制面板按鍵的閉合和斷開動作。
本設計是基于安徽森力公司的SL1102C1汽車音響。SL1102C1是專門為中檔轎車設計的汽車音響,具有MP3播放、收音機和顯示時間等功能,目前大量使用在江淮同悅轎車上。SL1102C1前板共有15個按鍵和一個用來調節音量的編碼開關。分別為開關機/靜音、音效設置、6個臺位、播放/暫停、隨機播放、重復播放、瀏覽播放、選擇下曲(快進)、選擇上曲(快退)、向下搜臺/上一曲、向上鎖臺/下一曲、模式轉換、電臺瀏覽/自動存儲臺、波段切換、顯示時間/時間設置和復位等功能。
音響前板上的按鍵為電壓采樣識別方式,按鍵包含短按(延時小于0.2s)和長按(延時大于1s)兩種動作,控制模塊MCU(AT89S51)的輸出電壓為TTL電平,直接采用MCU信號驅動音響按鍵動作容易引起誤識別,造成系統誤操作,因此本文采用模擬開關電路,很好地解決了上述問題。當AT89S51接收到語音模塊輸出的一個語音命令識別結果編碼信號后,立即進行邏輯分析并輸出對應的控制信號驅動相應繼電器吸合模擬按鍵動作,按鍵的短按和長按功能是通過軟件實現的。
系統軟件設計
系統的軟件包括:非特定人語音識別模塊和邏輯控制模塊。
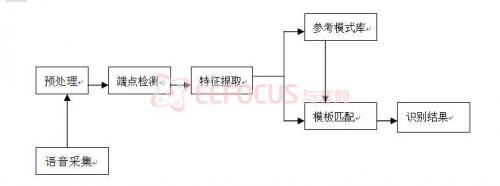
非特定人語音識別模塊基于HMM模型算法。該算法通過對大量語音數據進行數據統計,建立識別詞條的統計模型語音庫,然后從待識別語音中提取特征,與模型庫進行匹配,由比較匹配分數得到識別結果,并通過SDA80D51的GPIO口輸出識別結果對應的詞條編碼信號。語音識別模塊主要由信號預處理、特征參數提取、模型匹配和Viterbi算法部分組成。
信號預處理部分主要完成輸入語音信號的采樣、模/數轉換功能。A/D變換由SDA80D51內嵌12位A/D變換器實現,采樣頻率固定為8 kHz.
特征參數提取基于語音幀,采用分幀提取特片。先對語音信號進行重疊分幀,前一幀和后一幀重疊一半(幀信號重疊是體現相鄰兩幀數據之間的相關性),幀長為25ms,對每幀提取一次語音特片。
MFCC參數屬于感知頻域倒譜參數,反映了語音信號短時幅度譜的特征。p維MFCC參數的提取過程如圖1所示。
其中:m是幀號,N是單位幀內的采樣點數。
HMM是描述語音信號的一種概率統計模型,使用MarKov鏈來模擬語音信號統計特性的變化,HMM模型是在Markov鏈的基礎上發展起來的。
Viterbi算法是一種幀同步動態規整算法,在給定觀察值序列和模型時,Viterbi算法給出了一個概率密度P(Q,O |λ)最大的狀態序列。
控制模塊的主要功能是:在單片機查詢到語音模塊輸出的語音詞條信號后,查表獲得詞條編碼,根據編碼判斷對應按鍵是長按或短按,分別進入相應的子程序處理,長按子程序延時1s,短按子程序延時0.2s.在子程序中,輸出語音命令所對應的I/O控制信號驅動繼電器吸合模擬按鍵或編碼開關動作,并及時復位I/O口。為了避免語音控制和手動控制之間沖突,語音控制模塊可以完全兼容于手動控制,在語音控制操作時,同時可以進行手動控制。
實驗結果及結論
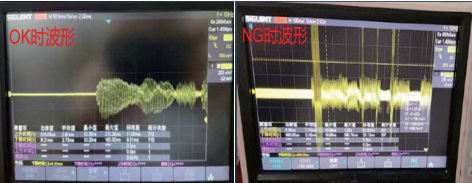
本系統的樣機實驗主要是測試非特定人的語音識別率和模擬開關動作的準確率。由于汽車音響的語音詞條為2~4個字,語音識別率實驗內容為車載音響常用2字詞條指令18條、3字詞條指令12條、4字詞條指令10條,實驗對象為6人4男、2女(普通話和方言),實驗環境為噪聲干擾環境和相對安靜環境,樣機測試結果如表1所示。


dc相關文章:dc是什么







評論