ZLG深度解析語音識別技術

語音識別已成為人與機器通過自然語言交互重要方式之一,本文將從語音識別的原理以及語音識別算法的角度出發為大家介紹語音識別的方案及詳細設計過程。
本文引用地址:http://www.j9360.com/article/201903/398163.htm語言作為人類的一種基本交流方式,在數千年歷史中得到持續傳承。近年來,語音識別技術的不斷成熟,已廣泛應用于我們的生活當中。語音識別技術是如何讓機器“聽懂”人類語言?本文將為大家從語音前端處理、基于統計學語音識別和基于深度學習語音識別等方面闡述語音識別的原理。
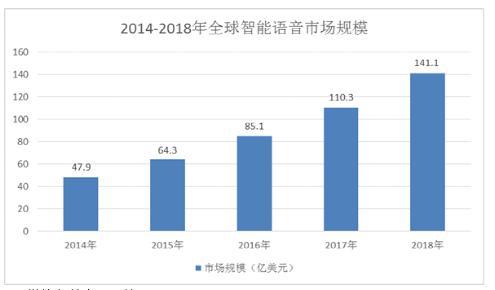
隨著計算機技術的飛速發展,人們對機器的依賴已經達到一個極高的程度。語音識別技術使得人與機器通過自然語言交互成為可能。最常見的情形是通過語音控制房間燈光、空調溫度和電視的相關操作等。并且,移動互聯網、智能家居、汽車、醫療和教育等領域的應用帶動智能語音產業規模持續快速增長, 2018年全球智能語音市場規模將達到141.1億美元。
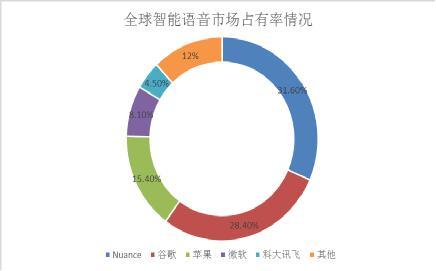
目前,在全球智能語音市場占比情況中,各巨頭市場占有率由大到小依次為:Nuance、谷歌、蘋果、微軟和科大訊飛等。
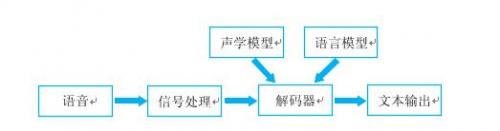
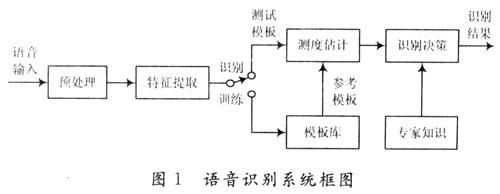
語音識別的本質就是將語音序列轉換為文本序列,其常用的系統框架如下:
接下來對語音識別相關技術進行介紹,為了便于整體理解,首先,介紹語音前端信號處理的相關技術,然后,解釋語音識別基本原理,并展開到聲學模型和語言模型的敘述,最后,展示我司當前研發的離線語音識別demo。
1.前端信號處理
前端的信號處理是對原始語音信號進行的相關處理,使得處理后的信號更能代表語音的本質特征,相關技術點如下表所述:
1)語音活動檢測
語音活動檢測(Voice Activity Detection, VAD)用于檢測出語音信號的起始位置,分離出語音段和非語音(靜音或噪聲)段。VAD算法大致分為三類:基于閾值的VAD、基于分類器的VAD和基于模型的VAD。
基于閾值的VAD是通過提取時域(短時能量、短時過零率等)或頻域(MFCC、譜熵等)特征,通過合理的設置門限,達到區分語音和非語音的目的。
基于分類的VAD是將語音活動檢測作為(語音和非語音)二分類,可以通過機器學習的方法訓練分類器,達到語音活動檢測的目的。
基于模型的VAD是構建一套完整的語音識別模型用于區分語音段和非語音段,考慮到實時性的要求,并未得到實際的應用。
2)降噪
在生活環境中通常會存在例如空調、風扇等各種噪聲,降噪算法目的在于降低環境中存在的噪聲,提高信噪比,進一步提升識別效果。
常用降噪算法包括自適應LMS和維納濾波等。
3)回聲消除
回聲存在于雙工模式時,麥克風收集到揚聲器的信號,比如在設備播放音樂時,需要用語音控制該設備的場景。
回聲消除通常使用自適應濾波器實現的,即設計一個參數可調的濾波器,通過自適應算法(LMS、NLMS等)調整濾波器參數,模擬回聲產生的信道環境,進而估計回聲信號進行消除。
4)混響消除
語音信號在室內經過多次反射之后,被麥克風采集,得到的混響信號容易產生掩蔽效應,會導致識別率急劇惡化,需要在前端處理。
混響消除方法主要包括:基于逆濾波方法、基于波束形成方法和基于深度學習方法等。
5)聲源定位
麥克風陣列已經廣泛應用于語音識別領域,聲源定位是陣列信號處理的主要任務之一,使用麥克風陣列確定說話人位置,為識別階段的波束形成處理做準備。
聲源定位常用算法包括:基于高分辨率譜估計算法(如MUSIC算法),基于聲達時間差(TDOA)算法,基于波束形成的最小方差無失真響應(MVDR)算法等。
6)波束形成
波束形成是指將一定幾何結構排列的麥克風陣列的各個麥克風輸出信號,經過處理(如加權、時延、求和等)形成空間指向性的方法,可用于聲源定位和混響消除等。
波束形成主要分為:固定波束形成、自適應波束形成和后置濾波波束形成等。
2.語音識別的基本原理
已知一段語音信號,處理成聲學特征向量之后表示為![]() ,其中表示一幀數據的特征向量,將可能的文本序列表示為
,其中表示一幀數據的特征向量,將可能的文本序列表示為![]() ,其中表示一個詞。語音識別的基本出發點就是求
,其中表示一個詞。語音識別的基本出發點就是求![]() ,即求出使
,即求出使![]() 最大化的w文本序列。將
最大化的w文本序列。將![]() 通過貝葉斯公式表示為:
通過貝葉斯公式表示為:

其中,![]() 稱之為聲學模型,
稱之為聲學模型,![]() 稱之為語言模型。大多數的研究將聲學模型和語言模型分開處理,并且,不同廠家的語音識別系統主要體現在聲學模型的差異性上面。此外,基于大數據和深度學習的端到端(End-to-End)方法也在不斷發展,它直接計算
稱之為語言模型。大多數的研究將聲學模型和語言模型分開處理,并且,不同廠家的語音識別系統主要體現在聲學模型的差異性上面。此外,基于大數據和深度學習的端到端(End-to-End)方法也在不斷發展,它直接計算![]() ,即將聲學模型和語言模型作為整體處理。本文主要對前者進行介紹。
,即將聲學模型和語言模型作為整體處理。本文主要對前者進行介紹。
3.聲學模型
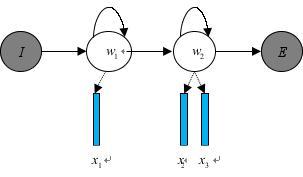
聲學模型是將語音信號的觀測特征與句子的語音建模單元聯系起來,即計算![]() 。我們通常使用隱馬爾科夫模型(Hidden Markov
Model,HMM)解決語音與文本的不定長關系,比如下圖的隱馬爾科夫模型中,
。我們通常使用隱馬爾科夫模型(Hidden Markov
Model,HMM)解決語音與文本的不定長關系,比如下圖的隱馬爾科夫模型中,
將聲學模型表示為
其中,初始狀態概率![]() 和狀態轉移概率(
和狀態轉移概率(![]() 、
、![]() )可用通過常規統計的方法計算得出,發射概率(
)可用通過常規統計的方法計算得出,發射概率(![]()
、![]() 、
、![]() )可以通過混合高斯模型GMM或深度神經網絡DNN求解。
)可以通過混合高斯模型GMM或深度神經網絡DNN求解。
傳統的語音識別系統普遍采用基于GMM-HMM的聲學模型,示意圖如下:
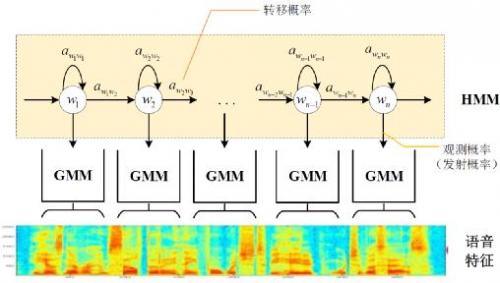
其中,![]() 表示狀態轉移概率
表示狀態轉移概率![]() ,語音特征表示
,語音特征表示![]() ,通過混合高斯模型GMM建立特征與狀態之間的聯系,從而得到發射概率
,通過混合高斯模型GMM建立特征與狀態之間的聯系,從而得到發射概率![]() ,并且,不同的狀態
,并且,不同的狀態![]() 對應的混合高斯模型參數不同。
對應的混合高斯模型參數不同。
基于GMM-HMM的語音識別只能學習到語音的淺層特征,不能獲取到數據特征間的高階相關性,DNN-HMM利用DNN較強的學習能力,能夠提升識別性能,其聲學模型示意圖如下:
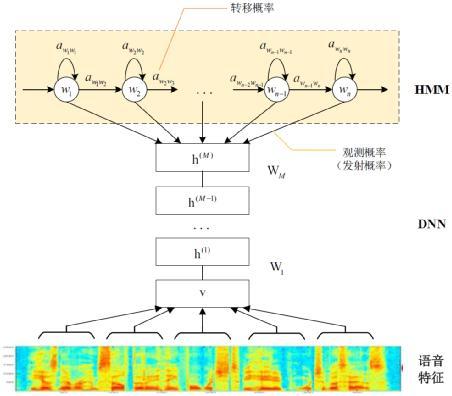
GMM-HMM和DNN-HMM的區別在于用DNN替換GMM來求解發射概率![]()
,GMM- HMM模型優勢在于計算量較小且效果不俗。DNN-HMM模型提升了識別率,但對于硬件的計算能力要求較高。因此,模型的選擇可以結合實際的應用調整。
4.語言模型
語言模型與文本處理相關,比如我們使用的智能輸入法,當我們輸入“nihao”,輸入法候選詞會出現“你好”而不是“尼毫”,候選詞的排列參照語言模型得分的高低順序。
語音識別中的語言模型也用于處理文字序列,它是結合聲學模型的輸出,給出概率最大的文字序列作為語音識別結果。由于語言模型是表示某一文字序列發生的概率,一般采用鏈式法則表示,如w是由![]() 組成,則
組成,則![]() 可由條件概率相關公式表示為:
可由條件概率相關公式表示為:
![]()
由于條件太長,使得概率的估計變得困難,常見的做法是認為每個詞的概率分布只依賴于前幾個出現的詞語,這樣的語言模型成為n-gram模型。在n-gram模型中,每個詞的概率分布只依賴于前面n-1個詞。例如在trigram(n取值為3)模型,可將上式化簡:
5.語音識別效果展示
基于PC的語音識別展示demo如下視頻所示:
此處插入視頻zal_asr_demo_video.mp4
視頻包括使用“小致同學”喚醒設備,設備喚醒之后有12秒時間進行語音識別控制,空閑時間超過了12秒將再次休眠。
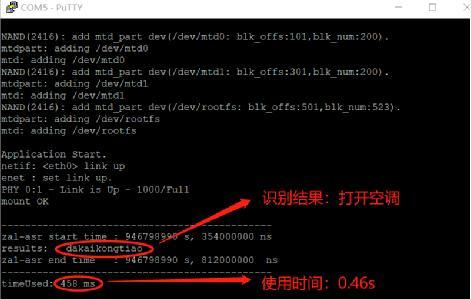
我們的語音識別算法已經部分移植到了基于AWorks的cortex-m7系列M1052-M16F12 8AWI -T平臺。語音識別的聲學模型和語言模型是我司訓練的用于測試智能家居控制的相關模型demo,在支持65個常用命令詞的離線識別測試中(數量越大識別所需時間越長),使用讀取本地音頻文件的方式進行語音識別“打開空調”所需時間0.46s左右。下面是在M1052-M16F128AWI- T的實測效果:
最后附上M1052-M16F128AWI-T產品圖片:

6.關于算法庫獲取
目前語音識別系統處于研發階段,廣大客戶可將自身需求反饋給廣州立功科技股份有限公司與立功科技·致遠電子相關市場人員,我們會以最快速度研發客戶需要的產品。



評論