什么決定了訓練 AI 所需的數據集的大小?

訓練人工智能 (AI) 算法需要大型數據集,而且它們可能很昂貴。那么,多少數據才足夠呢?問題的復雜性、模型的復雜性、數據的質量以及所需的準確性水平主要決定了這一點。
本文引用地址:http://www.j9360.com/article/202504/469557.htm數據增強技術可以增加數據集的大小,而學習曲線分析可以確定何時優化了訓練結果。
問題復雜性是影響所需數據集大小的一個主要因素。圖像識別很復雜,并且需要比簡單圖像分類更大的訓練數據集。此外,具有更多特征的問題需要更多的訓練示例來學習所有可能的關系。
模型復雜性也很重要,具有更多參數的深度學習模型可能需要非常大的數據集才能進行有效學習。一個常見的經驗法則是 “10 法則”,它指出有效的訓練需要的數據點是模型中參數數量的 10 倍。
數據質量和增強
噪聲最小或不一致的數據是“高質量”訓練數據。獲取大量高質量數據可能很困難,但可以擴充較小的數據集以人為地增加數據集的大小。
Argumentation 可用于所有類型的數據。即使是看似微小的更改也足夠了。例如,圖像數據集的有效增強形式可以包括裁剪、反射、旋轉、縮放、平移或添加高斯噪聲,如圖 1 所示。
 圖 1.一個原始圖像示例(左)和四個其他圖像是使用數據增強技術得出的。(圖片:Nexocode)
圖 1.一個原始圖像示例(左)和四個其他圖像是使用數據增強技術得出的。(圖片:Nexocode)
欠擬合和過擬合
偏差和方差指標可用于確定 AI/ML 模型的質量。偏差是與過于簡單的模型(也稱為欠擬合)相關的預測誤差,而高方差表示模型過于復雜(過度擬合),并且除了數據本身之外,還會考慮數據集中的“噪聲”。
理想的模型具有低偏差和低方差。這兩個指標可以被認為是獨立的,如圖 2 所示。但是,對于 AI/ML 模型,它們往往成反比,增加一個模型會導致另一個模型減少。這被稱為 “偏差-方差權衡”,是確定模型訓練成功與否時學習曲線分析中的一個重要考慮因素。
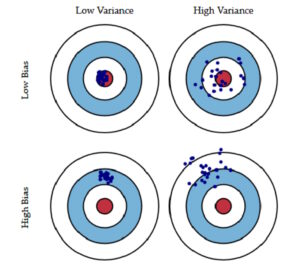
圖 2.AI/ML 模型旨在產生偏差和方差的理想組合(左上角目標)。(圖片:Analytics Vidhya)
時期和學習曲線分析
紀元表示使用給定數據集訓練 AI/ML 模型的完整周期。Epochs 還用于學習曲線分析,以確定最佳訓練周期數。
學習曲線分析很重要,因為所需的 epoch 數可以達到數千個。但是,使用更多的 epoch 來 “優化” 結果并不是更好,因為訓練太多 epoch 會導致過度擬合。
學習曲線在 x 軸上繪制數據量(通常是時期),在 y 軸上繪制模型的準確性(或其他性能指標)。學習曲線分析將訓練結果與一組驗證數據進行比較。驗證數據可以是獨立的數據集,也可以是不用于訓練的訓練數據集的子集。
分析限制
并非所有模型在偏差和方差之間都具有相同的關系。這可能使確定最佳模型變得具有挑戰性。
通常,當偏差和方差的組合達到全局最小值時,可以確定最佳模型,如圖 3a 所示。對于某些模型,方差的增加速度可能慢于偏差的減少速度(圖 3b),并且確定最佳模型可能并不那么簡單。在這些情況下,新的或改進的模型可能會提供更好的結果。
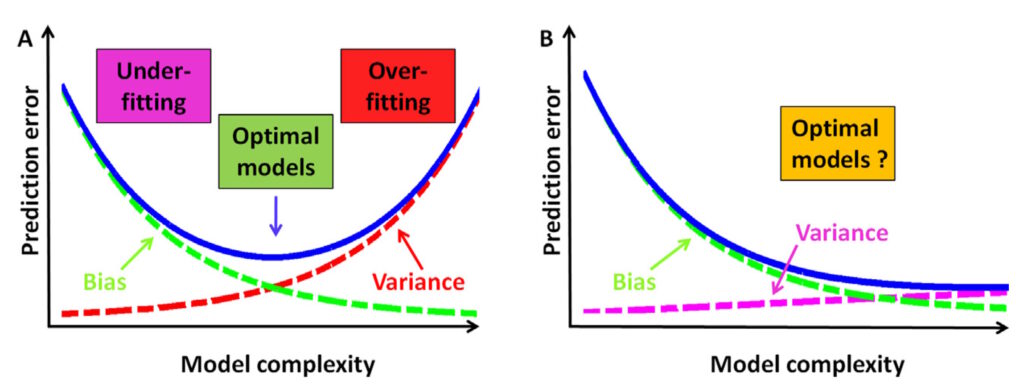 圖 3.偏差和方差之間的關系并不總是可以依靠來確定最佳模式。(Analytica Chimica Acta)
圖 3.偏差和方差之間的關系并不總是可以依靠來確定最佳模式。(Analytica Chimica Acta)
總結
“10 法則”可以為確定 AI/ML 訓練所需的數據量提供一個起點。使用增強技術可以以低成本擴展數據可用性。可以使用學習曲線來分析訓練結果,但找到最佳模型并不總是那么簡單,可能需要調整或替換。

評論