Arm KleidiAI 助力提升 PyTorch 上 LLM 推理性能

作者:Arm 基礎設施事業部軟件工程師 Nobel Chowdary Mandepudi
本文引用地址:http://www.j9360.com/article/202412/465428.htm生成式人工智能 (AI) 正在科技領域發揮關鍵作用,許多企業已經開始將大語言模型 (LLM) 集成到云端和邊緣側的應用中。生成式 AI 的引入也使得許多框架和庫得以發展。其中,PyTorch 作為熱門的深度學習框架尤為突出,許多企業均會選擇其作為開發 AI 應用的庫。通過部署 Arm Kleidi 技術 ,Arm 正在努力優化 PyTorch,以加速在基于 Arm 架構的處理器上運行 LLM 的性能。Arm 通過將 Kleidi 技術直接集成到 PyTorch 中,簡化了開發者訪問該技術的方式。
在本文中,我們將通過一個演示應用來展示 Arm KleidiAI 在 PyTorch 上運行 LLM 實現的性能提升。該演示應用在基于 Arm Neoverse V2 的亞馬遜云科技 (AWS) Graviton4 R8g.4xlarge EC2 實例上運行 Llama 3.1。如果你感興趣,可以使用以下 Learning Path,自行重現這個演示。 (Link: https://learn.arm.com/learning-paths/servers-and-cloud-computing/pytorch-llama)
演示應用
我們的演示應用是一個基于 LLM 的聊天機器人,可以回答用戶提出的各種問題。該演示使用 Arm 平臺上的 PyTorch 框架運行 Meta Llama 3.1 模型,并被設計成一個使用 Streamlit 前端的瀏覽器應用。Streamlit 將信息提供給 Torchat 框架,后者運行 PyTorch 并作為 LLM 后端。Torchat 輸出的信息進入注意力層并生成詞元 (token)。這些詞元使用 OpenAI 框架流式傳輸功能發送到前端,并在瀏覽器應用上顯示給用戶。該演示的架構下圖所示。
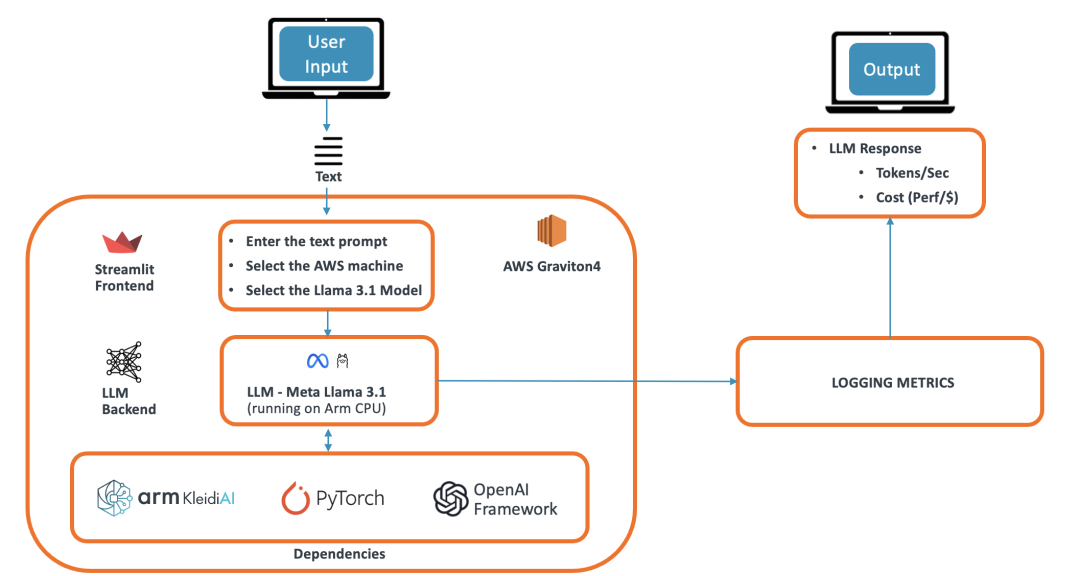
圖:演示架構
演示應用在 LLM 推理結束后測定并顯示以下性能指標:

生成首個詞元的用時(秒) :對于 LLM 推理,需要快速生成首個詞元,以盡量減少延遲并向用戶提供即時輸出。

解碼速度/文本生成(詞元/秒) :每秒詞元數是指生成式 AI 模型生成詞元的速率。生成下一個詞元的時間最長不超過 100 毫秒,這是交互式聊天機器人的行業標準。這意味著解碼速度至少為 10 個詞元/秒。這對于提升實時應用的用戶體驗至關重要。

生成百萬詞元的成本(美元) :根據 AWS 云端 EC2 實例的解碼速度和每小時成本,我們可以計算出生成 100 萬個詞元的成本,這也是一個常用的比較指標。由于每小時成本是固定的,解碼速度越快,生成百萬詞元的成本就越低。

生成提示詞的總用時(秒) :這是使用所有詞元生成提示詞所花費的總時間。

生成提示詞的總成本(美元) :這是根據使用所有詞元生成完整提示詞的總時間、解碼速度和云端機器成本計算得出的。
下圖顯示了示例響應,可作為使用所示指標驗證聊天機器人的示例。生成首個詞元的時間短于 1 秒,解碼速率為 33 個詞元/秒,這兩項數據都非常令人滿意,并且滿足交互式聊天機器人的行業標準。
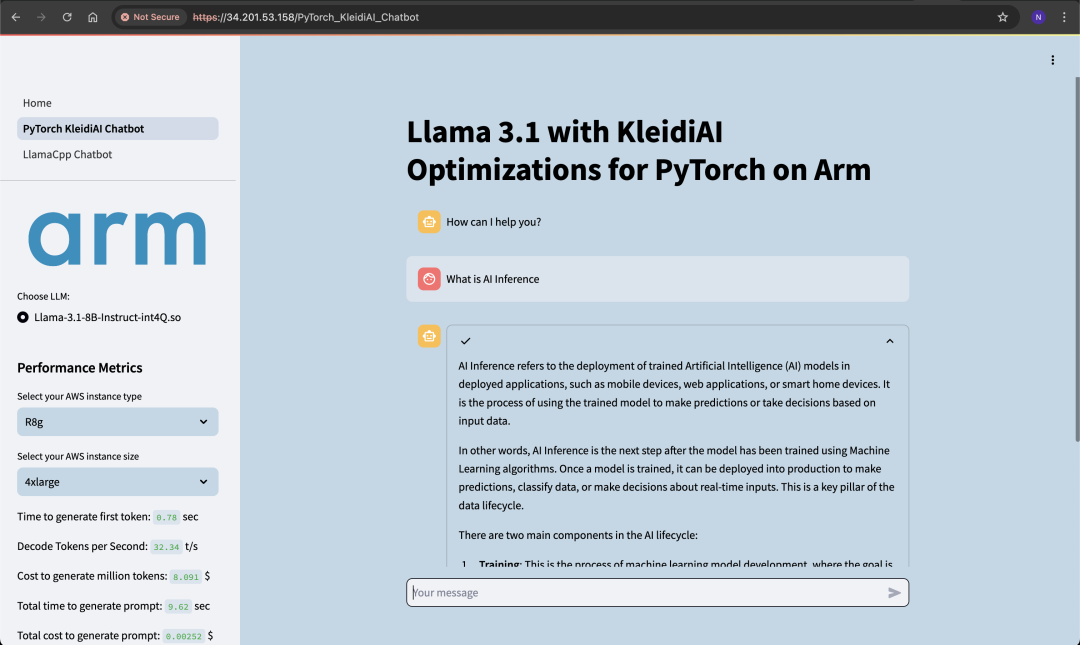
圖:包含示例響應和指標的演示
針對 PyTorch 的 KleidiAI 優化
KleidiAI 庫為 Arm 平臺提供了多項優化。Kleidi 在 Torch ATen 層中提供了一個新算子以加載模型。該層將模型權重以特定格式打包在內存中,使得 KleidiAI GEMM 內核可用來提高性能。同樣地,針對模型執行的優化使用了 ATen 層中的另一個算子。該算子對先前打包的模型權重進行 matmul 運算的量化。
在我們的演示中,該模型是從 Meta Hugging Face 庫下載的。該模型使用 INT4 內核布局打包在內存中,然后使用針對 PyTorch 優化的 INT4 KleidiAI 內核進行量化。該演示的架構如下圖所示。
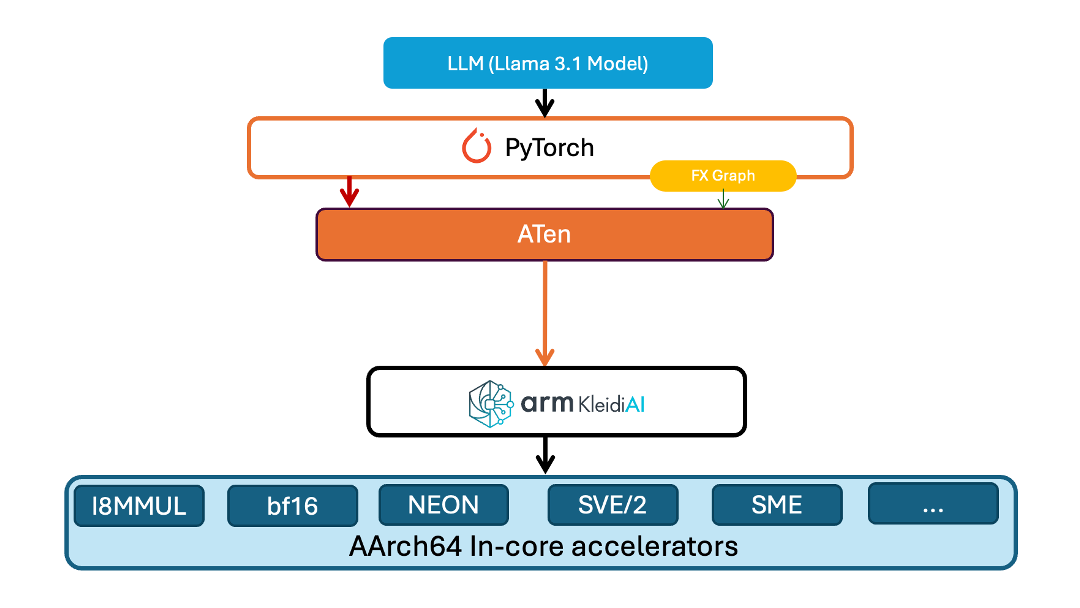
圖:針對 PyTorch 實現的 KleidiAI 優化
使用我們 Learning Path 中包含的補丁 [注] ,可將這些 KleidiAI 優化應用到 PyTorch、Torchchat 和 Torchao 中。你可以使用這些補丁來查看 Arm 平臺上的 PyTorch 為工作負載帶來的 LLM 推理性能提升。
注: Arm KleidiAI 的 PyTorch 補丁正在與上游 PyTorch 合并,并將在未來的 PyTorch 官方版本中提供。
性能
為了印證 KleidiAI 的性能優勢,我們使用 PyTorch 運行相同的聊天機器人應用,并測定了 KleidiAI 優化前后的每秒生成詞元數和生成首個詞元的用時,結果如下圖所示。
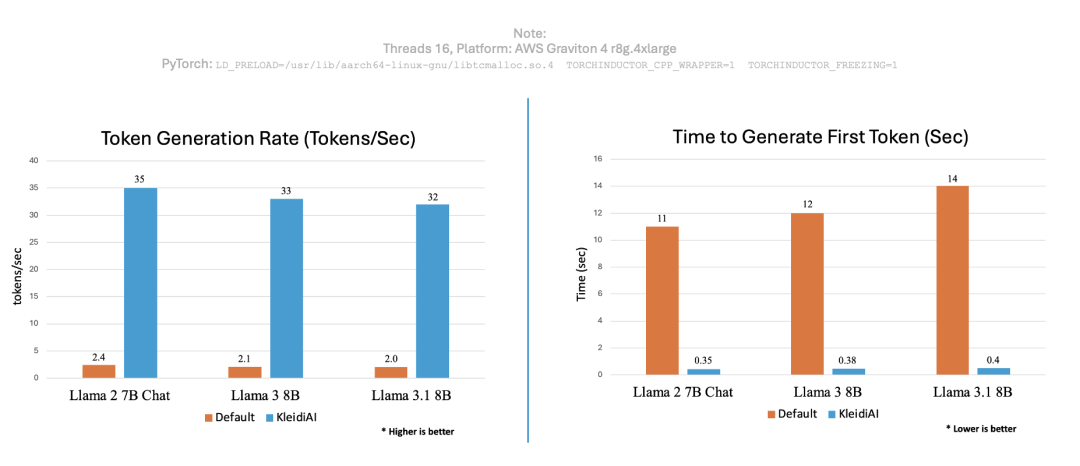
圖:性能比較
可以看到,將 KleidiAI 庫應用到現有的生成式 AI 技術棧中可以大大提高詞元生成速率,并縮短為不同生成式 AI 模型生成首個詞元的時間。
結論
對于聊天機器人等實時工作負載來說,在 CPU 上運行 LLM 推理可行且有效。我們在之前 《在基于 Arm Neoverse 的 AWS Graviton3 CPU 上實現出色性能》 文章中使用 Llama.cpp 演示了這一點。在本文中,我們展示了如何使用 KleidiAI 庫為 Arm 平臺上的 PyTorch 實現良好的 LLM 推理性能。通過使用搭載 Neoverse V2 核心且基于 AWS Graviton4 的 R8g 實例進行演示,印證了 KleidiAI 為在 Arm 平臺上使用 PyTorch 運行 LLM 推理實現了顯著的性能提升。開發者現在可以利用 Arm 針對 PyTorch 的 KleidiAI 優化來運行新的或現有的 AI 應用。







評論