銓興科技AI創新解決方案開啟“銓”民AI時代

當前,人工智能技術正以其獨特的魅力和巨大的潛力引領著新一輪科技革命。AI大模型的爆發帶動了GPU市場的繁榮,從云端到邊緣AI應用也催生邊緣AI服務器及AI加速處理器的巨大需求。
本文引用地址:http://www.j9360.com/article/202408/462395.htm在邊緣AI應用場景中,大數據與大模型的運算、推理依靠GPU的運行效能和帶寬,AI的訓練與微調依賴顯存容量。為支撐70B、405B甚至大于1000B模型的訓練與微調任務,現有市場方案依靠多顯卡集群的方式拼湊顯存與算力。現行的多顯卡集群方式投入成本昂貴,且高性能GPU算力卡國內限購,成本高,后續維護進階難,極大程度阻礙AI應用場景落地,導致無法充分賦能企業。
銓興科技的AI超大模型全參微調、訓推一體解決方案
深圳市銓興科技有限公司作為半導體存儲領域的解決方案供應商,憑借二十余年深厚的存儲技術底蘊與不懈的創新追求,結合AI人工智能技術原理,把存儲技術和算力在訓練超大模型全參微調、訓練推理方面有機結合,創新推出銓興超大模型AI訓推一體解決方案。
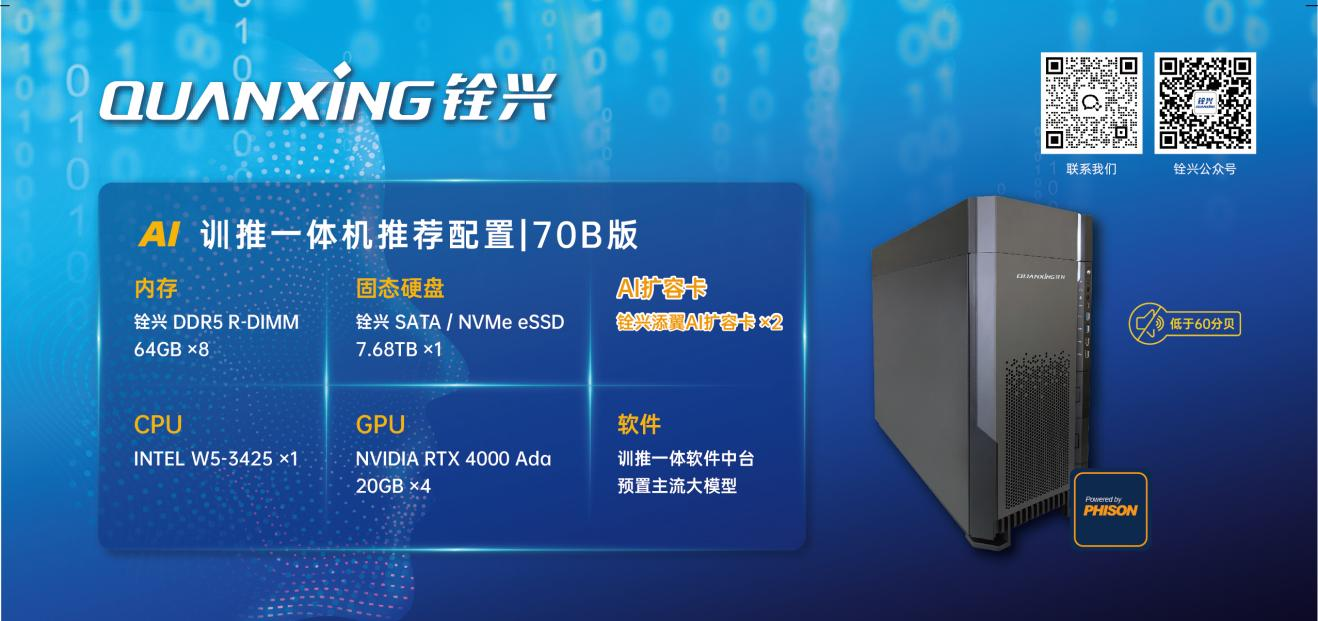
銓興超大模型AI訓推一體解決方案是由“銓興添翼AI擴容卡、企業級固態硬盤、服務器內存”等核心組件的AI訓推一體服務器解決方案,整體部署方案具備低成本、低功耗、安全等顯著優勢。

銓興科技創新推出的添翼AI擴容卡,通過優化中間層驅動,打破顯存墻,使得GPU可用顯存空間直升20倍!
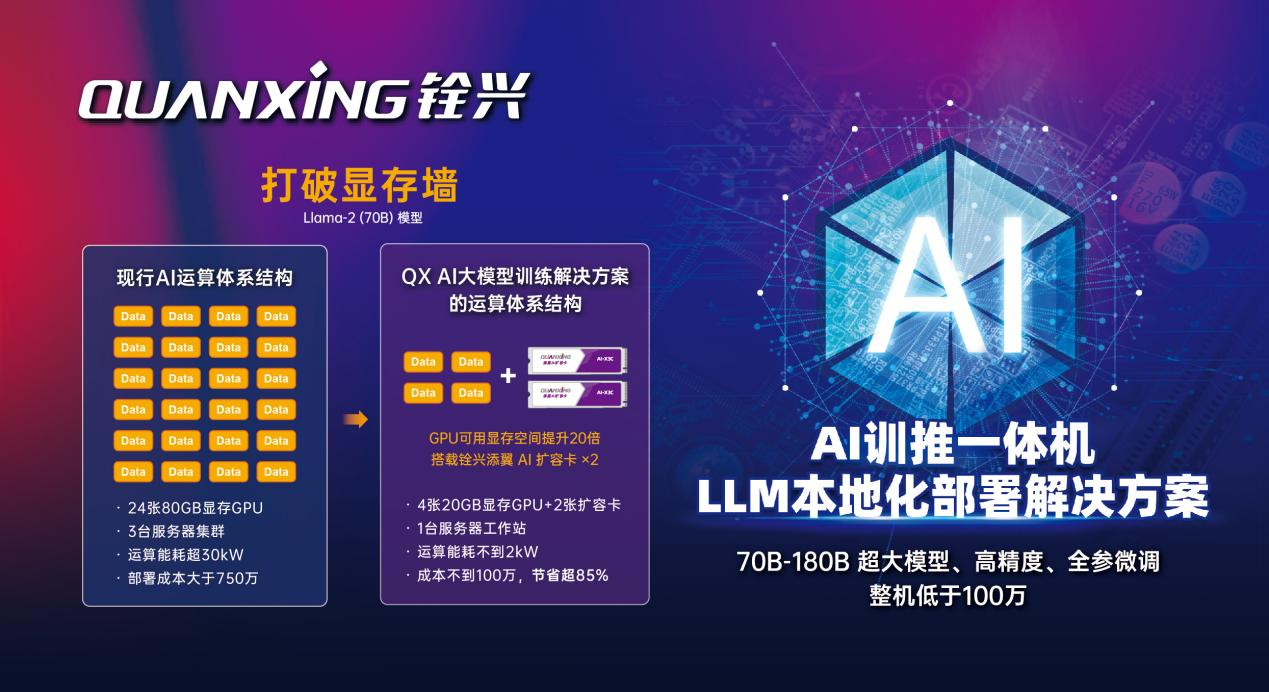
銓興科技AI全參微調、訓推一體解決方案解決什么問題
銓興科技AI超大模型全參微調、訓推一體解決方案,解決了高階顯卡購買難、硬件成本高、功耗大的痛點,解決了企業人工智能本地化部署最后一公里的難題,使本地端專屬AI應用唾手可得,助力開啟全民AI時代。
· 適配場景靈活多樣
銓興解決方案對Llama、Mistral、千問、智普等主流開源大模型實現了完美支持,可廣泛應用于政府項目、數據中心、高校科研、企業專屬服務等領域。
· 顯著降低配置成本、能耗低
以實現Llama-3.1(70B)高算力的大模型訓練為例,現行的市場方案所需GPU加速卡顯存空間約1500GB,要配置二十四張80GB顯存的GPU,使用叁臺服務器集群,其運算能耗超30KW,存在顯卡數量多、體積占地空間大、電力基礎設施要求高、功耗大、整體部署成本超750萬,價格昂貴等多樣難題。
銓興推出的運算體系機構配置兩張銓興添翼AI擴容卡,僅用四張不禁售的中階顯卡(20GB顯存GPU),壹臺服務器工作站即實現部署。銓興AI大模型訓推一體解決方案使用中階顯卡,解決高階購買難的痛點,且顯卡數量明顯減少,噪聲低于60dB,體積小巧靈活,整體部署價格低于100萬,僅為傳統方案價格的15%,功耗低至2kW,不到傳統方案的10%,大大降低大模型訓練的進入門檻成本,銓興科技出色的技術實力和超前沿的存算解決方案,展現了人工智能產業算力和存力完美結合,給人工智能產業帶來積極影響,推動銓民參與的AI低成本的時代的到來。
· 應用場景廣泛
該方案適用70B-180B超大模型全參微調、訓推一體,典型案例包括政府政務AI、科研AI、高校AI教學、法律AI、金融AI等多樣B端客戶專業服務等。

目前已經與多家國產CPU、國產GPU、軟件服務商、AI服務器整機廠商、廈門大學等高校以及政府部門建立了合作關系,共同推動AI技術的發展和應用。
銓興科技推動AI產業高質量
人工智能作為引領未來的戰略性技術,已經成為發展新質生產力的主要陣地。銓興科技精準解決中小企業AI人工智能落地部署的痛點,開發出前瞻性與實用性的半導體存儲解決方案,為各行各業提供更加智能化、個性化、接地氣的解決方案,驅動各企業的數字化與智能化,實現全域全時全場景應用持續深化,推動AI人工智能產業高質量加速發展!


評論