揭秘FPGA:為什么比 GPU 的延遲低這么多?

最近幾年,FPGA這個概念越來越多地出現。
本文引用地址:http://www.j9360.com/article/201806/382354.htm例如,比特幣挖礦,就有使用基于FPGA的礦機。還有,之前微軟表示,將在數據中心里,使用FPGA“代替”CPU,等等。
其實,對于專業人士來說,FPGA并不陌生,它一直都被廣泛使用。但是,大部分人還不是太了解它,對它有很多疑問——FPGA到底是什么?為什么要使用它?相比 CPU、GPU、ASIC(專用芯片),FPGA有什么特點?……
今天,帶著這一系列的問題,我們一起來——揭秘FPGA。
為什么使用FPGA?
眾所周知,通用處理器(CPU)的摩爾定律已入暮年,而機器學習和 Web 服務的規模卻在指數級增長。
人們使用定制硬件來加速常見的計算任務,然而日新月異的行業又要求這些定制的硬件可被重新編程來執行新類型的計算任務。
FPGA 正是一種硬件可重構的體系結構。它的英文全稱是Field Programmable Gate Array,中文名是現場可編程門陣列。
FPGA常年來被用作專用芯片(ASIC)的小批量替代品,然而近年來在微軟、百度等公司的數據中心大規模部署,以同時提供強大的計算能力和足夠的靈活性。
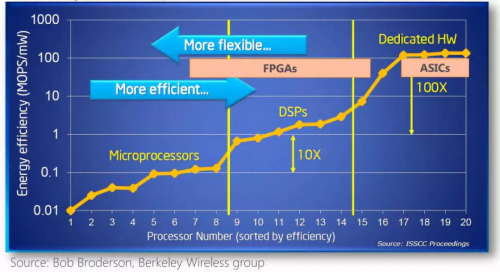
▲不同體系結構性能和靈活性的比較
FPGA 為什么快?「都是同行襯托得好」。
CPU、GPU 都屬于馮·諾依曼結構,指令譯碼執行、共享內存。FPGA 之所以比 CPU 甚至 GPU 能效高,本質上是無指令、無需共享內存的體系結構帶來的福利。
馮氏結構中,由于執行單元(如 CPU 核)可能執行任意指令,就需要有指令存儲器、譯碼器、各種指令的運算器、分支跳轉處理邏輯。由于指令流的控制邏輯復雜,不可能有太多條獨立的指令流,因此 GPU 使用 SIMD(單指令流多數據流)來讓多個執行單元以同樣的步調處理不同的數據,CPU 也支持 SIMD 指令。
而 FPGA 每個邏輯單元的功能在重編程(燒寫)時就已經確定,不需要指令。
馮氏結構中使用內存有兩種作用。一是保存狀態,二是在執行單元間通信。
由于內存是共享的,就需要做訪問仲裁;為了利用訪問局部性,每個執行單元有一個私有的緩存,這就要維持執行部件間緩存的一致性。
對于保存狀態的需求,FPGA 中的寄存器和片上內存(BRAM)是屬于各自的控制邏輯的,無需不必要的仲裁和緩存。
對于通信的需求,FPGA 每個邏輯單元與周圍邏輯單元的連接在重編程(燒寫)時就已經確定,并不需要通過共享內存來通信。
說了這么多三千英尺高度的話,FPGA 實際的表現如何呢?我們分別來看計算密集型任務和通信密集型任務。
計算密集型任務的例子包括矩陣運算、圖像處理、機器學習、壓縮、非對稱加密、Bing 搜索的排序等。這類任務一般是 CPU 把任務卸載(offload)給 FPGA 去執行。對這類任務,目前我們正在用的 Altera(似乎應該叫 Intel 了,我還是習慣叫 Altera……)Stratix V FPGA 的整數乘法運算性能與 20 核的 CPU 基本相當,浮點乘法運算性能與 8 核的 CPU 基本相當,而比 GPU 低一個數量級。我們即將用上的下一代 FPGA,Stratix 10,將配備更多的乘法器和硬件浮點運算部件,從而理論上可達到與現在的頂級 GPU 計算卡旗鼓相當的計算能力。
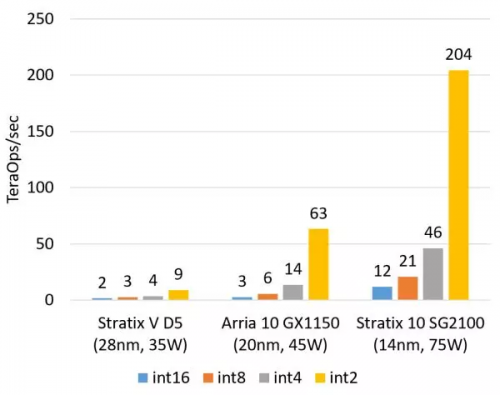
▲FPGA 的整數乘法運算能力(估計值,不使用 DSP,根據邏輯資源占用量估計)
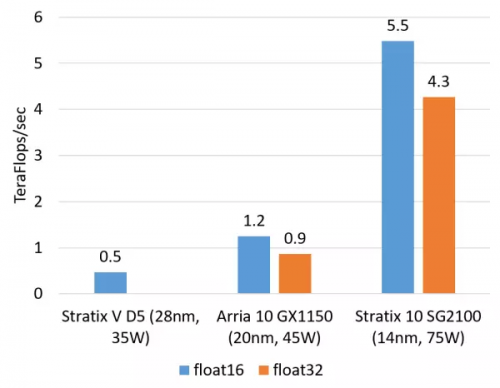
▲FPGA 的浮點乘法運算能力(估計值,float16 用軟核,float 32 用硬核)
在數據中心,FPGA 相比 GPU 的核心優勢在于延遲。
像 Bing 搜索排序這樣的任務,要盡可能快地返回搜索結果,就需要盡可能降低每一步的延遲。
如果使用 GPU 來加速,要想充分利用 GPU 的計算能力,batch size 就不能太小,延遲將高達毫秒量級。
使用 FPGA 來加速的話,只需要微秒級的 PCIe 延遲(我們現在的 FPGA 是作為一塊 PCIe 加速卡)。
未來 Intel 推出通過 QPI 連接的 Xeon + FPGA 之后,CPU 和 FPGA 之間的延遲更可以降到 100 納秒以下,跟訪問主存沒什么區別了。











評論