揭秘FPGA:為什么比 GPU 的延遲低這么多?

這本質上是體系結構的區別。
FPGA 同時擁有流水線并行和數據并行,而 GPU 幾乎只有數據并行(流水線深度受限)。
例如處理一個數據包有 10 個步驟,FPGA 可以搭建一個 10 級流水線,流水線的不同級在處理不同的數據包,每個數據包流經 10 級之后處理完成。每處理完成一個數據包,就能馬上輸出。
而 GPU 的數據并行方法是做 10 個計算單元,每個計算單元也在處理不同的數據包,然而所有的計算單元必須按照統一的步調,做相同的事情(SIMD,Single Instruction Multiple Data)。這就要求 10 個數據包必須一起輸入、一起輸出,輸入輸出的延遲增加了。
當任務是逐個而非成批到達的時候,流水線并行比數據并行可實現更低的延遲。因此對流式計算的任務,FPGA 比 GPU 天生有延遲方面的優勢。
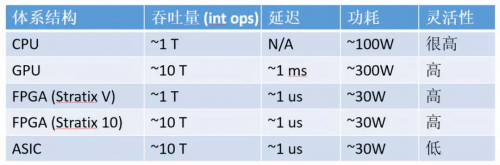
計算密集型任務,CPU、GPU、FPGA、ASIC 的數量級比較(以 16 位整數乘法為例,數字僅為數量級的估計
ASIC 專用芯片在吞吐量、延遲和功耗三方面都無可指摘,但微軟并沒有采用,出于兩個原因:
數據中心的計算任務是靈活多變的,而 ASIC 研發成本高、周期長。好不容易大規模部署了一批某種神經網絡的加速卡,結果另一種神經網絡更火了,錢就白費了。FPGA 只需要幾百毫秒就可以更新邏輯功能。FPGA 的靈活性可以保護投資,事實上,微軟現在的 FPGA 玩法與最初的設想大不相同。
數據中心是租給不同的租戶使用的,如果有的機器上有神經網絡加速卡,有的機器上有 Bing 搜索加速卡,有的機器上有網絡虛擬化加速卡,任務的調度和服務器的運維會很麻煩。使用 FPGA 可以保持數據中心的同構性。
接下來看通信密集型任務。
相比計算密集型任務,通信密集型任務對每個輸入數據的處理不甚復雜,基本上簡單算算就輸出了,這時通信往往會成為瓶頸。對稱加密、防火墻、網絡虛擬化都是通信密集型的例子。
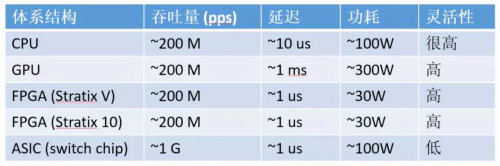
▲通信密集型任務,CPU、GPU、FPGA、ASIC 的數量級比較(以 64 字節網絡數據包處理為例,數字僅為數量級的估計)
對通信密集型任務,FPGA 相比 CPU、GPU 的優勢就更大了。
從吞吐量上講,FPGA 上的收發器可以直接接上 40 Gbps 甚至 100 Gbps 的網線,以線速處理任意大小的數據包;而 CPU 需要從網卡把數據包收上來才能處理,很多網卡是不能線速處理 64 字節的小數據包的。盡管可以通過插多塊網卡來達到高性能,但 CPU 和主板支持的 PCIe 插槽數量往往有限,而且網卡、交換機本身也價格不菲。
從延遲上講,網卡把數據包收到 CPU,CPU 再發給網卡,即使使用 DPDK 這樣高性能的數據包處理框架,延遲也有 4~5 微秒。更嚴重的問題是,通用 CPU 的延遲不夠穩定。例如當負載較高時,轉發延遲可能升到幾十微秒甚至更高(如下圖所示);現代操作系統中的時鐘中斷和任務調度也增加了延遲的不確定性。
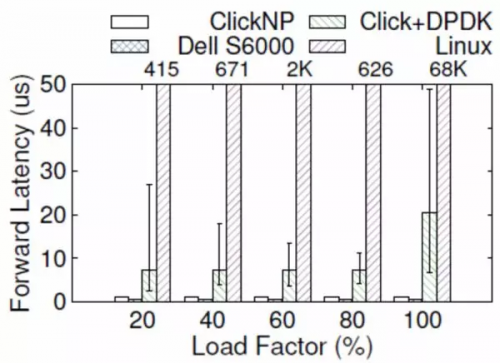
ClickNP(FPGA)與 Dell S6000 交換機(商用交換機芯片)、Click+DPDK(CPU)和 Linux(CPU)的轉發延遲比較,error bar 表示 5% 和 95%。來源:[5]
雖然 GPU 也可以高性能處理數據包,但 GPU 是沒有網口的,意味著需要首先把數據包由網卡收上來,再讓 GPU 去做處理。這樣吞吐量受到 CPU 和/或網卡的限制。GPU 本身的延遲就更不必說了。
那么為什么不把這些網絡功能做進網卡,或者使用可編程交換機呢?ASIC 的靈活性仍然是硬傷。
盡管目前有越來越強大的可編程交換機芯片,比如支持 P4 語言的 Tofino,ASIC 仍然不能做復雜的有狀態處理,比如某種自定義的加密算法。
綜上,在數據中心里 FPGA 的主要優勢是穩定又極低的延遲,適用于流式的計算密集型任務和通信密集型任務。
微軟部署FPGA的實踐
2016 年 9 月,《連線》(Wired)雜志發表了一篇《微軟把未來押注在 FPGA 上》的報道 [3],講述了 Catapult 項目的前世今生。
緊接著,Catapult 項目的老大 Doug Burger 在 Ignite 2016 大會上與微軟 CEO Satya Nadella 一起做了 FPGA 加速機器翻譯的演示。
演示的總計算能力是 103 萬 T ops,也就是 1.03 Exa-op,相當于 10 萬塊頂級 GPU 計算卡。一塊 FPGA(加上板上內存和網絡接口等)的功耗大約是 30 W,僅增加了整個服務器功耗的十分之一。
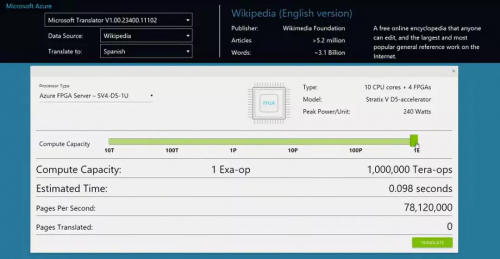
▲Ignite 2016 上的演示:每秒 1 Exa-op (10^18) 的機器翻譯運算能力











評論