基于FPGA的遺傳算法組合邏輯電路設計

遺傳算法(Genetic Algorithm)是模擬達爾文生物進化論的自然選擇和遺傳學機理的生物進化過程的計算模型,是一種通過模擬自然進化過程搜索最優解的方法,它最初是由美國Michigan大學J.Holland教授于1975年首先提出來的。隨著經濟社會的快速發展,人類科學研究與生產活動的廣度與深度都大大拓展了。科研與生產實踐中涌現出的大量新課題對作為社會發展催化劑的信息與控制科學提出了前所未有的挑戰。傳統信息處理算法在面對各種非線性、不確定、不能精確解析以及建模機理復雜的問題時,往往顯得捉襟見肘。正是在這種背景下,各種智能信息處理算法如雨后春筍般涌現出來。作為智能信息處理算法中的重要一員,遺傳算法近年來以其獨特而卓越的性能日漸引起了人們的關注。
組合邏輯電路其特點是功能上無記憶,結構上無反饋,即電路在任意時刻的輸出狀態只取決于該時刻各輸入狀態的組合,而與電路的原狀態無關。本文通過實例介紹組合邏輯電路的設計方法,并通過電子設計自動化EDA(Electronic Design Automation)進行仿真分析,使組合邏輯電路的設計變得更方便,更實用。
隨著FPGA性能的不斷提高,基于FPGA的計算加速已經逐漸成為提高計算速度和計算效率的重要手段之一。FPGA能夠實現程序的并行化處理,不僅結構簡單,而且有效地減少了運算時間、提高了運行效率,為遺傳算法能在一些實時、高速的場合得到應用提供了依據。
1 基于FPGA遺傳算法設計
遺傳算法是一種多點并行的迭代搜索算法,它的每一代稱為一個種群,由多個個體組成,每個個體稱為染色體,染色體由一定數目的字符組成。每個字符稱為一個基因,基因在染色體中的位置決定了基因所表達的特性。
文中基于FPGA的遺傳算法,整個系統分為4個單元,4個單元分別為:選擇單元、交叉單元、變異單元和適應度計算單元。
1.1 選擇單元
選擇單元執行遺傳算法中的選擇操作。選擇策略決定哪些個體存活并得以繁殖,因其直接關系到遺傳算法的運行導向問題故對遺傳算法的性能有直接并且重大的影響。標準遺傳算法所采用的輪盤賭選擇策略簡便直觀,但可能會產生較大的抽樣誤差。于是,各種改進的選擇策略產生了。
最早提出的使用濃度控制的選擇策略可以保證群體的多樣性從而避免了早熟現象并且提高了算法的魯棒性及運算效率。后來通過對浮點遺傳算法早熟收斂現象的分析,有人提出了一種新的父代選擇策略,即使用當前代的子代個體作為下代的父代個體,可使交叉算子持續地探索和開發新空間。目前,人們又發現可以通過選擇策略的改變調控并維持種群多樣性。這類研究成果中,文獻中提到的重復串的適應度處理是一個有益的嘗試。
1.2 交叉單元
交叉模塊執行遺傳算法中的交叉操作。由隨機數模塊產生的隨機數與事先確定的交叉概率相比較,如果隨機數小于交叉概率,則一對個體進行交叉操作,否則該對個體不變,直接進入變異模塊。
文中一對個體進行交叉操作的基因位由隨機數決定。隨機數模塊產生一個與個體等長的隨機二進制串,若隨機二進制串中的某一位為1,則該對個體中該位置的基因相互交叉;否則,該對個體中該位置的基因保持不變。
1.3 變異單元
變異模塊執行遺傳算法中的變異操作。與交叉模塊相似,變異模塊也是將隨機數模塊產生的隨機數與事先確定的變異概率相比較,決定是否進行變異操作。同時個體中進行變異操作的基因位也是由一個與個體等長的隨機二進制字符串決定的。對個體而言,執行變異操作的基因位不宜過多,否則容易對個體造成較大的破壞,影響種群的穩定性。本文將兩個隨機二進制字符串(每一位0、1等概率)進行相與操作,這樣得到的新的隨機二進制字符串中每一位為1的概率將降低到25%,用這個新的隨機二進制串來決定個體變異的基因位。這樣執行變異操作的個體中,每一位基因變異的概率也會降低到25%。
1.4 適應度計算單元
適應度計算模塊執行遺傳算法中的適應度計算比較操作,它根據適應度計算函數來計算種群中每一個個體的適應度,包括遺傳算法開始時初始化產生的種群和后來遺傳變異后產生的種群,并把每個個體的適應度大小保存到存儲器中。同時,適應度計算模塊還需要記錄每一代種群中適應度最高的個體。適應度計算模塊有一個內置的計數器,計數器隨適應度計算模塊的啟動而啟動,從0開始計數,每個時鐘周期加1。計數器數值表示當前個體及其適應度在存儲器模塊當中的存放地址。適應度計算模塊停止工作時,計數器會重新歸零,等待新一輪的啟動信號。
2 遺傳算法的過程設計
遺傳算法通過對當前種群施加選擇、交叉、變異等一系列遺傳操作,產生出新一代的種群,通過多次迭代,使種群逐步進化到包含或接近最優解的狀態,如圖1所示。一般來說,一個完整的遺傳算法包括編碼、初始種群的生成、用于進行個體評估的適應度函數的設計、遺傳算子(選擇、交叉和變異)以及控制參數(終止準則)的設定5個方面。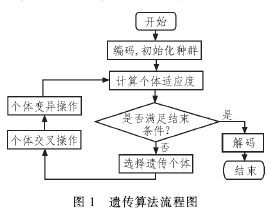
1)系統由外部給出reset信號:隨機數模塊開始產生隨機數種子;控制模塊重啟,重新啟動后,由該模塊控制系統運行。
2)控制模塊給出相應信號,初始化模塊運行,初始化種群。
3)當初始化完畢后,有控制模塊發出相應信號,系統進入進化計算階段,進行遺傳算法的具體操作。
4)各個遺傳算法功能模塊進行算子操作,經由交叉、變異、選擇操作產生新的種群,同時記錄系統的運行信息。如未完成本代進化計算,則重復本步驟。
5)完成一代計算后,由控制模塊發出相應指令,存儲相關運行參數、轉換存儲器的工作狀態。如果以完成計算,則發出完成信號,如果未完成,重復步驟4)。
2.1 遺傳算法編碼
把一個問題的可行解從其解空間轉化到遺傳算法所能處理的搜索空間的轉化方法叫做編碼。編碼方式應具有如下性質:完備性、封閉性、健全性和非冗余性。
遺傳算法的編碼方式有很多種,二進制編碼方式是最常用的編碼方式之一,最早由Holland提出。但是二進制編碼的遺傳算法進行數值優化時,存在連續到離散的映射誤差、精度不高,最優解附近搜索較慢等缺點。雖然提高個體編碼串長度可以提高精度,但是會使遺傳算法的搜索空間增加,從而使得搜索變得異常緩慢。
本文中遺傳算法主要解決的問題是組合邏輯電路的自動設計,組合邏輯電路由與門、或門、非門、同或門、異或門五種基本的門電路組成。在FPGA上進行遺傳算法的編碼,本文采用二進制字符串編碼的方法,每個個體都有64位二進制數組成,由64位二進制數解碼出一個組合邏輯電路。
2.2 隨機數產生模塊
隨機數控制模塊的作用是根據外部信號控制隨機數內部模塊,發出相應的使能、重啟信號,產生隨機數種子,從而產生隨機數。
本系統中隨機數模塊所產生的隨機序列由線性反饋移位寄存器(Linear Feedback Shift Registers,LFSR)生成。LFSR在FPGA上易于實現,且所產生的隨機序列具有周期長、隨機性好的特點。隨機數模塊需要向選擇模塊提供隨機序列,作為存儲器單元的地址,同時隨機數模塊還要向交叉模塊和變異模塊提供隨機序列,用于確定是否執行交叉和變異操作,以及執行交叉和變異操作的位置。
2.3 存儲器模塊
存儲器模塊用來存儲種群中的個體及其適應度。在本系統中,個體和適應度是分開存儲的,因而對整個種群而言,其存儲區可分為4個部分:父代個體存儲區,父代適應度存儲區,子代個體存儲區以及子代適應度存儲區。
由于本系統中的遺傳算法采用完全流水線實現,因而必然會涉及到對存儲器模塊的同時讀寫操作,比如在選擇模塊從存儲器模塊中讀取父代種群中的個體及其適應度的同時,適應度模塊則在向存儲器模塊中寫入子代種群中的新個體及其適應度。
3 實驗結果
系統在Altera公司的Cyclone系列EPIC6Q240C8型號芯片上進行了實現。系統采用Verilog語言編寫,開發平臺為Altera公司自帶的Quart usII 6.0集成環境。為驗證系統的正確性和測試系統的性能,本文,對系統進行了測試,即給出一個三輸入一輸出的組合邏輯電路的真值表,測試真值表如表1所示。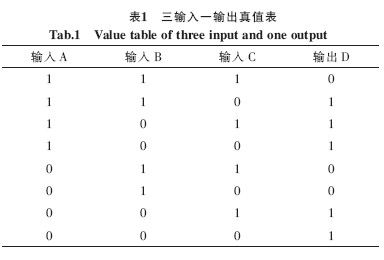
遺傳算法參數設置如下:種群規模為100,交叉概率為0.6,變異概率為0.1,基因長度為16,遺傳代數為100。其中針對給出的真值表,通過代碼輸入、編譯、綜合、布局布線后,得到結果如圖2所示。
即最優解為:C3bFC396。經過解碼,得到電路圖如圖3所示。所得到的電路圖滿足真值表的要求。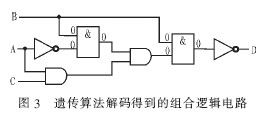
4 結束語
本文在FPGA上實現了基于遺傳算法的組合邏輯電路的自動設計。對整個系統結構進行了自頂而下的設計,對模塊功能進了劃分。硬件實現遺傳算法能有效地縮短運行時間,為實時應用提供了可能。隨著FPGA芯片技術的進一步發展,大規模并行遺傳算法的實現也將成為可能。











評論