一種融合社會化標簽的協同過濾推薦算法

推薦系統是為解決信息過載和發掘長尾物品而提出的一種有效的工具,它與搜索引擎相互配合,共同為用戶提 供可靠便捷的服務。推薦系統可以應用在很多場合,比如電 影、音樂、圖書、文章、新聞、網頁和廣告等領域。代表性 網站有亞馬遜、Netflix、豆瓣、LastFM、YouTube、Facebook 以及淘寶等。推薦系統可以提供個性化的推薦,滿足用戶隨 時變化和差異化的需求
社會化標簽作為Web2.0發展的產物,是一種非常有效 的網絡資源組織工具。社會化標簽有兩方面的含義:第一, 表示用戶的興趣;第二,表示物品的語義。通過標簽用戶和 物品可以聯系起來。利用社會化標簽可以組織網站內容,推 薦物品以及標簽。社會化標簽除了這些功用外,還可以與現 有的推薦系統配合,產生更加有效的推薦,這是本文所要研 究的內容,利用社會化標簽信息,在經典的基于評分的推薦 系統上產生更好的推薦效果。將社會化標簽和評分相融合的算法也是推薦系統領域 研究的一個熱門方向。Tso-Sutter提出了
一種可以將標簽融合 于標準的協同過濾算法,他直接將標簽當作二值化數據,作 為用戶的特征向量或物品的特征向量。Bogers和Van Den Bosh 通過計算標簽的重合度,來表示用戶或物品之間的相似度。Gemmel提出了加權的混合推薦算法,他將基于圖的標簽推
薦算法和基于用戶和物品的協同過濾算法相結合,通過加權計算二者的流行度產生推薦。
Gedikli和Jannach利用標簽來表示用戶喜歡或不喜歡的物品具有的特征,通過對標簽的評分可以得到用戶最終對物品的評分。Yi zhen在評分矩陣上使用了PMF產生推薦,將 標 簽 信 息 加 入 到PMF的正則化項 中,在模型生成的 過 程 中 融 入 了 標
圖1 標簽擴展評分矩陣
簽的信息。此外,還有更加復雜的方法。Yueshen Xu和JianweiYin提出了一種可以把UGC(User Generated Content)信息和 評分結合的方法,UGC包括標簽和評論,所使用的方法是 CTR(Collaborative Topic Regression),該方法于2011年被Wang 和Blei提出,是結合PMF和LDA的一種混合模型,CTR不僅可 以被用來做評分預測,還可以獲取物品描述中的隱變量。
本文結合現有的基于內存的推薦算法,提出了一種整 合隱語義向量的標簽融合算法,下面將重點介紹該算法以及 相關的一些內容,最后對算法的有效性進行驗證。
1 相關推薦算法
1.1 基于內存的算法
1.1.1 基于用戶的協同過濾算法
基于用戶的協同過濾算法的思想是:具有相同愛好的 用戶會選擇相同的物品。該算法包括兩個步驟:a.找到和目 標用戶興趣相似的用戶集合;b.找出這個集合中用戶喜歡但 是目標用戶沒有購買的物品。每一個用戶可以看作是n維向量,每一個物品的評分作 為向量的元素,這樣用戶的相似度就可以轉換為計算向量的 相似度。下面是三種常見的相似度計算的方法。
其中(1)是歐式距離,(2)是余弦夾角,(3)是Pearson相關系數。ru,i 為用戶u對物品i的評分, 和 分別是用戶u和用 戶v在各自所評物品集上的均值。在計算獲得目標用戶的相似用戶集后,便可根據相似用戶預測待推薦物品的評分。評分的計算公式為式(4)。
其中 S (u , K ) 表示目標用戶u的K個相似用戶, 表示對物品 i評過分的用戶集合,最終的相似用戶是這兩個集合的交集。 ru 和 rn 分別表示用戶u和用戶n在各自評分集上的均值。該公式 的含義是對所有相似用戶對物品i的評分作加權平均。
1.1.2 基于物品的協同過濾算法
基于物品的協同過濾算法分為兩個步驟:a. 根據用戶已 評分過的物品分別找出每個物品的K個相似度最高的物品。 b.找出用戶未做評價的物品預測其分數。計算目標物品的相似物品是將每個物品看作是一個m維 向量,每個用戶的評分是向量中的項。計算相似度公式和基于用戶的推薦算法類似,這里要補充的是一種修正的余弦相似度(Adjust Cosine Similarity),如公式(5)所示。該公式被Sarwar在MovieLens上證明是最佳的相似度計算方法,然而在其他的數據集中,該公式不一定是最優的。
利用公式(6)可以預測待推薦物品的評分,該公式的含 義是對相似物品的評分作加權平均。其中, S (u , K ) 表示和物 品i相似的K個物品的集合, N (u ) 表示用戶u評過分的物品。 ri 表示物品i的平均分。
1.2 隱因子模型
隱因子模型(LFM)的核心思想是通過隱含的特征將用戶 和物品聯系起來。對于分析用戶行為背后的含義以及物品的 分類有很好的效果。

LFM的思想很簡單,將評分矩陣R分解為兩個低維的矩 陣P和Q,如式(7)所示,針對每一個評分,引入隱變量l。然 后通過最小化均方誤差學習P、Q矩陣,如式(8)所示,為了下降算法優化參數。
2 融合標簽的協同推薦算法
2.1 標簽擴展評分矩陣
傳統的評分矩陣是<用戶,物品,評分>這是一個二維 的關系,而標簽矩陣<用戶,物品,標簽>是一個三維的關 系,因為用戶可以給一個物品打多個標簽,而評分只有一 個。要使用基于評分的方法,必須將三維的標簽矩陣轉化為 二維矩陣。圖1為轉化的關系圖,可以將其轉化為兩個二維 矩陣。其中水平方向將用戶打過的標簽作為用戶向量的一部 分,垂直方向將標記過物品的標簽作為物品向量的一部分。 對于UserTag和ItemTag向量中的值,使用TF-IDF(Term Frequency-Inverse Document Frequency)表示,如公式(9),這里將UserTag和ItemTag看作是文檔。
其中TFij 為詞頻,描述的是第i個標簽在文檔j中所占的比例, IDFi 為逆文檔頻率, ni 為第i個關鍵詞在N篇文檔中出 現的次數,所以 ni 越大 IDFi 越小。二者的乘積 wij 定義為第i個標簽在文檔j中的權值。一個標簽在一篇文檔中出現的頻率越高對權值的貢獻越大,在所有文檔中出現的頻率越高對 權值的貢獻越小。這樣有了權值的定義,就可以把一個文檔表示為向量 d j = (w1 j , w 2 j ,..., w kj ) 。
2.2 提取隱語義
接下來提取標簽的隱語義,所使用的模型是LMF,需 要式(10)來提取用戶和物品中的隱語義。

最終得到 Pu = ( pu1 , ..., puK ) 和 Pi = ( pi1 , ..., piK ) 向量,它們分別表示了用戶的偏好隱語義和物品的特征隱語義。
2.3 評分和隱語義整合
將標簽信息的格式轉換為評分的格式,然后可以利用 評分的協同推薦算法,將用戶或物品的評分向量和標簽向,物品向量表示為 i = (r i ,..., r i , pi ,..., pi ) ,p是隱變量,它的個數為K。整合 后,可以使用新的用戶向量計算用戶的相似度,或使用新物
品向量計算物品的相似度。這里將這兩個方法稱為usertagCF和itemtagCF。
2.4 模型學習和推薦
所提的算法利用了協同過濾中基于內存和基于模型的 算法, L MF需要訓練, 具體的訓練過程在1.2節中已有介 紹,這里需要說明的是影響推薦的兩個參數,一個是用戶或 物品的鄰居個數K,另一個是用戶或物品的隱變量個數F。
3 實驗設計與實驗結果
3.1 評測指標
本文選擇均方根誤差(RMSE)和平均絕對誤差(MAE)作 為評價的主要標準。
RMSE和MAE是評分預測問題的兩個常用指標。其中T為測試集, rui 是實際的評分, r?ui 是預測的評分。
3.2 實驗設計
(1)實驗數據
實驗采用的數據集是MovieLens 最新的100k數據集,
該數據集包含706名用戶對8570部電影的100023 個評分以及
2488 個標簽,時間范圍為1996年4月2日到2015年3月30日。 (2)算法實現 根據標簽數據集統計UserTag和ItemTag中的TF-IDF值,
利用該標簽數據訓練LFM模型,參數設置為學習率0.15,步 長0.04,通過多次迭代后獲取用戶或物品的特征向量p,將p 與用戶或物品的評分向量融合,本算法使用的相似度公式為 Pearson相似度。
算法的實現過程中涉及到兩個重要的參數,一個是用 戶或物品的鄰居數目K,另一個是LFM模型中的隱變量個數 F。這兩個變量的取值不同,對最終的RMSE和MAE會造成 不同的影響。
3.3 實驗結果 (1)userCF和usertagCF的結果比較 基于用戶的協同過濾和將標簽和評分融合后的協同過
濾比較結果如表1所示,可以發現,隨著K的變化RMSE和
MAE都在減小, user tag CF在K=40時性能就已經開始改善 了,隨著K值的增大,可以看到提升逐步增加。表2為不同F 值下usertagCF的結果對比,可以發現F=5左右時,RMSE和 MAE的值都是最小的,說明隱變量不是越多越好。
(2) itemCF和itemtagCF的比較 表3為基于物品的協同過濾算法在融合標簽前后的結果
比較,可以發現,隨著K的增大,RMSE和MAE都在減小,也 是在K=40的時候性能開始改善。表4為不同F值對itemtagCF的 影響。隨F值的增大,性能在逐步改善。與usertagCF不同,F 值在較大的情況下仍能提升性能,這是因為測試的數據集中 物品的數目約為用戶數目的12倍,如果要對物品向量產生影 響,物品的隱語義數目應高于用戶隱語義數目。
4 結束語
本文提出了一種將社會化標簽和評分相融合的方法,該算法相較于基于模型的方法,具有實現簡單、運行較快的優點。通過實驗證明,該算法可以有效地較少預測誤差。





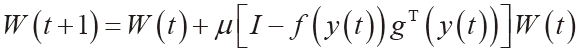
評論