解析ARM926EJ-S在MPEG-4軟解碼器的優化與實現

1 引 言
本文引用地址:http://www.j9360.com/article/149884.htmMPEG-4視頻壓縮標準自問世以來受到人們的廣泛關注。近幾年,嵌入式應用中對MPEG-4播放器的實現已經成為眾多廠家的研究熱點。視頻壓縮的重要性以及其標準的發展歷程。隨著數字化、網絡化全球一體化信息時代的來臨,包括聲音、圖形、數據以及圖像、影像在內的多媒體信息的維送和處理;其關鍵在于后編技術。由于MPEG-4系統龐大且需要大量的數據處理,因此在ARM中實現MPEG-4軟解碼需要對其原算法進行充分的優化才能達到理想的性能。為此研究了一種基于ARM926EJ-S微處理器的MPEG-4解碼算法的純軟件實現和優化的方法,通過對解碼算法的軟件優化,將QVGA格式MPEG-4碼流在ARM9平臺上的播放速度由原來的10 f/s提高到了37 f/s,完全達到了流暢播放的要求,具有很高的實用價值。目前,視頻技術的應用范圍很廣,如網上可視會議、網上可視電子商務、網上政務、網上購物、網上學校、遠程醫療、網上研討會、網上展示廳、個人網上聊天、可視咨詢等業務。
2開發平臺及耗時分析
論文研究使用的是基于ARM926EJ-S微處理器的綜合開發平臺,采用Linux操作系統,Linux是一類Unix計算機操作系統的統稱。Linux操作系統的內核的名字也是Linux.Linux操作系統也是自由軟件和開放源代碼發展中最著名的例子。嚴格來講,Linux這個詞本身只表示Linux內核,但在實際上人們已經習慣了用Linux來形容整個基于Linux內核,并且使用GNU 工程各種工具和數據庫的操作系統。Linux得名于計算機業余愛好者Linus Torvalds.外接320*240(QVGA格式)的LCD顯示屏。ARM926EJ-S微處理器的時鐘頻率為190 MHz;采用5級整數流水線操作,支持32位ARM指令集和16位Thumb指令集以及擴充的DSP指令集;支持數據Cache和指令Cache,具有更高的指令和數據處理能力。
MPEG-4 SP級算法流程圖如圖1所示。優化的前期工作首先要將MPEG-4解碼代碼移植到開發平臺上,然后對解碼各個模塊進行運算量和耗時分析,找出優化的重點內容。本文采用長度為376 934 B的AVI碼流為測試序列,該碼流共95幀,其中包括8個I幀,87個P幀。在未優化前測得的耗時分析結果如表1所示,整個測試序列解碼播放完畢耗時10.05 s,解碼播放速度只有9.5 f/s.
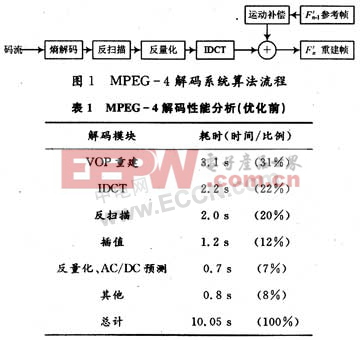
ARM(Advanced RISC Machines)是微處理器行業的一家知名企業,設計了大量高性能、廉價、耗能低的RISC處理器、相關技術及軟件。技術具有性能高、成本低和能耗省的特點。適用于多種領域,比如嵌入控制、消費/教育類多媒體、DSP和移動式應用等。在ARM上用軟件實現MPEG-4解碼器的主要任務是提高解碼速度,同時達到理想的畫面播放效果。
3 MPEG-4解碼算法在ARM926EJ-S上的優化
MPEG-4軟解碼以開源的XVID源代碼做為參考,將XVID的C源代碼移植到ARM平臺上,在此基礎上進行優化并測試優化后的解碼播放性能。優化主要從3個方面進行:
(1)對XVID源代碼的軟件結構,程序流程進行適合ARM特點的調整。
(2)對運算量較大、耗時較多的模塊編寫匯編函數代替C程序模塊,提高程序執行效率。
(3)尋找快速或并行算法。
3.1軟件結構的優化
ARM的資源非常有限,在軟件的結構安排上應盡量減少存儲器訪問,增加Cache的命中率,提高程序執行效率。
3.1.1 適當的模塊合并處理以減少存儲器的訪問次數
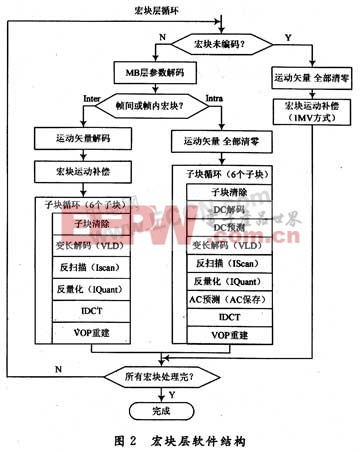
優化前的源代碼中,I幀與P幀的宏塊解碼軟件結構如圖2所示。在這個流程中,對于inter宏塊,可變長解碼(VLD),反掃描(Iscan),反量化(Iquant)三個過程中有3次的Block存儲區讀,2次Block存儲區寫和1次Data存儲區寫。源代碼是指未編譯的按照一定的程序設計語言規范書寫的文本文件。 源代碼(也稱源程序),是指一系列人類可讀的計算機語言指令。 在現代程序語言中,源代碼可以是以書籍或者磁帶的形式出現,但最為常用的格式是文本文件,這種典型格式的目的是為了編譯出計算機程序。計算機源代碼的最終目的是將人類可讀的文本翻譯成為計算機可以執行的二進制指令,這種過程叫做編譯,通過編譯器完成。

合并后VLD從Block緩沖區讀數據處理后馬上進行反掃描和反量化,并將反量化后的數據存入Block中。整個過程只進行了一次Block緩沖區的讀和寫,不僅減少了兩個讀寫操作,還減少了一個Data緩沖區的開辟。同時,對于P幀在VLD之后立即進行反量化還省去了大量零值的處理,這也是考慮合并的主要因素之一。
同樣,I幀中的AC/DC預測和反量化也可以進行合并。做法是:將add_acdc(pMB,i,block[i*64],iDcScaler,predictors);dequant_intra(data[i*64],block[i*64],iQuant,iDcScaler)兩個函數合并為:add_acde(pMB,i,block[i*64],iDcSealer,predictors,cbpcONtrol,iQuant)。這個過程在減少存儲器的讀寫操作的同時也減少了沒有預測的AC值的反量化過程。
通過以上兩個步驟的合并處理,由測試序列測試之后發現解碼播放完畢耗時5.23 s,速度提高了將近9 f/s,效果非常明顯。
![]()
或

W的結果等同于四個象素單獨處理的結果。但是由于ARM處理器字讀取時是字地址對齊的,因此要注意改進算法引起的字地址不對齊問題,利用這個算法時可以通過拼字的方法來解決字地址對齊的問題。
通過這一步驟的優化,測試序列解碼播放完畢耗時2.56 s,解碼速度提高了6 f/s,整體解碼速度達到了37 f/s.
4結語
本文對MPEG-4軟解碼器在ARM平臺上的實現及優化的整體思路和步驟進行了闡述,優化結果理想,軟解碼播放速度由最初移植完畢時的10 f/s提高到了37 f/s.本文給出的優化方案可以進一步推廣到H.264或者其他視頻軟解碼系統基于ARM的應用中。全球的視訊業務需求猛增。現有的視訊業務應用主要以政府部門會議為主,在遠程教育、遠程醫療以及商用方面的應用很少,而國外90%的企業都在使用視訊業務,已是信息高速公路的主體通信業務,因此市場潛力巨大。在視訊業務中使用的視頻壓縮標準作為關鍵技術,其發展和應用也將是巨大的。

linux相關文章:linux教程
存儲器相關文章:存儲器原理






評論