大模型時代的芯片機遇

大模型時代,AI芯片迎來了真正商業化的機會。作者 | 季宇本文來自行云集成電路創始人季宇,更被大家熟知的江湖綽號——mackler,本文是mackler最新演講,非常精彩。以下是演講全文:關于大模型,我們聽到的最多的就是Scaling。OpenAI通過多年對Scaling的堅持和激進投入,把模型一步步有效推進到千億萬億規模,實際上證明了AGI這個非常非常難的問題可以通過Scaling這種路徑清晰也簡單地多的方式去不斷逼近。同時OpenAI也把Scale作為他們組織的核心價值觀之一來不斷逼近AGI。今天不光模型尺寸在Scale,上下文長度也在劇烈地Scale。這種方法論雖然相比AGI這么宏大的目標而言已經足夠簡化了,但這背后是同等急劇上升的資源投入,單純的Scale并不是一個經濟性的方案。所以我們看到Sam Altman提到7萬億美元的瘋狂計劃,大家也經常討論大模型商業落地的巨大成本。大模型的商業落地相比互聯網目前有一個非常巨大的區別,就是邊際成本仍然非常高。過去的互聯網業務,增加一個用戶對互聯網廠商的基礎設施而言,增加的成本幾乎是可以忽略不記的。但今天大模型每增加一個用戶,對基礎設施增加的成本是肉眼可見的增加的,目前一個月幾十美元的訂閱費用都不足以抵消背后高昂的成本。而且今天的大模型要大規模商業化,在模型質量、上下文長度等方面還有進一步訴求,實際上還有可能需要進一步增加這個邊際成本。今天一個日活千萬的通用大模型需要一年超過100億的收入才能支撐其背后的數據中心成本,未來如果我們希望大模型產業真正像今天的互聯網產業一樣服務上億人,模型的質量可能也需要進一步上一個臺階,成本會成為很嚴重的問題。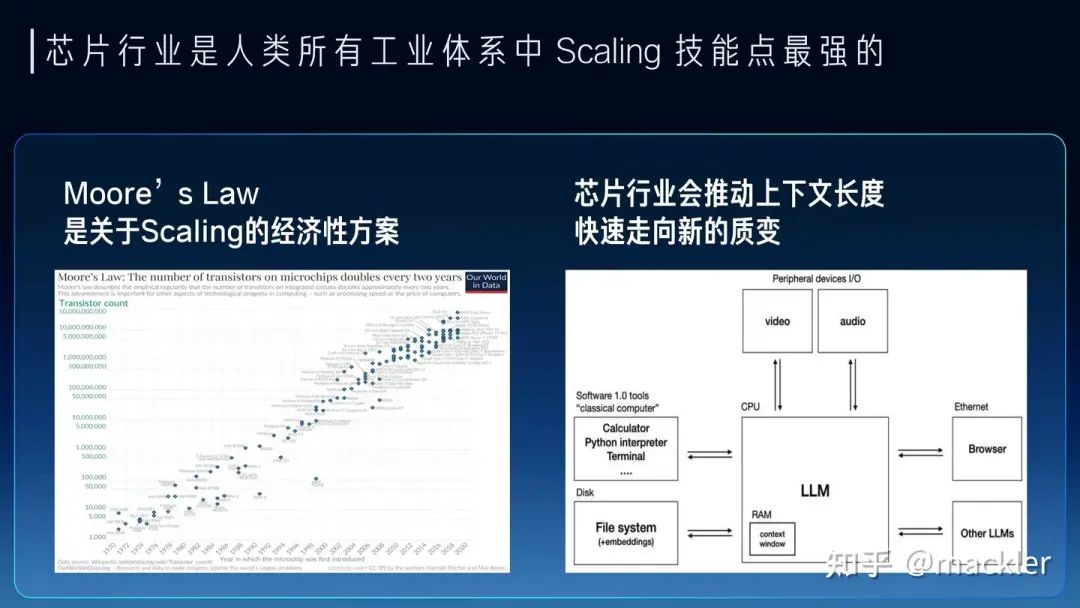 但對于芯片行業而言,只要適當拉長時間尺度,這些都不會是問題。芯片行業是人類所有工業體系中Scaling技能點最強的。過去大半個世紀,半導體行業一直踐行的摩爾定律就是一個關于Scaling的經濟性方案。其實NVIDIA的老黃評論Sam的7萬億美元計劃時也提到,芯片本身也會持續演進來不斷降低大模型Scaling所需的資源。7萬億會在幾年內逐漸變成7千億、7百億,逐漸變成一個不是那么夸張的數字。今天很多人講大模型的上下文窗口就是新的內存,今天看起來非常寶貴的幾K到幾M的大模型上下文窗口長度,我們精打細算把重要的信息,各種prompt填入到這有限的上下文窗口里,有點像上個世紀的各種經典小游戲,用很多不可思議的方式在KB級別的內存實現今天看起來已經非常復雜的游戲。但在不遠的未來,芯片行業就可以把上下文窗口逐漸變得和今天的內存一樣非常便宜,隨便一個hello world就直接吃掉MB級別的內存,隨便一個應用就GB級別的內存占用。未來我們也一樣可以隨隨便便把一個領域的全部知識裝進上下文里,讓大模型成為絕對意義上的領域專家,也可以讓大模型擁有遠超人類一輩子能接受的全部上下文,從而引發大模型走向新的質變。
但對于芯片行業而言,只要適當拉長時間尺度,這些都不會是問題。芯片行業是人類所有工業體系中Scaling技能點最強的。過去大半個世紀,半導體行業一直踐行的摩爾定律就是一個關于Scaling的經濟性方案。其實NVIDIA的老黃評論Sam的7萬億美元計劃時也提到,芯片本身也會持續演進來不斷降低大模型Scaling所需的資源。7萬億會在幾年內逐漸變成7千億、7百億,逐漸變成一個不是那么夸張的數字。今天很多人講大模型的上下文窗口就是新的內存,今天看起來非常寶貴的幾K到幾M的大模型上下文窗口長度,我們精打細算把重要的信息,各種prompt填入到這有限的上下文窗口里,有點像上個世紀的各種經典小游戲,用很多不可思議的方式在KB級別的內存實現今天看起來已經非常復雜的游戲。但在不遠的未來,芯片行業就可以把上下文窗口逐漸變得和今天的內存一樣非常便宜,隨便一個hello world就直接吃掉MB級別的內存,隨便一個應用就GB級別的內存占用。未來我們也一樣可以隨隨便便把一個領域的全部知識裝進上下文里,讓大模型成為絕對意義上的領域專家,也可以讓大模型擁有遠超人類一輩子能接受的全部上下文,從而引發大模型走向新的質變。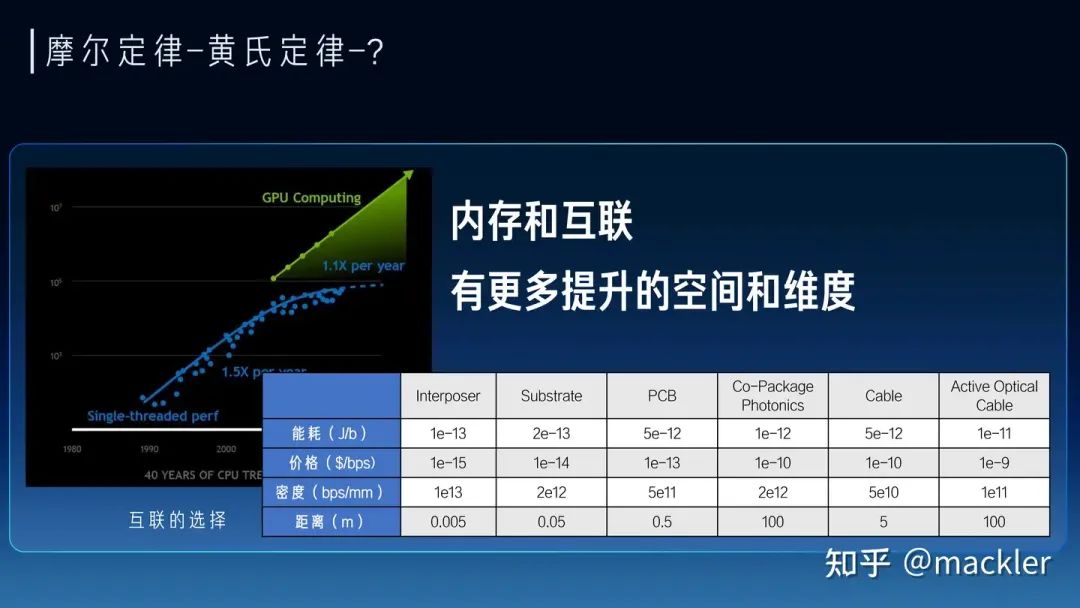 最近幾年其實說摩爾定律放緩的觀點很多,這也是實際情況,先進工藝的研發投入資金也在指數級飆升,使得維持摩爾定律逐漸變得失去經濟性。但芯片行業的Scaling不只是晶體管的微縮推動的,NVidia的GPU過去十年靠架構繼續推動放緩的摩爾定律持續保持非常高的增速,算力成本降低了一千倍。而今天大模型進一步打開了更多芯片的演進空間,今天大模型對芯片的需求從算力轉向了內存和互聯,內存系統和互聯的Scale空間更大,除了半導體工藝的演進外,封裝工藝的發展、硅光都對內存和互聯的設計打開了巨大的空間。大模型今天也早已經全面走向分布式,今天不僅僅是單顆芯片的設計,也進一步擴展到服務器、機柜、網絡層面,這些層面都有比原來有大得多的設計空間,未來芯片的增速不僅不會放緩,反而會比今天更快。
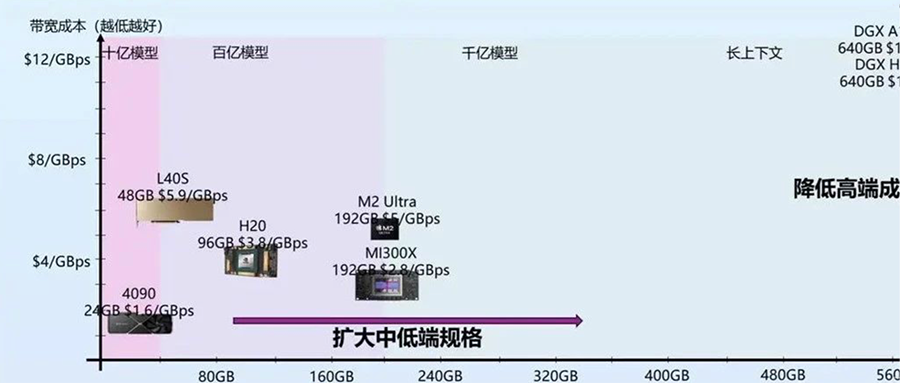
最近幾年其實說摩爾定律放緩的觀點很多,這也是實際情況,先進工藝的研發投入資金也在指數級飆升,使得維持摩爾定律逐漸變得失去經濟性。但芯片行業的Scaling不只是晶體管的微縮推動的,NVidia的GPU過去十年靠架構繼續推動放緩的摩爾定律持續保持非常高的增速,算力成本降低了一千倍。而今天大模型進一步打開了更多芯片的演進空間,今天大模型對芯片的需求從算力轉向了內存和互聯,內存系統和互聯的Scale空間更大,除了半導體工藝的演進外,封裝工藝的發展、硅光都對內存和互聯的設計打開了巨大的空間。大模型今天也早已經全面走向分布式,今天不僅僅是單顆芯片的設計,也進一步擴展到服務器、機柜、網絡層面,這些層面都有比原來有大得多的設計空間,未來芯片的增速不僅不會放緩,反而會比今天更快。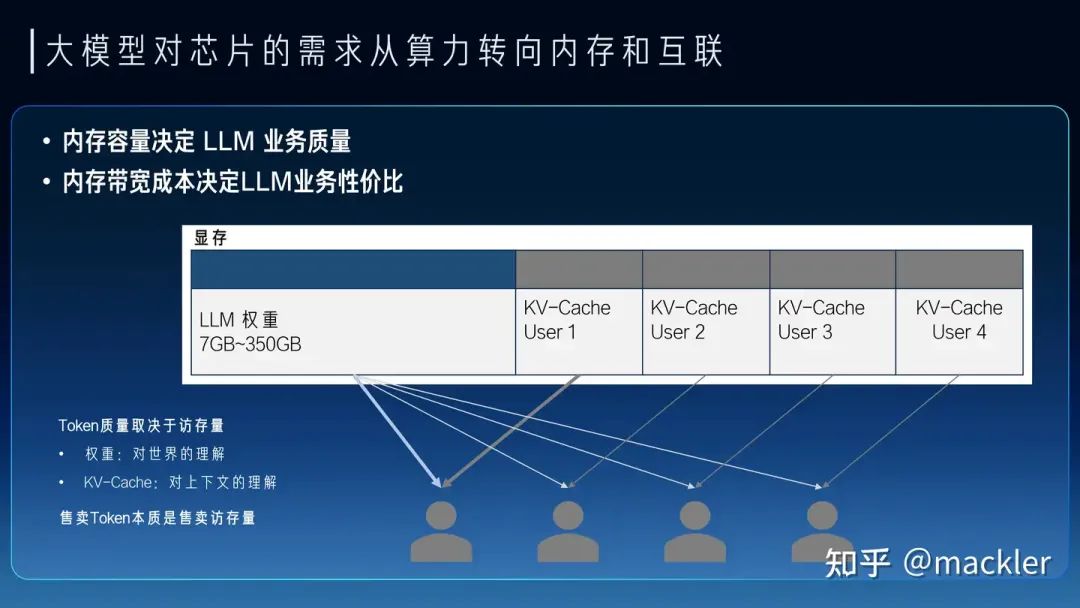 從大模型未來大規模商業化來看,大模型對芯片的主要需求實際上已經轉向內存和互聯,因為我們需要足夠多的高帶寬內存通過互聯系統連接起來形成一個巨大的高帶寬內存來支撐大模型的服務。今天我們經常討論的售賣Token的價格,實際上Token和Token是不一樣的,一個7B模型的Token和千億萬億模型的Token肯定不等價,一個4K上下文的Token和一個2M上下文的Token也不等價。Token的質量實際上和模型規模以及上下文窗口都是強相關的。模型權重是模型在訓練時候對整個數據集的壓縮和泛化,是對世界和常識的理解,而上下文對應的KV-Cache是對上下文的理解。而權重和KV-Cache其實也是大模型對內存最主要的需求,這部分的訪存速度也決定了Token生成的速度。我們可以把Token的業務質量和這個Token對應的權重以及KV-Cache的總訪存量直接掛鉤。高質量的Token生成過程中需要更大的訪存量,低質量的Token生成過程中需要的訪存量也相應更小。而售賣Token對硬件系統而言實際上是售賣內存系統的訪存帶寬。一個容量足夠大的內存系統才能提供足夠高質量的Token服務,一個內存帶寬性價比足夠高的系統才能帶來更好的服務成本。物理世界中的內存介質選擇往往要帶寬就沒有容量、要容量就沒有帶寬。當然這也沒辦法,如果存在一種內存介質容量和帶寬都比另一種都要低,也就被淘汰了,容量和帶寬總得占一個才會被篩選出來。所以今天繼要容量大又要帶寬性價比高,往往需要通過足夠有性價比的互聯系統將大量高帶寬內存連到一起,這里面是存在非常大的設計空間的。這也是中國AI芯片行業真正實現商業化的一次巨大機會,過去十年大家都是在卷算力,算力的競爭往往不只是峰值算力指標的競爭,算力和編程模型、軟件都有很強的耦合性,算力指標對先進工藝也有很強的依賴性。這兩點實際上造成了過去十年大量AI芯片在產品定義和供應鏈安全方面都遭遇了巨大的困難。大模型今天把芯片產品的競爭力拉到了內存和互聯維度,這些維度相比算力都標準化得多,對解決產品定義問題提供了新的可能性,標準化的維度更貼近指標競爭,就像今天大家買網卡或者交換機時候只關注指標而不關注是哪家的產品,這就是標準化競爭的好處。今天AI芯片可能介于網卡交換機這種純標準化的競爭和過去那種純算力這種非標競爭之間,相比過去是存在更多空間來解決產品定義的問題。內存和互聯對先進工藝的依賴度相比算力也更少,而且擴大到機柜甚至集群層面,有更多競爭的可能性,今天在封裝、互聯層面有更多發揮空間,也降低了對先進制程的依賴,在供應鏈上也存在更多的選擇。
從大模型未來大規模商業化來看,大模型對芯片的主要需求實際上已經轉向內存和互聯,因為我們需要足夠多的高帶寬內存通過互聯系統連接起來形成一個巨大的高帶寬內存來支撐大模型的服務。今天我們經常討論的售賣Token的價格,實際上Token和Token是不一樣的,一個7B模型的Token和千億萬億模型的Token肯定不等價,一個4K上下文的Token和一個2M上下文的Token也不等價。Token的質量實際上和模型規模以及上下文窗口都是強相關的。模型權重是模型在訓練時候對整個數據集的壓縮和泛化,是對世界和常識的理解,而上下文對應的KV-Cache是對上下文的理解。而權重和KV-Cache其實也是大模型對內存最主要的需求,這部分的訪存速度也決定了Token生成的速度。我們可以把Token的業務質量和這個Token對應的權重以及KV-Cache的總訪存量直接掛鉤。高質量的Token生成過程中需要更大的訪存量,低質量的Token生成過程中需要的訪存量也相應更小。而售賣Token對硬件系統而言實際上是售賣內存系統的訪存帶寬。一個容量足夠大的內存系統才能提供足夠高質量的Token服務,一個內存帶寬性價比足夠高的系統才能帶來更好的服務成本。物理世界中的內存介質選擇往往要帶寬就沒有容量、要容量就沒有帶寬。當然這也沒辦法,如果存在一種內存介質容量和帶寬都比另一種都要低,也就被淘汰了,容量和帶寬總得占一個才會被篩選出來。所以今天繼要容量大又要帶寬性價比高,往往需要通過足夠有性價比的互聯系統將大量高帶寬內存連到一起,這里面是存在非常大的設計空間的。這也是中國AI芯片行業真正實現商業化的一次巨大機會,過去十年大家都是在卷算力,算力的競爭往往不只是峰值算力指標的競爭,算力和編程模型、軟件都有很強的耦合性,算力指標對先進工藝也有很強的依賴性。這兩點實際上造成了過去十年大量AI芯片在產品定義和供應鏈安全方面都遭遇了巨大的困難。大模型今天把芯片產品的競爭力拉到了內存和互聯維度,這些維度相比算力都標準化得多,對解決產品定義問題提供了新的可能性,標準化的維度更貼近指標競爭,就像今天大家買網卡或者交換機時候只關注指標而不關注是哪家的產品,這就是標準化競爭的好處。今天AI芯片可能介于網卡交換機這種純標準化的競爭和過去那種純算力這種非標競爭之間,相比過去是存在更多空間來解決產品定義的問題。內存和互聯對先進工藝的依賴度相比算力也更少,而且擴大到機柜甚至集群層面,有更多競爭的可能性,今天在封裝、互聯層面有更多發揮空間,也降低了對先進制程的依賴,在供應鏈上也存在更多的選擇。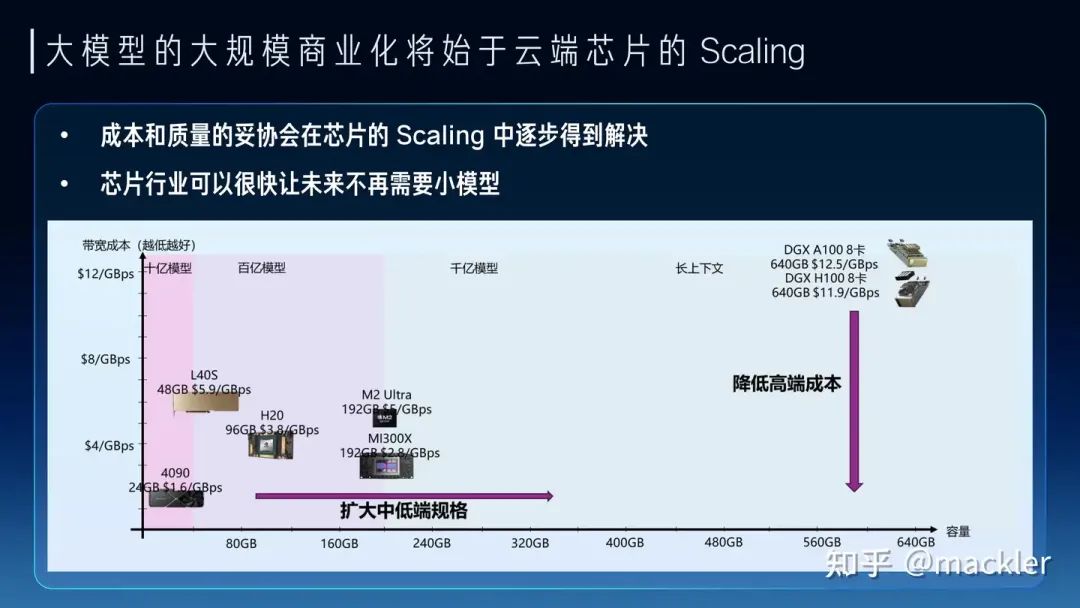 我們如果看當下和未來兩三年,其實大模型的商業探索也是在成本和Token質量上相互妥協,也逐漸分化成了兩派。一派是質量優先,用高端系統打造高質量的通用大模型,尋找超級應用來覆蓋高昂的成本。另一派是成本優先,用足夠便宜的硬件上,提供基本夠用的Token質量,尋找垂直場景的落地。從芯片未來兩三年的短期Scaling來看,也會從兩個路徑來解決這兩派在成本和質量上的糾結。一種是高端系統的成本的大幅度下降,顯著降低超級應用需要承擔的成本,另一種是低端設備的規格大幅提升,顯著提升低成本設備下可以支持的Token質量。今天很多人講7B模型已經夠用了,或者努力讓7B或者更小的模型變得夠用,其實也是一種無奈,如果能在同樣的成本下買到規格大得多的芯片,跑一個百億千億模型,支持超長上下文,商業化的空間會比今天大得多,就像曾經的顯卡和游戲行業一樣,當足夠便宜的顯卡已經可以流程跑4k畫質的時候,誰還會覺得1080p的畫質也夠用了呢?兩三年后,隨著芯片行業的發展,不會再有人需要小模型,大模型長文本的高質量Token會變得足夠便宜。
我們如果看當下和未來兩三年,其實大模型的商業探索也是在成本和Token質量上相互妥協,也逐漸分化成了兩派。一派是質量優先,用高端系統打造高質量的通用大模型,尋找超級應用來覆蓋高昂的成本。另一派是成本優先,用足夠便宜的硬件上,提供基本夠用的Token質量,尋找垂直場景的落地。從芯片未來兩三年的短期Scaling來看,也會從兩個路徑來解決這兩派在成本和質量上的糾結。一種是高端系統的成本的大幅度下降,顯著降低超級應用需要承擔的成本,另一種是低端設備的規格大幅提升,顯著提升低成本設備下可以支持的Token質量。今天很多人講7B模型已經夠用了,或者努力讓7B或者更小的模型變得夠用,其實也是一種無奈,如果能在同樣的成本下買到規格大得多的芯片,跑一個百億千億模型,支持超長上下文,商業化的空間會比今天大得多,就像曾經的顯卡和游戲行業一樣,當足夠便宜的顯卡已經可以流程跑4k畫質的時候,誰還會覺得1080p的畫質也夠用了呢?兩三年后,隨著芯片行業的發展,不會再有人需要小模型,大模型長文本的高質量Token會變得足夠便宜。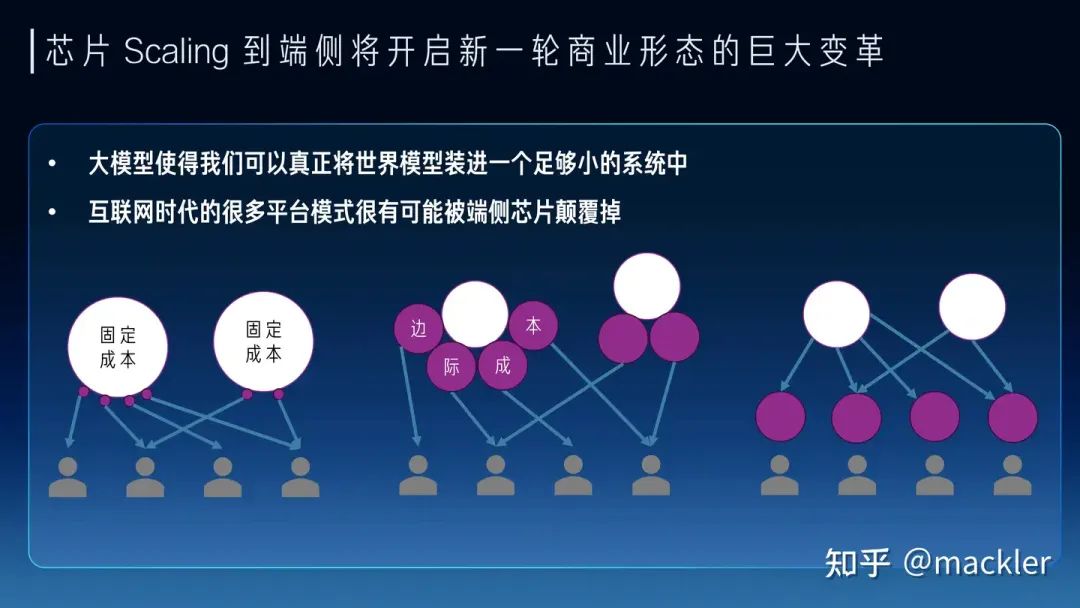 往更長遠看,大模型的成本模型對于商業形態都會產生巨大的變革。很多傳統互聯網業務具有巨大的固定成本,而邊際成本非常低,一個集中式的云往往就是最經濟的商業形態。今天大模型實際上把信息高度壓縮到一個足夠小的系統中,甚至是單個用戶在未來可能承受的。同時,今天大模型服務的邊際成本相比固定成本占比已經非常高,短期內仍然在云端更多是因為邊際成本對于用戶來講還是太高了,并且商業模式也還未大規模爆發,用戶也不會愿意為一個尚未大規模商業化的需求承擔這部分邊際成本。因此未來兩三年內仍然是云端承擔大量的邊際成本來探索商業化的可能性,芯片行業幫助降低成本加速商業化。但隨著大模型大規模商業化爆發,這種成本模型實際上會造成巨大的浪費。試想一下以后我們常用的幾十種不同的應用都獨自提供大模型服務,這些邊際成本對于所有廠商都是巨大的,而羊毛出在羊身上,最終還是會轉嫁到消費者身上,就像今天需要付費訂閱各種大模型廠商。隨著芯片行業進一步降低成本,大模型落到端側會變成總體更加經濟的成本模型。就像今天的游戲市場,游戲畫質的成本是游戲玩家自己買的顯卡來承擔,游戲玩家也無需為想玩的不同游戲單獨為畫質付費,游戲廠商也無需承擔這部分成本。大模型也是類似的,未來芯片的Scaling讓用戶可以在端側低成本跑極高質量的大模型,無需為不同的云端服務承擔獨立的大模型訂閱費用,大模型的高度智能也能更容易打破不同應用之間的壁壘,還能在端側更好地協同起來,實現更好的體驗。當然這和今天AI PC這一類在端側跑低成本的小模型還是有本質區別的,還有待于芯片行業的迭代,讓大家能在比今天更低的成本下跑起來未來的旗艦模型。我們相信大模型能隨著芯片行業的Scaling逐漸低成本走進千行百業,也走進大家的生活。我們也相信在大模型時代,AI芯片迎來了真正商業化的機會,可以把產品定義和供應鏈的問題解決好,也在更多維度創造出更有競爭力的芯片產品。我們行云也希望在未來努力把這些都變成現實。
往更長遠看,大模型的成本模型對于商業形態都會產生巨大的變革。很多傳統互聯網業務具有巨大的固定成本,而邊際成本非常低,一個集中式的云往往就是最經濟的商業形態。今天大模型實際上把信息高度壓縮到一個足夠小的系統中,甚至是單個用戶在未來可能承受的。同時,今天大模型服務的邊際成本相比固定成本占比已經非常高,短期內仍然在云端更多是因為邊際成本對于用戶來講還是太高了,并且商業模式也還未大規模爆發,用戶也不會愿意為一個尚未大規模商業化的需求承擔這部分邊際成本。因此未來兩三年內仍然是云端承擔大量的邊際成本來探索商業化的可能性,芯片行業幫助降低成本加速商業化。但隨著大模型大規模商業化爆發,這種成本模型實際上會造成巨大的浪費。試想一下以后我們常用的幾十種不同的應用都獨自提供大模型服務,這些邊際成本對于所有廠商都是巨大的,而羊毛出在羊身上,最終還是會轉嫁到消費者身上,就像今天需要付費訂閱各種大模型廠商。隨著芯片行業進一步降低成本,大模型落到端側會變成總體更加經濟的成本模型。就像今天的游戲市場,游戲畫質的成本是游戲玩家自己買的顯卡來承擔,游戲玩家也無需為想玩的不同游戲單獨為畫質付費,游戲廠商也無需承擔這部分成本。大模型也是類似的,未來芯片的Scaling讓用戶可以在端側低成本跑極高質量的大模型,無需為不同的云端服務承擔獨立的大模型訂閱費用,大模型的高度智能也能更容易打破不同應用之間的壁壘,還能在端側更好地協同起來,實現更好的體驗。當然這和今天AI PC這一類在端側跑低成本的小模型還是有本質區別的,還有待于芯片行業的迭代,讓大家能在比今天更低的成本下跑起來未來的旗艦模型。我們相信大模型能隨著芯片行業的Scaling逐漸低成本走進千行百業,也走進大家的生活。我們也相信在大模型時代,AI芯片迎來了真正商業化的機會,可以把產品定義和供應鏈的問題解決好,也在更多維度創造出更有競爭力的芯片產品。我們行云也希望在未來努力把這些都變成現實。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

