大模型亂斗,AI芯片狂歡

編輯 | 漠影
大模型正吞噬一切,算力尤甚。芯東西7月7日上海報道,在正在舉辦的第六屆世界人工智能大會(WAIC)上,瀚博半導體、昆侖芯科技、天數智芯、Graphcore、燧原科技、登臨科技、愛芯元智、沐曦、海飛科、墨芯人工智能、知存科技、后摩智能、珠海芯動力、復旦微電、憶芯科技、富瀚微、西安紫光國芯等芯片企業參展。多數均為AI芯片創企。如今AI算力資源緊張已經不是什么秘密,隨著相關算力基礎設施建設進程提速,AI芯片創企的受關注度正水漲船高。這在此次展會上可見一斑,幾乎每家AI芯片展臺都人潮洶涌。從展品可以看到,大多數參展的芯片企業都在積極適應大模型熱潮帶來的市場需求變化,不僅展出更具針對性的硬件產品,還展示了更加廣泛的行業應用Demo,多數展位都有AI大模型或AIGC(AI內容生成)應用的演示專區。

▲瀚博半導體AI大模型演示展臺
當然,這一風向并不令人意外。連權威AI基準測試MLPerf最近都新增了大語言模型和推薦算法兩項新的基準測試,足見跑AI大模型的速度已被視作衡量芯片性能的重要指標。得益于此,今年AI芯片展區明顯要比往年更加熱鬧。隨著更多國內AI芯片成功流片與量產,AI芯片企業們比拼的賽點,已經從單純的性能指標轉向進入真實應用場景落地的較量。01.拼榮譽:兩款AI芯片關聯產品獲得世界人工智能大會最高獎
▲高通獲頒SAIL獎
超10億參數Stable Diffusion模型能夠在搭載第二代驍龍8移動平臺的安卓手機上運行,實現15秒內20步推理。燧原科技面向AIGC模型訓練的液冷集群云燧智算集群摘得了“SAIL之星”獎。該集群采用的燧原科技邃思芯片曾獲2022年吳文俊人工智能專項獎芯片項目一等獎。
▲燧原科技的一系列里程碑式產品
云燧智算集群產品已在國家級重點實驗室之江落地千卡規模訓練集群,提供超過100P的先進AI算力,能高效支撐融媒體、文本生成PPT、跨模態圖像生成等AIGC應用以及多種AI4S科學計算應用的開發和前沿探索。02.拼資歷:昆侖芯十年磨一劍國內首批通用GPU芯片走向增收
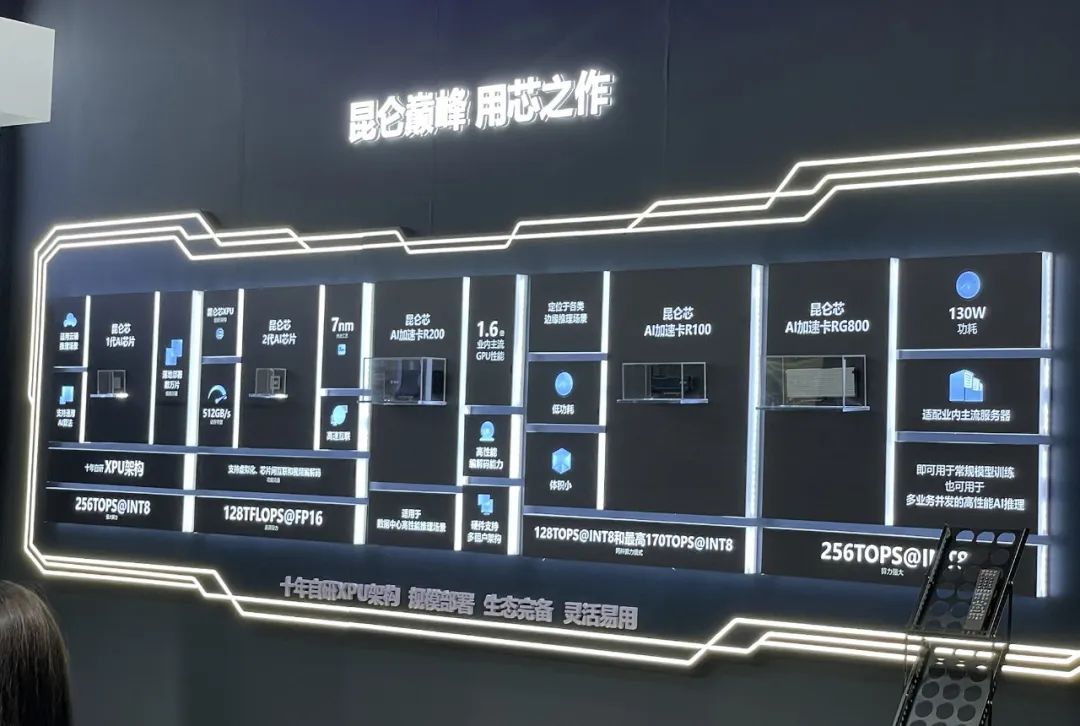
▲昆侖芯歷代AI芯片及AI加速卡
在此次WAIC上,針對不同參數級別的昆侖芯第二代系列產品矩陣首次亮相,包括3款昆侖芯AI加速卡R100、RG800、R200-8F。其大模型端到端解決方案更是繼正式發布后首次參展,該方案在能源行業、文心一格、智源研究院等多個場景均有應用落地。其中,R200-8F面向百億以下參數量級,性能可達到主流GPU 1.2倍且價格更有優勢;R480-X8加速器組針對百億到千億參數量級,大內存和芯片互聯的技術使其性能達到同類型GPU的1.3+倍;千億參數,可采用昆侖芯R480-X8集群,實現多機多卡分布式推理。天數智芯自稱是國內首家真正量產的通用GPU企業,從2018年開始設計通用GPU天垓100至今,已有兩款產品成功進入量產階段。據悉,截至2022年底,天數智芯累計訂單接近6億元,去年全年收入大約2.5億元。
▲天數智芯通用GPU產品展臺
另一家國內通用GPU領軍企業登臨科技自認是國內首家完全憑借自主創新,實現規模化商業落地的通用GPU企業,通過GPU+架構創新,解決了通用性和高效率的雙重難題。經過大量客戶產品化驗證,針對AI計算,GPU+比現有主流GPU在性能及能效上有顯著提升。首款基于登臨GPU+的AI加速器Goldwasser(高凜)2021年量產投入市場,2022年銷售過萬片,應用場景覆蓋互聯網、智慧城市、電力、能源、金融等領域。高凜二代產品在2022年流片, 在2023年實現量產。根據現有客戶測試結果,二代產品針對基于Transformer類型的模型提供3-5倍的性能提升,能夠大幅降低類ChatGPT及生成式AI應用的硬件成本。今日上午,登臨科技還宣布了一個好消息:獲得中國互聯****資基金獨家投資。
▲登臨科技Goldwasser(高凜)六大亮點
03.拼硬件:先進制程扎堆解鎖千億大模型部署
▲瀚博SG100芯片簡介
VA1L具備200TOPS INT8/72TFLOPS FP16算力,并支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC模型。其AIGC大模型一體機共使用8張VA1L加速卡,支持512GB顯存,進而支持1750億參數的大模型。VA12作為250W板卡,是VA1和VA10的升級版,有512TOPS INT8/160TFLOPS FP16算力,能夠更高效地支持文生圖模型Stable Diffusion。珠海芯動力發布首款基于可重構架構的GPGPU芯片RPP-R8。該公司在2017年成功研發出可重構并行處理器(RPP)架構,能夠對AI推理的性能進行深度優化。以RPP架構為基礎、面向邊緣市場設計的第一代芯片RPP-R8已經一次性流片成功,芯動力成為GPGPU領域的新成員。
▲芯動力“六邊形戰士”處理器RPP
據悉,RPP-R8芯片是一款通用型GP-GPU芯片,每顆芯片內含有1024個計算核,相比傳統GPU架構在同樣的算力占用更小的芯片面積,實現了低功耗和高能效的有效平衡。RPP-R8除了具備專用芯片所沒有的通用編程性,面積效率比可達到同類產品的7~10倍,能效比也超過3倍,可滿足高效并行計算及AI計算應用。▲珠海芯動力RPP-R8芯片
其它參展芯片中,天數智芯2018年設計的天垓100加速卡目前已經跑通清華ChatGLM、LLaMA、智源研究院Aquila等大模型。今年6月,天數智芯宣布天垓100率先完成百億級參數大模型訓練。昆侖芯2代AI芯片是國內首款采用GDDR6顯存的通用AI芯片,已經在金融、工業、交通、教育等領域廣泛部署。昆侖芯在軟件層面提供了豐富的云原生插件,幫助用戶快速完成和大模型平臺的適配。其產品矩陣適配文心一言、ChatGLM、GPT、OPT等主流行業大模型,并提供豐富的軟件SDK,幫助用戶快速完成適配和實時自定義的開發。海飛科稱其第一代通用GPU芯片Compass C10是業界首個顯存高達128GB的GPU芯片,達到了算力和存儲容量的優化平衡,實現單卡、多卡分布式部署千億大模型。海飛科展臺演示有在其產品上跑Stable Diffusion、ChatGLM OPT等模型。
▲海飛科Compass C10計算卡
沐曦展示了其AI推理GPU曦思系列、通用計算GPU曦云系列、圖形處理GPU曦彩系列芯片。其中,曦思N100是沐曦面向人工智能推理場景推出的一款高效能GPU產品,單卡算力達160TOPS (INT8)和80TFLOPS (FP16),已實現規模量產,并與多家重點客戶及合作伙伴共同打造應用解決方案和生態聯盟。▲曦思MXN100芯片
曦云C500是沐曦面向AI訓練及通用計算的旗艦產品,提供強大高精度及多精度混合算力,配備大規格高帶寬顯存,片間互聯MetaXLink無縫鏈接多GPU系統,能滿足大模型推理和訓練需求。曦云MXC500芯片已于2023年6月13日完成基礎測試,預計將于今年年底實現量產。
▲曦云MXC500芯片
墨芯Antoum芯片是全球唯一擁有高稀疏率的AI芯片,采用12nm制程。憑借軟硬協同的稀疏計算技術,搭載Antoum芯片的墨芯AI計算卡在權威AI基準測試MLPerf今年4月公布的結果中取得ResNet-50單卡、多卡的性能第一。墨芯AI計算平臺可支持BLOOM、OPT、GPT-J、LLaMA、Stable Diffusion等主流大模型。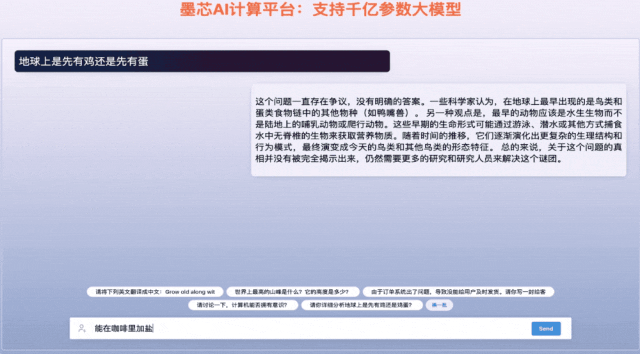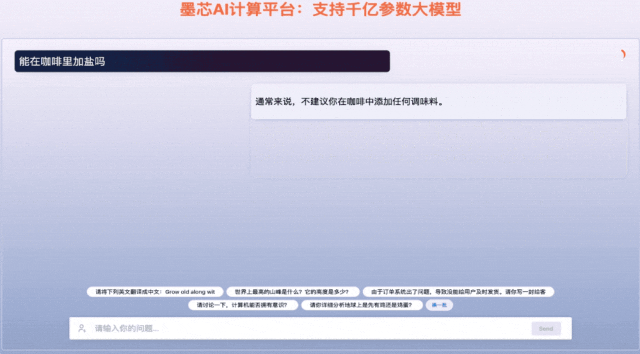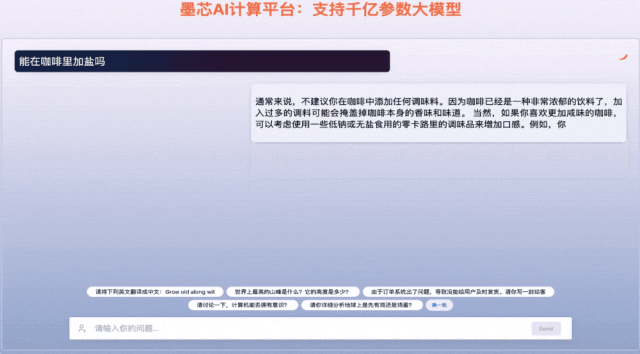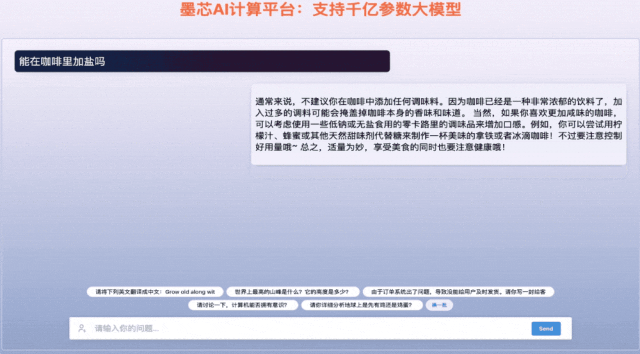
▲墨芯AI計算平臺
英國AI芯片獨角獸Graphcore(擬未)展出了入圍SAIL獎TOP30榜單的云端高端推訓一體加速卡C600,以及世界首款3D Wafer-on-Wafer處理器Bow IPU和基于4個Bow IPU構建的Bow-2000。Bow-2000可提供高達1.4PFLOPS的AI計算能力,并實現顯著的電源效率提升。其C600 IPU處理器PCIe卡在此基礎上增加了用于低精度和混合精度AI的FP8,主打推理,兼做訓練,在搜索和推薦等業務上更具優勢。Graphcore在支持大模型方面一直很積極,目前已部署在其IPU上的包括ChatGLM-6B、GPT2-XL、GPT-J、Stable Diffusion、Dolly 2.0等。Graphcore現場演示了在其IPU上運行中英雙語模型ChatGLM-6B和開源文生圖模型Stable Diffusion。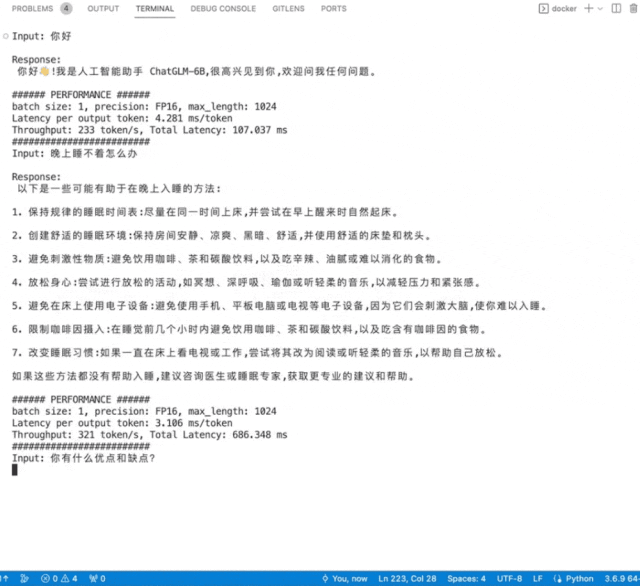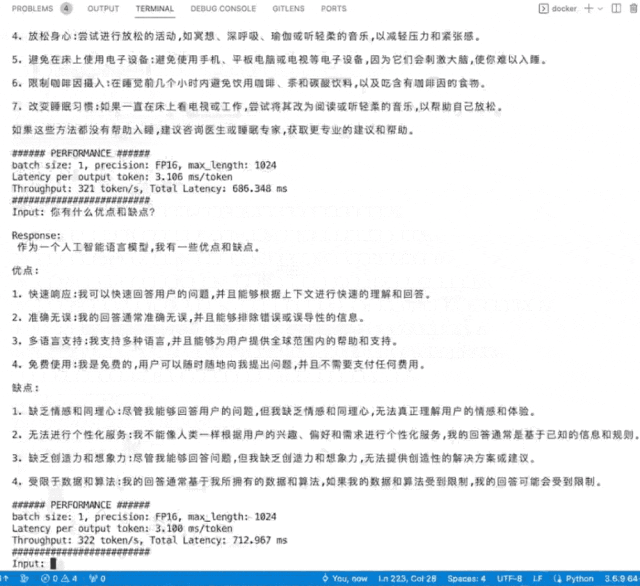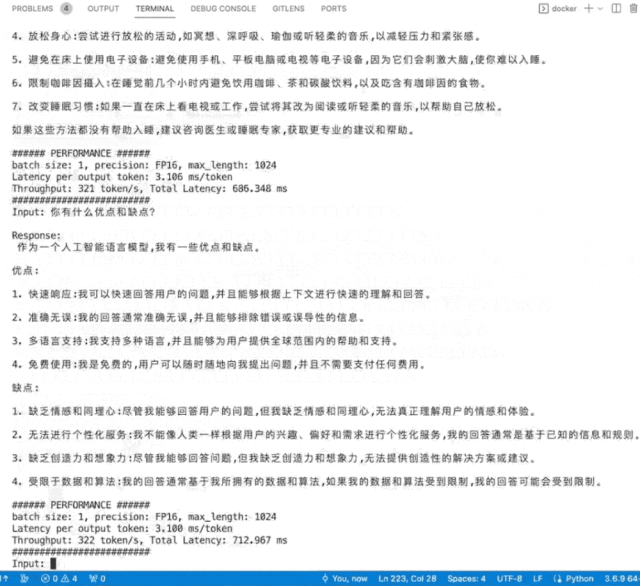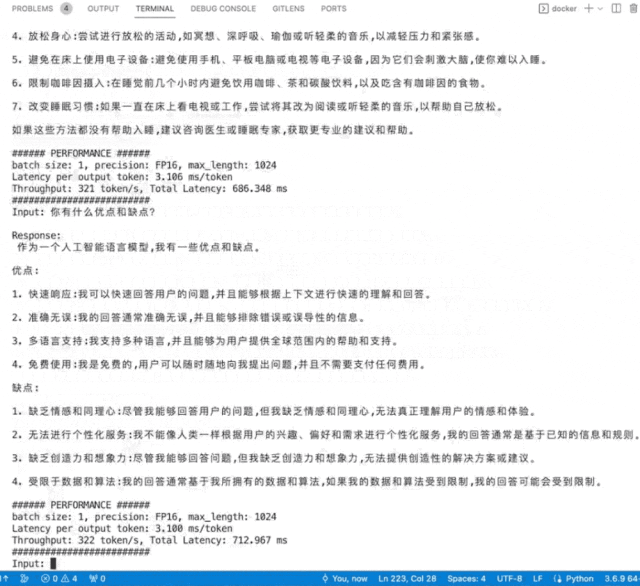
▲ChatGLM-6B模型在IPU上運行秒出多行回復
算能展出了第四代邊云大算力AI芯片算豐BM1684X,以及首款基于RISC-V指令集架構的64核服務器CPU芯片算豐SG2042。每臺基于SG2042的服務器會配置1張萬兆光纖網卡,并根據硬盤配置選配RAID卡,使整個系統的操作起來與x86系統一樣方便。
▲算豐RISC-V SG2042服務器簡介
聚焦于計算+感知應用的愛芯元智,在WAIC上重點展示了第三代高算力、高能效比SoC芯片AX650N和M55、M76系列智能駕駛芯片。AX650N現已適配ViT/DeiT、Swin/SwinV2、DETR等Transformer模型,在DINOv2達到30幀以上的運行結果。Transformer網絡SwinT在AX650N平臺上實現了361FPS的高性能、80.45%的高精度、199FPS/W的低功耗以及原版模型且PTQ量化的極易部署能力。
▲愛芯元智邊、端側Transformer大模型展臺
04.拼落地:滿場大模型運行Demo大曬應用案例與生態朋友圈
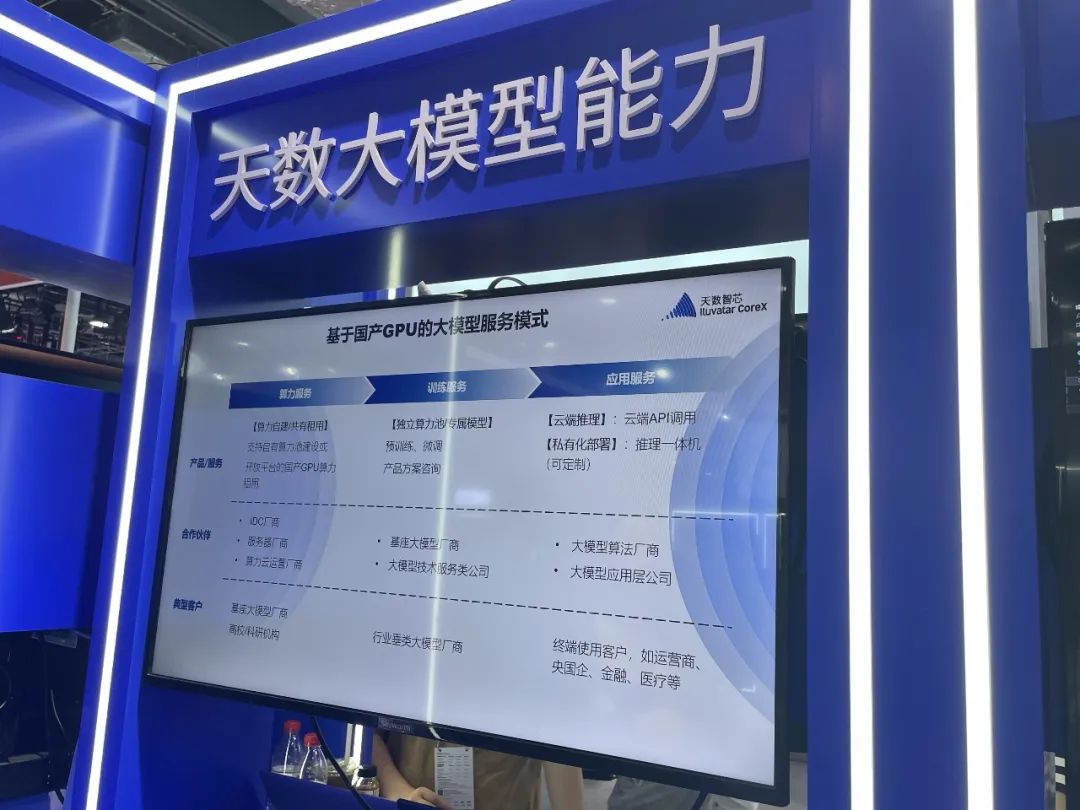
▲天數智芯大模型能力
燧原科技7月5日剛推出的新品燧原曜圖(Enflame LumiCanvas)文生圖MaaS平臺服務產品在展會現場受到很多關注。這是燧原繼3月宣布升級企業戰略“以全棧軟硬件和集群產品為數字底座,結合MaaS的業務模式,全面打造AIGC時代的基礎設施”后的首款新品。這也是燧原在AIGC戰略布局的第一步,后續燧原還將繼續推出其它MaaS服務。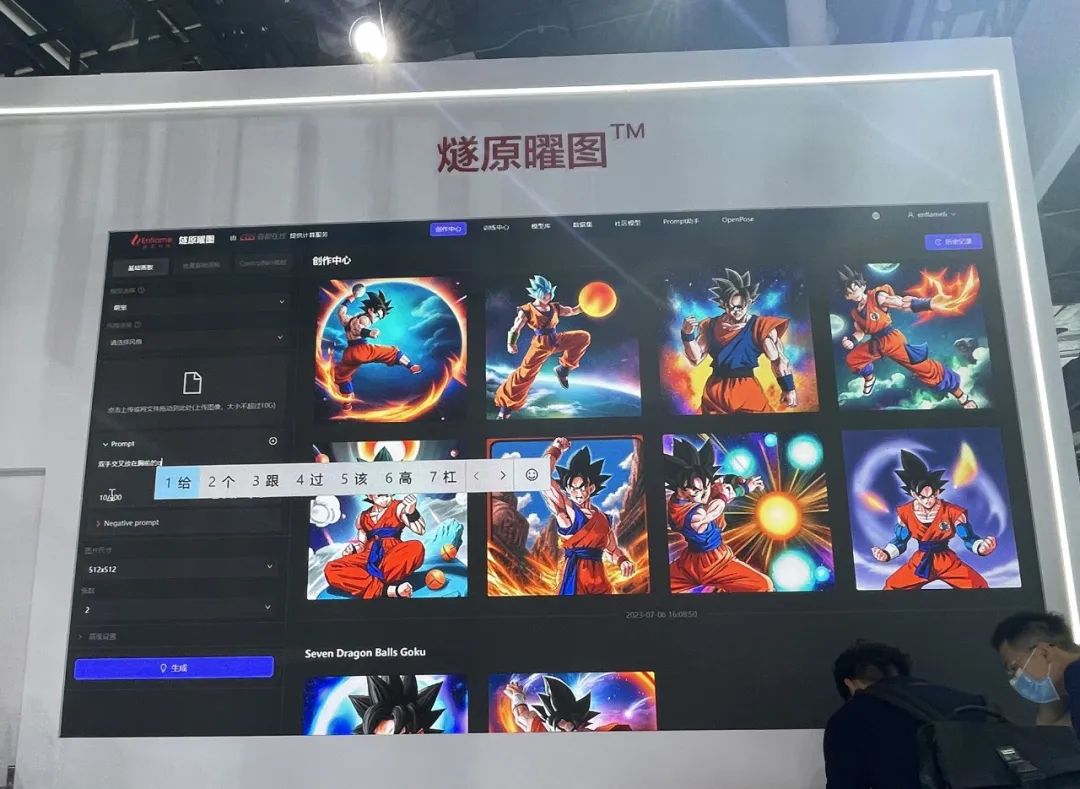
▲燧原曜圖文生圖MaaS平臺服務產品
燧原曜圖以燧原科技邃思系列芯片為算力支撐,由首都在線提供計算服務,集成了圖像預處理、姿態建模、外部模型一鍵導入等能力,能夠大批量生成圖像,通過軟硬一體方案降低大規模AIGC應用的工程難度與算力成本。這個企業級文生圖應用支持以Excel形式批量導入prompt,單次最高可支持千條prompt導入,并針對視覺創作領域專業術語海量且繁復的問題,為用戶提供prompt詞典、大師經典作品prompt模板沉淀、逆向prompt等在內的全面Prompt工具體系。除了燧原曜圖外,燧原還展出了有多個可交互設施的AIGC交互演示體驗區,包括ChatBCG(文生PPT)、LLaMA(聊天機器人)、由清華ChatGLM和Stable Diffusion組成的能回復文字和圖片的ChatBot(聊天機器人)等。
▲燧原AIGC交互演示展區
墨芯人工智能在WAIC期間發布了大模型算力方案的最新成果,展示1760億參數的大語言模型BLOOM在墨芯AI計算平臺的推理引擎支持下,能夠快速、流暢地回答各類問題,并完成詩歌創作、文案撰寫等多項語言生成任務。在1300億參數ChatGLM大模型上,8張墨芯S30計算卡吞吐達432token/s,性能超過主流GPU。天數智芯亦展出了豐富的應用演示,包括大模型微調、大模型推理、代碼生成、AI繪畫、內容審查、虛擬數字人、隱私計算、風電場巡檢、智慧語義、人臉比對、智算中心、3D建模、科學計算、智能OCR、目標檢測/缺陷檢測、智慧零售等,充分展示了其GPU產品的通用性。
▲天數智芯合作伙伴
登臨科技設置了大模型、創新應用、AIDC、創新硬件四大主題展區,和合作伙伴一起展出了數十種產品方案,包括大模型、步態識別、數字孿生、無人機、智慧金融、智慧電力、智慧能源、智慧園區、車路協同、智慧社區、智慧交通等,并展示了其生態朋友圈。▲登臨瀚海生態合作伙伴
燧原科技也曬出了生態合作伙伴。
▲燧原科技生態合作伙伴
雖然昆侖芯并未在展臺設置關于AIGC應用的互動演示,但百度文心大模型早已是昆侖芯的金字招牌。值得一提的是,百度并沒有因為昆侖芯是自家孩子而排斥其他AI芯片企業。百度展臺上有一張標注飛槳在WAIC上的硬件伙伴們展位的地圖,愛芯元智、登臨科技、沐曦、昆侖芯、海飛科、墨芯人工智能、算能、燧原科技、瀚博半導體、天數智芯、Graphcore均在其中。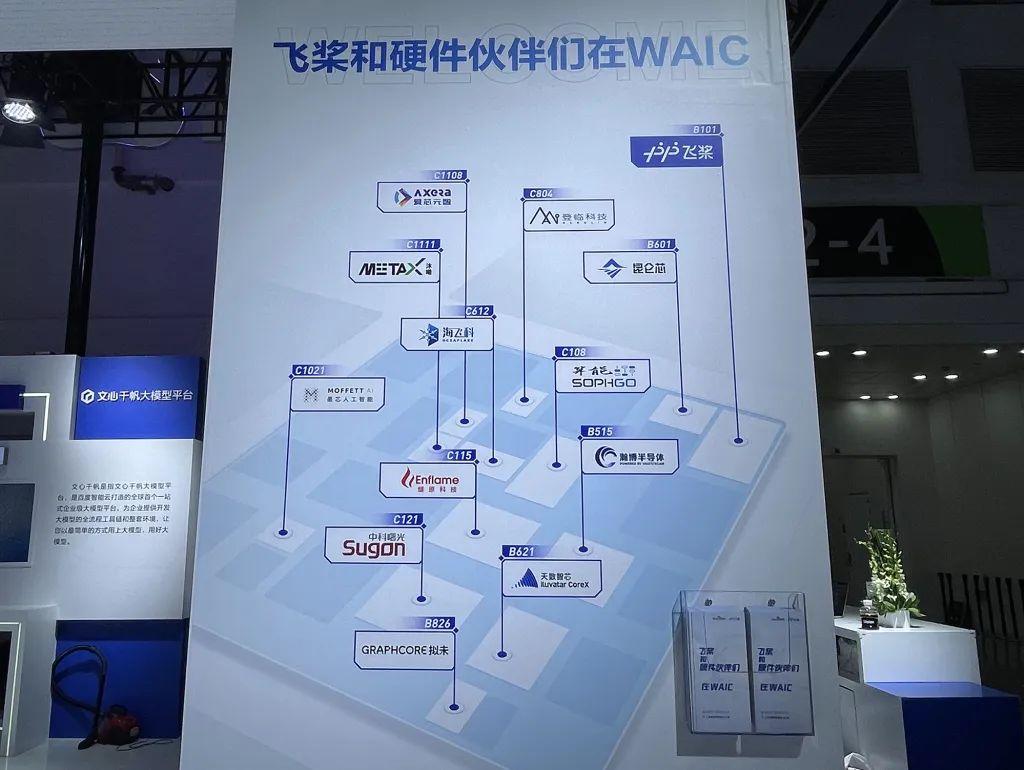
▲百度飛槳和硬件伙伴在WAIC
05.結語:上海近年已有30多款AI芯片點亮

▲后摩鴻途H30芯片
國內FPGA龍頭復旦微電重點展示了基于自研FPAI(可重構人工智能)芯片的一站式AI解決方案。憶芯科技展出了企業級SSD芯片等多種解決方案。西安紫光國芯則展出了世界領先的嵌入式DRAM(SeDRAM)、高帶寬高性能板卡解決方案HBX-G500等科技創新成果。目前,上海集聚了全國最多的智能芯片創新企業,近年已有30多款AI訓練芯片、AI推理芯片、車載芯片點亮,這些積累為通用大模型發展和落地普及打下了算力基礎。*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

