在ADSP-BF561上實現與優化的H.264

目前,音視頻技術日新月異,其中,視頻實時編碼傳輸極具代表性。在視頻壓縮算法領域,新一代視頻壓縮標準H.264以其優異的壓縮性能和圖像質量使視頻實時編碼傳輸技術的實現成為可能。但該標準的計算復雜度高,用一般的圖像處理芯片難以達到實時編解碼的要求,它需要快速、穩定的處理器作為硬件平臺。ADSP-BF561是ADI公司推出的高性能多媒體處理器。其主要特點是具有兩個ADSP-BF533處理器核心(以下簡稱核心A和核心B),最高時鐘頻率達到600MHz,其內部采用哈佛總線結構,存儲模型層次化。其典型應用模式是A核運行嵌入式操作系統,B核運行多媒體處理算法,如H.264。本文提出了一套采用ADSP-BF561芯片實現H.264視頻壓縮算法的設計方案,結合該DSP平臺對算法進行了針對性的優化,充分發揮了ADSP-BF561強大的處理能力。
1 算法介紹
1.1 H.264編碼模型框架
H.264以其高壓縮比、高圖像質量和良好的網絡親和性廣受業界歡迎。在同等質量條件下,H.264的數據壓縮比比MPEG-2高2~3倍,比MPEG-4高1.5~2倍。其需要的帶寬只有MPEG-4的50%, MPEG-2的12.5%。
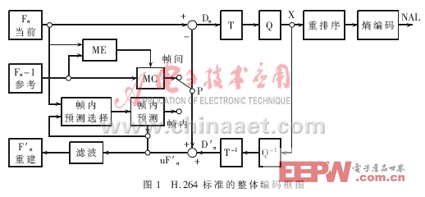
H.264標準采用分層體系結構,系統分為:視頻編碼層VCL(Video CodingLayer),負責高效的數字視頻壓縮;網絡抽象層NAL(Network AbstractionLayer),負責對數據進行打包和傳送。H.264編碼圖像通常分為三種類型:I幀、P幀、B幀。I幀為幀內編碼幀,其編碼不依賴于已編碼的圖像數據。P幀為前向預測幀,B幀為雙向預測幀,編碼時都需要根據參考幀進行運動估計。同時,H.264在提高圖像傳輸容錯性方面做了大量工作,重新定義了適于圖像的結構劃分。在編碼時,圖像幀各部分被劃分到多個Slice結構中,每個Slice都可以被獨立編碼,不受其他部分影響。Slice由圖像最基本的結構——宏塊組成,每個宏塊包含一個16×16的亮度塊和兩個8×8的色度塊。H.264標準的整體編碼框圖如圖1所示。編碼過程中,原始數據進入編碼器后,當采用幀內編碼時,首先選擇相應的幀內預測模式進行幀內預測,隨后對實際值和預測值之間的差值進行變換、量化和嫡編碼,同時編碼后的碼流經過反量化和反變換之后重構預測殘差圖像,再與預測值相加得出重構幀,得出的結果經過去塊濾波器平滑后送入幀存儲器。采用幀間編碼時,輸入的圖像塊首先在參考幀中進行運動估計,得到運動矢量。運動估計后的殘差圖像經整數變換、量化和嫡編碼后與運動矢量一起送入信道傳輸。同時另一路碼流以相同的方式重構后,經去塊濾波后送入幀存儲器作為下一幀編碼的參考圖像。
1.2 H.264關鍵技術
1.2.1 幀內預測
H.264引入了幀內預測以提高壓縮效率。幀內預測編碼就是利用周圍鄰近的像素值來預測當前的像素值,然后對預測誤差進行編碼。這種預測是基于塊的。對于亮度分量,塊的大小可以在16×16和4×4之間選擇,16×16有4種預測模式,4×4有9種預測模式;對于色度分量,預測是對整個8×8塊進行的,有4種預測模式。
1.2.2 幀間預測
幀間預測時所用塊的大小可變。假設基于塊的運動模型,其塊內的所有像素都做了相同的平移,在運動比較劇烈或者運動物體的邊緣外,這一假設會與實際出入較大,從而導致較大的預測誤差,這時減小塊的大小可以使假設在小塊中依然成立。另外小塊所造成的塊效應相對也小,因此,小塊可以提高預測的效果。H.264一共采用了7種方式對一個宏塊進行分割,每種方式下塊的大小和形狀都不相同,編碼器可以根據圖像的內容選擇最好的預測模式。與僅使用16x16塊進行預測相比,使用不同大小和形狀的塊可以使碼率節約15%以上。
同時,幀內預測采用了更精細的預測精度,H.264中亮度分量的運動矢量使用1/4像素精度。色度分量的運動矢量使用1/8像素精度。
1.2.3 多幀參考
H.264支持多幀參考預測,最多可以有5個在當前幀之前的解碼幀作為參考幀產生對當前幀的預測,提高H.264解碼器的錯誤恢復能力。
1.2.4 整數變換
H.264對殘差圖像的4×4整數變換技術,采用定點運算來代替以往DCT變換中的浮點運算。以降低編碼時間,同時也更適合硬件平臺的移植。
1.2.5 熵編碼
H.264支持兩種熵編碼方法,即CAVLC(基于上下文的自適應可變長編碼)和CABAC(基于上下文的自適應算術編碼)。其中CAVLC的抗差錯能力比較高,但編碼效率比CABAC低;而CABAC的編碼效率強,但需要的計算量和存儲容量更大。
1.2.6 去方塊濾波
去方塊濾波的作用是消除經反量化和反變換后重建圖像中由于預測誤差產生的塊效應,從而改善圖像的主觀質量和預測誤差。經過濾波后的圖像將根據需要放在緩存中用于幀間預測,而不是僅僅用來改善主觀質量,因此該濾波器位于解碼環中。對于幀內預測,使用的是未經過濾波的重建圖像。
2 算法實現
2.1 平臺選擇
2.1.1 ADSP-BF561芯片介紹
ADSP-BF561是Blackfin系列中的一款高性能定點DSP視頻處理芯片。其主頻最高可達750MHz,內核包含2個16位乘法器MAC、2個40位累加器ALU、4個8位視頻ALU,以及1個40位移位器。該芯片中的兩套數據地址產生器(DAG)可為同時從存儲器存取雙操作數提供地址,每秒可處理1 200兆次乘加運算。芯片帶有專用的視頻信號處理指令以及100KB的片內L1存儲器(16KB的指令Cache,16 KB的指令SRAM,64 KB的數據Cache/SRAM,4 KB的臨時數據SRAM)、128KB的片內L2存儲器SRAM,同時具有動態電源管理功能。此外,Blackfin處理器還包括豐富的外設接口,包括EBIU接口(4個128 MBSDRAM接口,4個1MB異步存儲器接口)、3個定時/計數器、1個UART、1個SPI接口、2個同步串行接口和1路并行外設接口(支持ITU-656數據格式)等。Blackfin處理器在結構上充分體現了對媒體應用(特別是視頻應用)算法的支持。
2.1.2 ADSP-561 EZkite
ADSP-BF561視頻編碼器平臺采用ADI公司的ADSP-BF561 EZ-kitLite評估板。此評估板包括1塊ADSP-BF561處理器、32 MB SDRAM和4 MBFlash,板中的AD-V1836音頻編解碼器可外接4輸入/6輸出音頻接口;而ADV7183視頻解碼器和ADV7171視頻編碼器則可外接3輸入/3輸出視頻接口。此外,該評估板還包括1個UART接口、1個USB調試接口和1個JTAG調試接口。攝像頭輸入的模擬視頻信號經視頻芯片ADV7183A轉化為數字信號,此信號從ADSP-BF561的PPI1(并行外部接口)進入ADSP-BF561芯片進行壓縮,壓縮后的碼流則經ADV7179轉換后從ADSP-BF561的PPI2口輸出。此系統可通過Flash加載程序,并支持串口及網絡傳輸。編碼過程中的原始圖像、參考幀等數據可存儲在SDRAM中。
2.2 算法選取與優化方案
2.2.1 算法選取
H.264實現的源代碼不止一種,其中最常見的有JM、X264和T264。對比這三種實現源代碼,X264比T264具有更高的效率。而且相比廣泛采用的JM編碼模型,X264在兼顧編碼質量的同時大幅度地提升了編碼速度,所以選取X264作為算法原型。
2.2.2 優化方案
該優化方案從三個層次對算法進行優化:算法層次、代碼層次、平臺層次。下面介紹具體優化方法。
2.2.2.1 編碼器具體參數的選擇
該編碼器使用main檔次,I、B、P幀量化值分別為26、31、29,流控參數選為CBR。IDR幀間隔設為50,B幀間隔為2幀。這樣的選擇是為了在速度和運算量上取折中。選用B幀并將其量化值加大,可比baseline檔次、IPPP結構提高約10%的壓縮率。而B幀的計算量,因其不用做參考幀,故無需進行去塊濾波和插值計算,在31的qp下,很多塊會被判做skip模式編碼,因而多數時B幀總運算量候反而較P幀低。
2.2.2.2 算法層次的優化
算法層次的優化主要是指在參數選定的情況下,對部分算法所作的替換或優化。和參數的選擇一樣,算法層次優化也主要受優化策略的指導。如運動匹配準則是選用SSD、SAD或SATD。如果只看中準確程度,則選擇SSD最佳;如果只看中運行速度,則選擇SAD最佳;如果要兼顧二者,則選用SATD是比較好的一個方案。在進行算法優化時還應該注意一個問題,即要考慮實際運行平臺的支持情況。如在追求速度的策略下,匹配準則選用SAD,如果只計算一半的點則會大大降低運算速度。但是如果考慮ADSP-BF561匯編指令的設計情況,就會發現這樣做反而會增加指令數,會使速度更低。算法層次優化包括如下幾個部分:
(1)除法求余。改進策略是浮點型算法盡量改為整型,64位盡量改為32位,32位盡量改為16位。而對于某些計算比較多的,則改為查表計算。在ADSP-BF561平臺上,一次32位整形除法需耗時300個CYCLE,而查表僅需幾個CYCLE,這樣的改進能顯著提高速度。
(2)飽和函數。在視頻的計算中,幾乎每次像素的計算都會調用飽和函數,X264代碼的實現中已將這部分代碼改為查表函數,在其他的編解碼器實現中也有將這部分改為一個判斷和幾個邏輯運算的形式。對大部分DSP平臺,采用判斷跳轉會打斷流水線,即使平臺有比較好的跳轉預測功能,打斷流水仍然會造成stall。所以查表方法是一種高效方法。而在ADSP-BF561匯編指令中,可以通過設置指令后綴或使用某些特殊指令來進行飽和工作。甚至不用查表,在不同的場合使用不同的飽和算法能大大提高代碼的執行效率。
(3)MC部分函數。實測中發現MC部分函數運行效率不如ffmpeg解碼器中MC部分效率高,所以將這部分代碼用ffmpeg中的相應部分替換。此外qpel16_hv函數中計算有冗余,減少這些冗余能提高代碼運行效率。
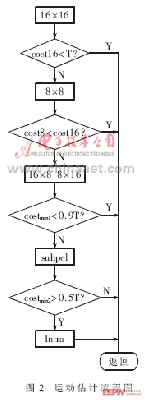
(4)算法替代和改進。幀間預測的改進:關于算法的改進主要集中在對me(motionestimation)的改進上,流程如圖2所示。costmin1=min(cost16,cost8,cost16×8,cost8×16),costmin2=min(costmin1,costsub),依次在16×16、8×8、16×8和8×16大小宏塊的整像素位置做預測,再做次像素估計和幀內預測,選用匹配準則函數(采用sad作為匹配準則函數)取得最小值的模式進行編碼。每計算一種模式,都將sad值與一個經驗閥值做比較。當sad值小于這個閥值時,立即結束運動估計,從而減少運算量。
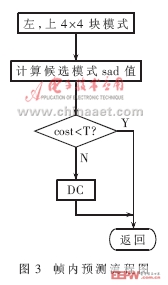
幀內預測的改進:H.264標準所采用的幀內預測模式除了DC模式都具有方向性,相鄰4×4塊都具有相關性。根據這樣的相關性,只將當前4×4塊上邊和左邊選用預測模式及其相鄰的兩種預測模式作為當前4×4塊的預測模式,當其閥值都大于一個經驗閥值時,才采用DC模式。這樣的方案不用一一計算9種預測模式,在復雜度、編碼效率、質量和速度上取了一個折中。流程如圖3所示。
2.2.2.3 代碼層次優化
針對ADSP-BF561平臺,代碼層次的優化工作包括以下幾個方面:
(1)內聯函數。將經常調用的函數體較小的函數改為內聯。編譯條件中有關于內聯函數優化的選項。內聯函數的使用是將代碼的大小和運行效率取一個折中。根據實際情況,代碼的大小并非限制條件,所以應盡可能多地使用內聯函數。在項目配置中選中when declared inline選項。
(2)跳轉預測。ADSP-BF561采用了靜態預測的方式來預測有條件判斷情況,預測不成功會造成4~8個內核時鐘(CCLK)的延誤。如果事先知道某些跳轉的概率,將可能性最大的分支放在最前面,可以從概率上降低預測不成功而造成的stall。
(3)使用硬件支持循環。對于大部分平臺,將一些循環體小的循環展開也能提高效率。ADSP-BF561有兩組硬件計數器用以支持循環。所以除非是展開三層以上的循環,否則,展開循環體不能提高效率。
(4)內存。嵌入式系統的內存是非常寶貴的資源。避免頻繁的動態申請和釋放內存,能減少碎片產生,提高內存的利用率。X264工程也不會頻繁地申請釋放內存。在項目中,具體做法是編寫平臺相關的malloc和free函數。將經常使用的中間數據在L1數據空間中分配。
(5)注釋不需要代碼。去掉代碼中不需要的部分,主要會去掉CAVLC以及部分碼率控制、csp、cpu、信息統計、調試和psnr計算等部分代碼,這樣做的目的是為了減小文件大小和去除代碼中的一些跳轉。不建議刪除代碼,可以使用注釋符或用宏切換的方式,以防止以后參數改變時需要使用未使用過的代碼。
2.2.2.4 平臺層次優化
ADSP-BF561相應的編程參考和硬件參考對其平臺特性有詳細介紹。一些平臺自帶的優化功能,如CACHE的開啟和配置等不專門在此討論。





評論