摩爾線程新方法優化AI交互:顯存節省最多82%

摩爾線程科研團隊近日發布了一項新的研究成果《Round Attention:以輪次塊稀疏性開辟多輪對話優化新范式》,使得端到端延遲低于現在主流的Flash Attention推理引擎,kv-cache顯存占用節省最多82%。
本文引用地址:http://www.j9360.com/article/202503/467631.htm
近年來,AI大型語言模型的進步,推動了語言模型服務在日常問題解決任務中的廣泛應用。
然而,長時間的交互暴露出兩大顯著問題:
首先,上下文長度的快速擴張因自注意力機制的平方級復雜度而導致巨大的計算開銷;
其次,盡管鍵值(KV)緩存技術能緩解冗余計算,但顯著增加的GPU內存需求,導致推理批處理規模受限,同時GPU利用率低下。
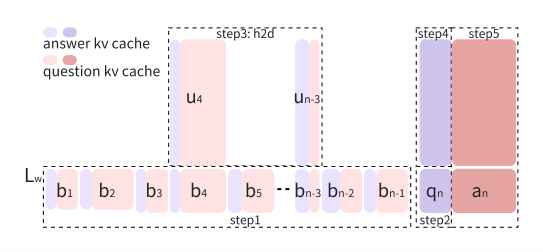
為此,摩爾線程提出了Round Attention,以解決這些問題。
首先,摩爾線程提出以輪次為分析單元研究Attention規律:
Round Attention專為多輪對話場景推理需求設計,以輪次為自然邊界劃分KV緩存。研究發現,輪次粒度的Attention分布存在兩個重要規律。
其次,摩爾線程提出了Round Attention推理流水線;
基于發現的兩個規律,將稀疏性從Token級提升至塊級,選取最相關的塊參與attention計算,減少attention計算耗時,并將不相關的塊卸載到CPU內存,以節省顯存占用。
這在保持推理精度的情況下,減少了推理耗時,降低了顯存占用。
摩爾線程認為,輪次塊稀疏性有三大優勢:自然邊界的語義完整性、分水嶺層的注意力穩定性、端到端的存儲與傳輸優化。
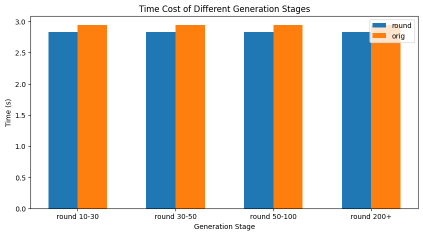
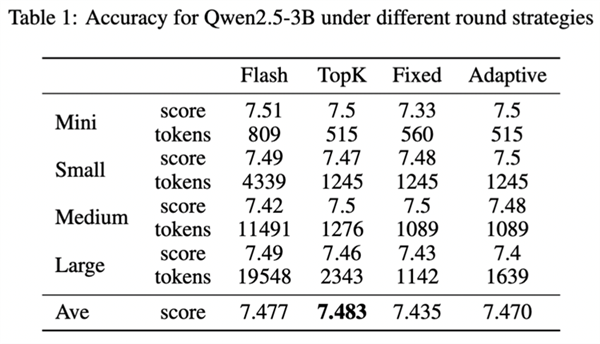
測試顯示,Round Attention的端到端延遲低于現在主流的Flash Attention推理引擎, kv-cache顯存占用則節省55-82%,并且在主觀評測和客觀評測兩個數據集上,模型推理準確率基本未受影響。



評論