以CPU迎接AI算力挑戰,第五代英特爾至強究竟“強”在何處?

ChatGPT引發的AI大模型概念已經持續火爆一年,直至今日,AI的熱度不僅沒有下降,行業也迸發出越來越多具有顛覆性的應用。2024年初以來,AI PC、AI手機、AI邊緣等產品相繼開售,過年期間,Sora又引發了大規模討論。
本文引用地址:http://www.j9360.com/article/202403/456592.htm可以說,AI領域,永遠都在革新。但隨著大模型對算力需求的高速增長,現階段生產的芯片很難滿足業界需求。
在AI熱潮之中,GPU、AISC等加速器是行業中的主角。而事實上,任何數據中心都無法脫離CPU,比喻起來就是魚和水的關系。去年12月,英特爾第五代至強可擴展處理器(代號為Emerald Rapids)正式面世,它有著許多令人驚喜的AI秘籍。
做AI,只有一個選擇?
眾所周知,面對大模型這一新風口,全球科技公司均將目光投向了AI芯片,特別是GPU。但GPU的產量與HBM,或者說2.5D封裝能力直接掛鉤。這讓本就供應吃緊的GPU再遇瓶頸,導致供需嚴重失衡。
與之相悖的是,眼下AI大模型“拼殺”的關鍵在于做大參數量,用“力大磚飛”實現更為強大的智能涌現。可以說,即便是面對AI芯片漲價,多少公司也會選擇購買,畢竟錯過這個風口,或許就會失去競爭力。
對于大型數據中心來說,每顆芯片都在牟足力氣,全功率地運行著,如果能擁有更多AI性能,那么,還需要額外購置一批GPU嗎?
事實上,我們都陷入了一種思維定勢,其實跑AI并非只有GPU一個選擇,CPU也已經具備很強大了AI性能。
亞信科技就在自家OCR-AIRPA方案中采用了CPU作為硬件平臺,實現從FP32到INT8/BF16的量化,從而在可接受的精度損失下,增加吞吐量并加速推理。將人工成本降至原來的五分之一到九分之一,效率還提升5~10倍。
被改變的,不只是互聯網和通信領域,AI制藥被看作是終結藥物研發“雙十定律”的希望,在這個領域中AlphaFold2 這類大型模型被視為最重要的算法。去年開始,至強可擴展平臺就開始使AlphaFold2端到端的通量提升到了原來的23.11倍,而第四代可擴展處理器讓這個數值再次提升3.02倍。
可以說,將CPU用于AI推理正在不斷證實可行。而現在,第五代至強可擴展處理器能夠在無需添加獨立加速器的前提下,運行高達200億參數的模型推理,且延遲低于100毫秒。一款為AI加速而生,且表現更強的處理器誕生了。
CPU,怎么讓AI跑起來
很多人會奇怪,為什么第五代至強作為一個通用處理器,能夠運行AI負載?事實上,除了本身落在第五代至強的AI負載,其中內置的一系列的加速器是關鍵。
這種設計可以與時下MCU(單片機)的流行做法進行對比,通過內置DSP、NPU,分走一部分部分AI負載,讓AI任務跑得更高效,從而更省電,至強也是類似的原理。
這種設計在早期的至強可擴展處理器中就出現過,只不過,那時候大家沒有過多關注,也沒有那么AI任務需要跑。
具體看第五代至強,其內置的英特爾AVX-512及英特爾? AMX(英特爾?高級矩陣擴展)功能是關鍵,這兩個加速器在第四代至強中就已搭載,而在第五代至強中,AMX支持新的FP16指令,同時混合AI工作負載性能提高2~3倍。
加之第五代至強本身性能的提升,使其本身性能就能更從容應對AI負載:CPU核心數量增加到64個,單核性能更高,每個內核都具備AI加速功能;采用全新I/O技術(CXL、PCIe5),UPI速度提升。
根據行業人士分析,CPU做大模型推理,最大的難點不在計算能力,而在內存帶寬。第五代至強的內存帶寬從4800 MT/s提高至5600 MT/s,三級緩存容量提升至近3倍之多,同時插槽可擴展性,支持從一個插槽擴展至八個插槽,這些都為第五代至強支持大模型提供了堅實的后盾。

從數據上來看,與上一代產品相比,第五代至強相同熱設計功耗下平均性能提升21%;與第三代產品比,平均性能提升87%。相較于前一代產品,第五代至強不僅迭代了性能,還帶來了42%的AI推理性能提升。
此外,在一系列加速器中,英特爾?可信域拓展(英特爾? TDX)提供虛擬機(VM)層面的隔離和保密性,從而增強隱私性和對數據的管理。
不止如此,第五代至強還是迄今為止推出的最“綠色”的至強處理器,它能夠幫助用戶管理能耗,降低碳足跡。可以說,軟件只是一方面,歸功于第五代至強內的多種創新技術和功能,搭配干活,效率更高,最終體現出來的就是更低的功耗。
CPU未來發展趨勢,一定是拼功耗,這需要全方位發力。首先是工藝,隨著工藝逐漸提升到Intel 3、Intel 20A、Intel 18A,功耗會越來越低,每一代都會有兩位數的功耗降低。封裝也一樣,使用先進的封裝技術把不同制程的芯片通過Chiplet架構放在一起,進行一個運算,并不需要把所有地方都用起來,而是只使用對應的區域,這樣功耗自然就降低了。還有,就是針對不同的工作負載做優化。
有時候調整應用程序的架構也可以最大限度地降低功耗。舉例來說,如果要訓練大模型,假設總共有20個大模型,每個模型的訓練周期為3個月,需要1000臺機器來訓練,每臺機器功率為1萬瓦。如果規定只需訓練其中的5個模型,而剩下的15個模型不需要訓練,這樣就能節省75%的電能。因此,有時候通過調整應用程序的架構,可以更有效地降低功耗。
“隨著算力的持續高速發展,如何實現數據中心的節能減碳,改變‘電老虎’的形象,對尋求采用可再生能源和更環保的技術方面有了更高的需求。”英特爾數據中心與人工智能集團副總裁兼中國區總經理陳葆立對AI大模型時代提出了這樣的擔憂,第五代至強就是節能減碳的關鍵。
與此同時,英特爾也有一系列的產品和技術創新,如通過更高效的冷卻技術、智能能源管理系統等推動新型和存量數據中心進行節能減排,并攜手中國合作伙伴推動應用落地。
英特爾如何支撐起AI開發
GPU的發展,軟件生態也起到了至關重要的作用,比如行業無人不知的CUDA。對英特爾來說,軟件一直以來都是強項,與此同時,英特爾發力軟件堆棧,不斷加大投資,這為第五代至強在AI方面的發展帶來了巨大的天然優勢。
英特爾一直以來,都比較強調統一性和易用性,在AI方面亦如如此。開發者可以通過利用OpenVINO,實現“一次編寫,隨處部署”的愿景。英特爾開發的基礎軟件和數據庫通過Pytorch和ONNX Runtime等流行框架支持自身的 CPU、GPU、IPU和AI加速器。
此外,英特爾還提供了PyTorch和TensorFlow的庫擴展,這將有助于開發者使用默認安裝運行這些擴展以獲得最新的軟件加速。這意味著,用戶既可以繼續使用PyTorch或TensorFlow,也可以利用OpenVINO進行開發,掌握不同語言的開發者都能在同樣一個平臺下開發。
值得一提的是,OpenVINO 2023.1版本正在加速英特爾追求的“任何硬件、任何模型、任何地方”的目標實現,即逐步擴展OpenVINO成為跨客戶端與邊緣端的、針對推理與部署運行AI模型的完整軟件環境。
“我認為ChatGPT技術不僅僅是關于人類語言、英語語言,還有編程語言。因此,可以實現生產力的提高。你可以從ChatGPT和其他類似的技術中生成自動代碼審查。我認為這里有許多機會,但我認為它存在于行業領先公司正在使用的Python編程模型中。它不是剛剛興起的,已經出現了一段時間,我們極客稱為SMLAR技術。”英特爾專家曾經這樣分享道。
簡單解釋,就是“雞生蛋、蛋生雞”的關系,也就是說,未來AI大模型還會用在開發AI大模型上。現在CUDA就已經開始有了這樣的動作,英特爾也正蓄勢待發。
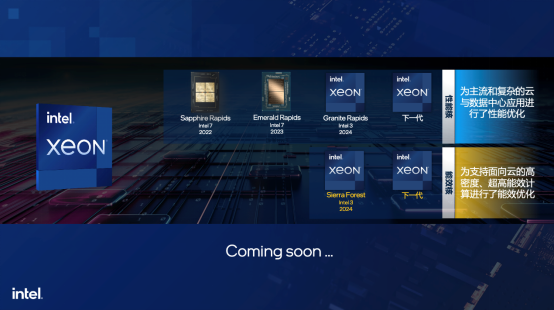
在2月末剛剛結束的MWC2024上,英特爾展示了最多具備288個核心的能效核(E-core)處理器Sierra Forest,性能核(P-core)處理器Granite Rapids 也正蓄勢待發。可以說,未來在AI推理領域,至強還會更強。







評論