一文讀懂什么是智能數據分析?

一、什么是智能數據分析?
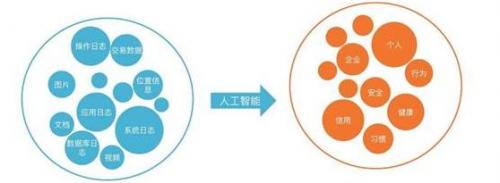
本文引用地址:http://www.j9360.com/article/201810/393569.htm智能數據分析,它是指運用統計學、模式識別、機器學習、數據抽象等數據分析工具從數據中發現知識的分析方法。智能數據分析的目的是直接或間接地提高工作效率,在實際使用中充當智能化助手的角色,使工作人員在恰當的時間擁有恰當的信息,幫助他們在有限的時間內作出正確的決定。
智能數據分析的目的是直接或間接地提高工作效率,在實際使用中充當智能化助手的角色,使工作人員在恰當的時間擁有恰當的信息,幫助他們在有限的時間內作出正確的決定。信息系統中積累的大量數據,其原始數據的價值很小,只有通過智能化分析方法抽取其中的精華,才能從數據中挖掘出其中的價值,為人類所利用。
二、智能數據分析分類
智能數據分析方法主要為兩種類型,一是數據抽象(DataAbstraction) ;二是數據挖掘(Date Mining)。
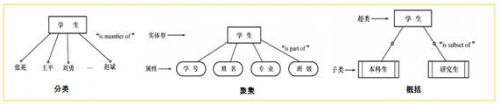
數據抽象:數據抽象結構是對現實世界的一種抽象從實際的人、物、事和概念中抽取所關心的共同特性,忽略非本質的細節把這些特性用各種概念精確地加以描述這些概念組成了某種模型。簡而言之就是在忽略類對象間存在差異的同時,展現了對用戶而言最重要的特性。三種常用的抽象:分類、聚集、概括。
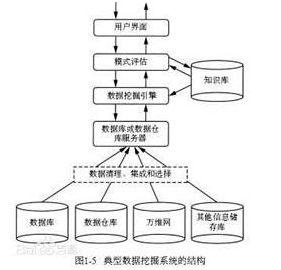
數據挖掘:一般是指從大量的數據中通過算法搜索隱藏于其中信息的過程。數據挖掘通常與計算機科學有關,并通過統計、在線分析處理、情報檢索、機器學習、專家系統(依靠過去的經驗法則)和模式識別等諸多方法來實現上述目標。智能數據分析方法包括分類、估計、預測、相關性分組或關聯規則,聚類,復雜數據類型挖掘等。
三、智能數據分析的常見方法
智能分析技術在數據的處理數據中具有非常重要的意義,主要包括以下幾類常見方法:
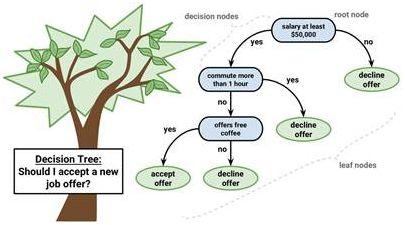
決策樹:在已知各種情況發生概率的基礎上, 通過構成決策樹來求取凈現值的期望值大于等于零的概率,評價項目風險, 判斷其可行性的決策分析方法,是直觀運用概率分析的一種圖解法,它是建立在信息論基礎之上對數據進行分類的一種方法。首先通過一批已知的訓練數據建立一棵決策樹, 然后采用建好的決策樹對數據進行預測。決策樹的建立過程是數據規則的生成過程,因此,這種方法實現了數據規則的可視化, 其輸出結果容易理解, 精確度較好, 效率較高, 缺點是難于處理關系復雜的數據。常用的方法有分類及回歸樹法、雙方自動交互探測法等。
關聯規則:是形如X→Y的蘊涵式,其中, X和Y分別稱為關聯規則的先導(antecedent或left-hand-side, LHS)和后繼(consequent或right-hand-side, RHS) 。其中,關聯規則XY,存在支持度和信任度。這種方法主要是用于事物數據庫中,通常帶有大量的數據,當今使用這種方法來削減搜索空間。
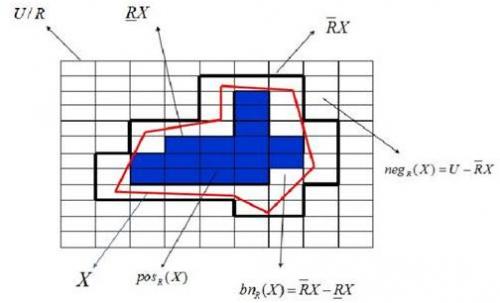
粗糙集:是繼概率論、模糊集、證據理論之后的又一個處理不確定性的數學工具。用粗糙集理論進行數據分析主要有以下優勢: 它無需提供對知識或數據的主觀評價, 僅根據觀測數據就能達到刪除冗余信息;非常適合并行計算、提供結果的直接解釋。如下圖,X稱為R的粗糙集。
模糊數學分析:用模糊(Fuzzy sets)數學理論來進行智能數據分析。現實世界中客觀事物之間通常具有某種不確定性。越復雜的系統其精確性越低,也就意味著模糊性越強。在數據分析過程中, 利用模糊集方法對實際問題進行模糊評判、模糊決策、模糊預測、模糊模式識別和模糊聚類分析, 這樣能夠取得更好更客觀的效果。
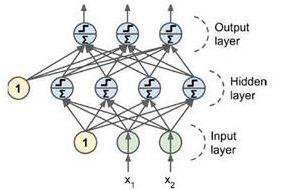
人工神經網絡:一種應用類似于大腦神經突觸聯接的結構進行信息處理的數學模型。該模型由大量的節點(或稱神經元)之間相互聯接構成。每個節點代表一種特定的輸出函數,稱為激勵函數(activationfunction)。每兩個節點間的連接都代表一個對于通過該連接信號的加權值, 稱之為權重,這相當于人工神經網絡的記憶。網絡的輸出則依網絡的連接方式, 權重值和激勵函數的不同而不同。而網絡自身通常都是對自然界某種算法或者函數的逼近, 也可能是對一種邏輯策略的表達。
混沌分型理論:混沌(Chaos)和分形(Fractal)理論是非線性科學中的兩個重要概念, 研究非線性系統內部的確定性與隨機性之間的關系。混沌描述的是非線性動力系統具有的一種不穩定且軌跡局限于有限區域但永不重復的運動, 分形解釋的是那些表面看上去雜亂無章、變幻莫測而實質上潛在有某種內在規律性的對象,因此,二者可以用來解釋自然界以及社會科學中存在的許多普遍現象。其理論方法可以作為智能認知研究、圖形圖像處理、自動控制以及經濟管理等諸多領域應用的基礎。
自然計算分析:這種數據分析方法根據不同生物層面的模擬與仿真, 通常可以分為以下三種不同類型的分析方法: 一是群體智能算法, 二是免疫算術方法,三是DNA算法。群體智能主要是對集體行為進行研究,免疫算法具有多樣性, 經典的主要有反向、克隆選擇等,DNA 算法主要使屬于隨機化搜索方法, 它可以進行全局尋優,在實際的運用中一般都能獲取優化的搜索空間,在此基礎上還能自動調整搜索方向,在整個過程中都不需要確定的規則,當前DNA算法普遍應用于多種行業中, 并取得了不錯的成效。





評論