機器學習到底需要多少數據?可能并不是越多越好

機器學習中最值得問的一個問題是,到底需要多少數據才可以得到一個較好的模型?從理論角度,有Probably approximately correct (PAC) learning theory來描述在何種情況下,可以得到一個近似正確的模型。但從實用角度看,PAC的使用范圍還是比較局限的。所以今天我們主要想討論一個問題:到底如何定義有效數據量。
本文引用地址:http://www.j9360.com/article/201803/377066.htm1. 數據的粒度(granularity)
數據的粒度可以理解為數據的細分程度,或者具體程度。舉個簡單例子,我們想預測股票的走勢,那么我們可以得到以下歷史數據:
每秒鐘的交易數據
每分鐘的交易數據
...
每年的交易數據
換成另一個場景,如果我們打算對一個句子進行截斷,“我今天真高興”,那么結果可以是:
我 | 今 | 天 | 真 | 高 | 興
我今 | 今天 | 天真 | 真高 | 高興
我今天 | 天真高 | 高興X
隨著細分程度的改變,那么數據量也有明顯的變化。數據的粒度越細,數據量越大。一般來說,我們追求盡量細分的數據,因為可以通過聚合(aggregation)來實現從具體數據到宏觀數據的還原,但反之則不可得。
但是不是數據越具體越好?不一定,過于具體的數據缺失了特征,有效的特征僅在某個特定的粒度才存在。打個比方,人是由原子、分子、細胞、組織、器官構成,但在分子層面我們不一定能分辨它是人,只有到達一定的粒度才可以。因此,數據收集的第一個重點是搞清楚,在什么粒度可以解決我們的問題,而不是盲目的收集一大堆數據,或者收集過于抽象的數據。
2. 數據量與特征量的比例
機器學習中對于數據的表達一般是 n*m的矩陣,n代表樣本的數量,一行(row)數據代表一個獨立數據。而m代表特征變量(attribute/feature/variable)的數量,一列(column)數據代表某個特征在所有樣本上的數值。比如下圖就代表了一個 4*2(n=4,m=2)的矩陣,即總共有4條數據,每個數據有2個特征。
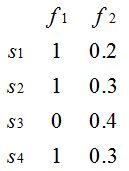
人們討論數據量,往往討論的是n,也就是有多少條數據。但這個是不準確的,因為更加適合的評估應該是n/m,也就是樣本量除以特征數,原因很簡單。如果你只有100條數據,但只有2個特征。如果用線性函數來擬合,相當于給你100個點來擬合到二次函數上,這個數據量一般來說是比較充裕的。但還是100個數據點,每個數據的特征數是200,那么很明顯你的數據是不夠的,過擬合的風險極高。
所以談論數據量,不能光說有多少條數據n,一定也要考慮數據的特征數m。
3. 特征間的相關性與有效性
前文所有的討論都建立在一個標準上,那就是我們選擇的數據是有效的。從兩個方向理解:
數據間的重復性低:
樣本間的重復性比較低,不會存在大量的重復樣本。一行數據復制100次還是1行數據,因此拿到數據后去重也是很有必要的。
特征間的重復性低:這個要回歸到線性代數上,假設你有3個特征,結果 X_3 = alpha X_1 + beta X_2 ,那么從某種意義上來看你并沒有3個獨立特征,即特征間的相關性比較高。對于表達能力比較弱的模型,我們甚至有時還會人為的手動制造一些這樣的變量,但如果你的數據量大量的變量都是相關的,那么要謹慎地認為你的數據量很大。舉個極端的例子,你有n個變量,結果 X_j = X_1 cdot j quad forall jin[1,2,...n] ,那么說到底你還是只有1個變量。
數據的有效性:此處的有效性指的是你的變量對于解決問題有幫助,而不是完全無關或者關聯性極低的數據。不要小看無關數據,幾乎無處不在。拿我常舉的例子來說:
圖1. 全球非商業性空間飛船發射數量與美國社會學博士畢業數量之間的關系[1]
4. 數據是否越多越好?
承接上一個部分,數據比模型更重要,數據重要性 >> 模型重要性。機器學習模型的表現高度依賴于數據量 [2],選擇對的模型只是其次,因為巧婦難為無米之炊。
但數據不是越多越好,隨機數據中也可能因為巧合而存在某種關聯。Freedman在1989年做過的模擬實驗 [3]中發現,即使數據全是由噪音構成,在適當的處理后,也能發現數據中顯著的相關性:a. 6個特征顯著 b. 對回歸的做F-test的p值遠小于0.05,即回歸存在統計學意義
以此為例,大量數據不代表一定有顯著的意義,即使相關性檢驗也不能證明這一點。一般來說,需要先確認數據的來源性,其次要確認顯著的特征是否正常,最后需要反復試驗來驗證。最重要的是,要依據人為經驗選取可能有關的數據,這建立在對問題的深入理解上。更多相關的討論可以參考 微調:你實踐中學到的最重要的機器學習經驗是什么?。
5. 數據量與模型選擇
一般來說,在大數據量小特征數時,簡單模型如邏輯回歸+正則即可。在小數據量多特征下,集成的樹模型(如隨機森林和xgboost)往往優于神經網絡。隨著數據量增大,兩者表現趨于接近,隨著數據量繼續上升,神經網絡的優勢會逐步體現。隨著數據量上升,對模型能力的要求增加而過擬合的風險降低,神經網絡的優勢終于有了用武之地而集成學習的優勢降低。我在微調:怎么理解決策樹、xgboost能處理缺失值?而有的模型(svm)對缺失值比較敏感呢? 曾經總結過一些根據數據量選擇模型的經驗:
數據量很小,用樸素貝葉斯、邏輯回歸或支持向量機
數據量適中或者較大,用樹模型,優先 xgboost和lightgbm
數據量較大,嘗試使用神經網絡
所以說到底,依然不存在定式,而依賴于經驗和理解,供大家參考。

評論