一種基于模糊模板匹配的車牌漢字識別方法

字符識別屬于模式識別的范疇,通常的字符識別方法可分為2類:基于字符結構(筆畫特征)的結構識別和基于字符統計特征的統計識別。結構模式識別方法的優點是可以識別復雜的模式,缺點是需要進行筆畫特征的提取,在輸入圖像質量不佳的情況下,這一點往往難以做到。在統計模式識別方法中,特征提取方便,識別速度與識別對象無關,但需要得到字符集的穩定特征,且在字符筆畫較多時要求的特征量非常大。二種識別方法各有優缺點。
人類的視覺感知系統是一個魯棒性很強的、能抵御實際中可能遇到的各種變形和噪聲干擾的文字識別系統。人們的認字過程實際上是對漢字整體形象的把握,是對漢字圖像全局的處理過程[1]。因而,漢字的整體信息在無筆順識別中起著無法替代的重要作用。
統計模式識別借助概率論的知識,判斷或決策對象的特征類別,使得決策的錯誤率達到最小。基于統計特征的識別方法先抽取識別對象的穩定特征,組成特征矢量,然后在字符集的特征空間中進行特征匹配。基于以上認識,在分析汽車牌照中漢字字符的特點后,采用了有別于結構分析的一種基于字符圖像特征統計的模式識別方法進行漢字識別。同時針對統計方法無法區分的相似漢字,提取其微結構信息進行特殊的校正識別。
1 特征統計匹配
統計決策論其要點是提取待識別模式的一組統計特征,然后按照一定準則所確定的決策函數進行分類判決[2]。漢字的統計模式識別是將字符點陣看作一個整體,從該整體上經過大量統計得到所用特征,用盡可能少的特征模式來描述盡可能多的信息。所采用的方法有:特征統計的方法、整體變換分析法[3]、幾何矩特征、筆劃密度特征、字符投影特征、外圍特征、微結構特征和特征點特征等。這些方法都具有各自的優缺點,應根據具體應用進行選取。主要方法有外圍面積特征匹配法和網格特征匹配法。外圍面積特征反映了字符的輪廓信息。外圍面積特征提取法,主要是從周圍形狀的心理學知識來獲得漢字信息的特征,即對文字周圍上下左右的形狀進行量化,從而構造特征向量。網格特征實際是結構模式識別和統計模式識別相結合的產物。字符圖像被均勻或非均勻地劃分為若干區域,稱之為“網格”。在每個網格內尋找各種特征,如目標面積比例、交叉點、筆劃端點的個數、細化后的筆劃長度和筆劃密度等。特征統計以網格為單位,即使個別點統計有誤差也不會造成大的影響,從而增強了特征的抗干擾性。因此這種方法得到日益廣泛的應用。在實際的車牌漢字識別中,當相同漢字的二值圖形變動較小時該方法較有效。具體應用:將尺寸為34×66象素的漢字二值圖均勻分成32個正方形的小區域(不考慮外邊框的1個象素),統計每個8×8的小區域內目標象素(白色)所占的面積比例,就得到了歸一化的32維特征矢量。統計多幅相同漢字的32維特征矢量,取均值作為該漢字的標準網格特征模板。識別時,計算待識別漢字的32維網格特征矢量與模板矢量之間的Euclid距離,求得最小距離值,其對應的漢字即為識別結果。在具體應用中,由于外部原因常常會出現字符模糊、字符傾斜的情況,而網格特征匹配方法對字符模糊和傾斜較敏感,因此魯棒性不是很強,不適合實際應用。
2 模板匹配
考慮到以上2種主要識別方法存在的弊端,決定選用模板匹配的算法進行字符的識別。實際研究中發現,二值化的圖形模板雖然直觀,但其匹配計算過程過于簡單直接,對傾斜、形變、殘損、模糊的待識別字符匹配誤差較大,因此魯棒性較差。而灰度模板由于色彩、光照等因素影響,難以找到普遍適用的模板形式實現直接的匹配計算。綜合以上二方面的問題,在引入統計模式識別思想的基礎上,提出了基于二值圖形變動分析的模糊模板匹配方案。
2.1 基于二值圖形變動分析的模糊模板匹配
在含有汽車牌照的圖像中,將漢字定位并提取出來以后,還要完成規格化、二值化等操作。即使是相同的漢字,由于車牌傾斜、模糊,特別是由于每次定位不可能完全精確一致等諸多因素的影響,導致在二值圖中字體的形狀、大小都會不同,字體位置也會發生不同程度的偏移。將這種二值圖形的不規則現象稱為圖形的變動。在漢字識別的分析過程中,希望對圖形變動的大小進行量化處理。因此,提出了求圖形整體變動量的統計方法,其優點是不需要參照標準圖形,可以進行客觀評價,并構造出用于匹配識別的模糊模板。
對每一個車牌的漢字字符,選取n幅質量較好的參考圖。將這n幅參考圖規格化為17×33的標準大小后進行二值化處理,得到標準參考圖fi(x,y)。因此每個車牌漢字字符都有n幅由0、1所組成的二值圖像。將這n幅二值圖像對齊后疊加,再進行歸一化。得到的模糊圖形F(x,y)。四個漢字的模糊圖形模板(不同方向的視覺效果)如圖1所示。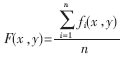
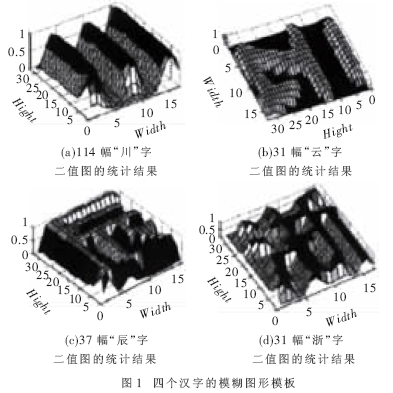
該模糊圖形上每一象素點實際上都對應著一個概率值,該概率值代表白色目標(漢字筆劃)在該點出現的可能性。例如在模糊模板中若某一點值為1,表明在所有參加統計的二值圖形上漢字筆劃都經過該點,其為白色目標象素的可能性是100%,為黑色背景象素的可能性是0;反之亦然。進行匹配識別時,對一幅切分后的待識別漢字灰度圖,將其規格化、二值化,然后計算每一象素點與模板的吻合程度,即每一象素點正確匹配的置信度con(x,y)。引入置信度的公式: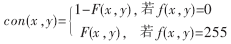
f(x,y)為得到的二值化后的待識別圖像,把所有點的置信度平均后得到總的置信度con作為判別依據。最大置信度con所對應的模板漢字作為匹配識別輸出的結果。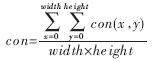
公式中的width和height分別是歸一化后標準圖像的長和寬。通過對實驗結果的分析發現,識別錯誤的圖像,往往嚴重變形、模糊,二值化效果差。
2.2 基于二值圖形變動分析的模糊模板匹配的改進算法
針對以上問題,提出了一種簡單的改進算法。將切分后不同大小的灰度字符圖像規格化為17×33的標準尺寸以后,將各象素點的灰度值線性變換到[0,1]區間,再與模糊圖形模板匹配,計算Euclid距離,其最小距離值對應的模板漢字作為匹配識別輸出的結果。該方法的優點是不用對灰度圖像作二值化處理,避免了由于二值化操作帶來的圖像信息損失。特別是對一些模糊圖像,若直接采用二值化效果較差,影響匹配準確度。因此使用該方法在一定程度上提高了識別正確率。
實驗中發現,對少數明暗程度變化大或對比度不強的模糊圖像,該方法也產生了少量識別錯誤。這是由于將待識別圖像的各點灰度值線性拉伸到[0,1]區間后,原始圖像明暗程度不同導致其平均值與對應模板的平均值并不一致,直接用Euclid距離進行匹配,帶來了計算誤差。因此引入了歸一化相關性度量公式: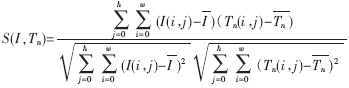
其中I(i,j)和Tn(i,j)分別是輸入的待識別的字符圖像和第n個模板,分別是輸入字符圖像所有灰度的均值和第n個模板的均值,w和h分別為圖像的長和寬,S(I,Tn)是匹配函數,其值在0~1之間,代表待識別圖像與模板圖像的匹配程度。使用該公式計算相關性,可以避免由于明暗和對比度變化導致圖像和模板的“能量”不一致而帶來的匹配誤差,進一步提高了匹配準確度。
3 試驗結果的進一步校正
模板匹配表現的主要是漢字的整體特征,但是有些漢字存在著一定程度上整體的相似性,因此必須對相似的字符進行進一步的校正才能提高識別的正確率。對相似漢字的區分,往往是尋找其特有的筆劃結構,這也是在統計模式識別中引入結構方法的必要之處。例如在車牌漢字識別中,“粵”字與其他省份漢字的最大區別是底部的鉤狀結構。為此對預處理后的17×33二值圖像的底部1/4部分作水平和垂直方向的投影,水平投影17個特征值(由左、右二邊分別投影得到),垂直投影33個特征值(由上、下二邊分別投影得到),形成50維的微結構投影特征矢量。“粵”字微結構特征及其統計41幅圖像后的微結構投影特征直方圖如圖2所示。經統計平均后作為區分相似漢字的依據。實際校正時,計算微結構特征的匹配距離。若小于預先設定的閾值,則直接返回該漢字作為識別結果。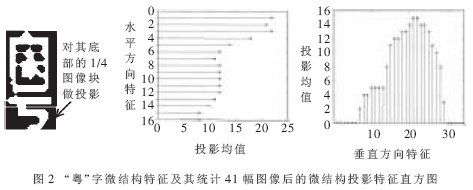
4 實驗流程及結果
對識別300幅切分后的質量較好的漢字灰度圖進行識別,實驗流程如圖3所示。實驗結果表明,外圍面積特征匹配法正確率達88%,網格特征匹配法86%,簡單模板匹配法91%,改進算法的正確率達到了93%。如果對識別結果進一步校正,正確率將提高到95%。若再進一步增加訓練集,完善模板,相信正確率還可以繼續提高。

評論