基于非特定人語音識別芯片的技術方案

0 引言
本文引用地址:http://www.j9360.com/article/201610/307596.htm隨著高新技術在軍事領域的廣泛運用,武器裝備逐步向高、精、尖方向發展。傳統的軍事訓練由于訓練時間長、訓練費用高、訓練空間窄,常常不能達到預期的訓練效果,已不能滿足現代軍事訓練的需要。為解決上述問題,模擬訓練應運而生。
為進一步提高訓練效果,本文利用智能語音交互芯片設計了某模擬訓練器的示教與回放系統。示教系統為操作人員生動的演示標準操作流程及相應的操作現象,極大地縮短了對操作人員的培訓時間,提高了培訓效果。回放系統通過記錄操作訓練過程中各操作人員的口令、聲音強度、動作、時間、操作現象等,待操作訓練結束后通過重演訓練過程,以便操作者及時糾正自己的問題。示教系統也可理解為對標準操作訓練過程的回放。該系統不需要虛擬現實技術的支持,在小型的嵌入式系統上就可以實現。
1 系統原理
該模擬訓練器由一臺測控計算機和多臺從設備組成。如圖1所示。在此僅對一臺從設備進行介紹,其硬件系統主要由測控計算機、Arduino mega2560 控制器、語音識別單元、聲強檢測單元、語音合成單元、面板控制單元、儀器面板等組成。面板控制單元較為復雜,包含多種控制電路,在模擬訓練中負責該從設備在Arduinomega2560 控制器的控制下完成整個訓練過程,在示教與回放系統中完成對剛才操作訓練操作現象的重演,其具體電路設計在此不做介紹。
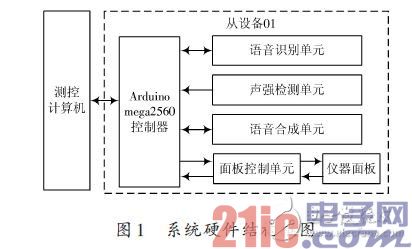
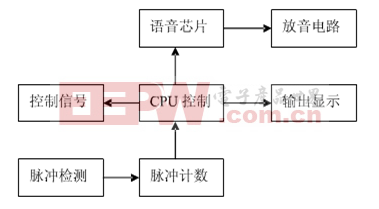
語音識別單元負責識別操作人員的操作口令;聲強檢測單元負責檢測聲強大小并以此作為判斷是哪臺從設備操作人員口令的依據;Arduino mega2560控制器負責監視儀器面板各元件的狀態來識別操作人員的動作,從而完成對操作訓練過程的記錄。各儀器的操作現象根據操作動作事先編制無需記錄。在操作回放過程中,測控計算機根據所記錄的數據,通過控制相應從設備的Arduino mega2560控制器重現所記錄的操作過程。
2 單元系統設計
2.1 語音識別單元設計
目前,語音識別技術的發展十分迅速,按照識別對象的類型可以分為特定人和非特定人語音識別。特定人是指識別對象為專門的人,非特定人是指識別對象是針對大多數用戶,一般需要采集多個人的語音進行錄音和訓練,經過學習,從而達到較高的識別率。
本文采用的LD3320語音識別芯片是一顆基于非特定人語音識別(Speaker?Independent Automatic SpeechRecognition,SI?ASR)技術的芯片。該芯片上集成了高精度的A/D 和D/A 接口,不再需要外接輔助的FLASH 和RAM,即可以實現語音識別、聲控、人機對話功能,提供了真正的單芯片語音識別解決方案。并且,識別的關鍵詞語列表是可以動態編輯的。其語音識別過程如圖2所示。
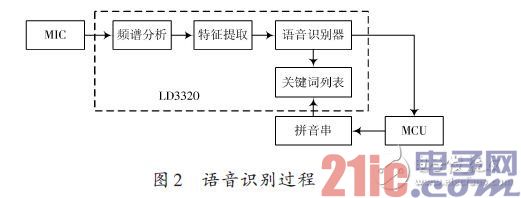
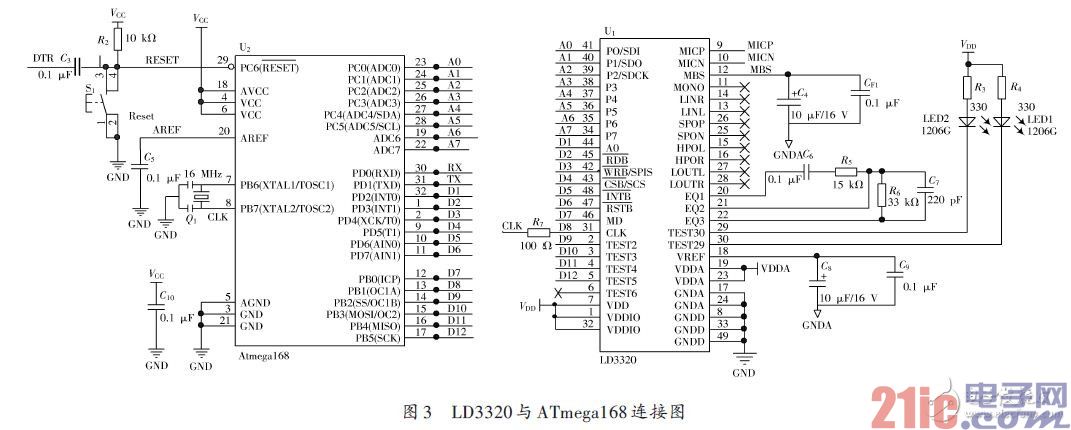
語音識別單元采用ATmega168 作為MCU,負責控制LD3320完成所有和語音識別相關的工作,并將識別結果通過串口上傳至Arduino mega2560 控制器。對LD3320芯片的各種操作,都必須通過寄存器的操作來完成,寄存器讀寫操作有2種方式(標準并行方式和串行SPI方式)。在此采用并行方式,將LD3320的數據端口與MCU的I/O口相連。其硬件連接圖如圖3所示。
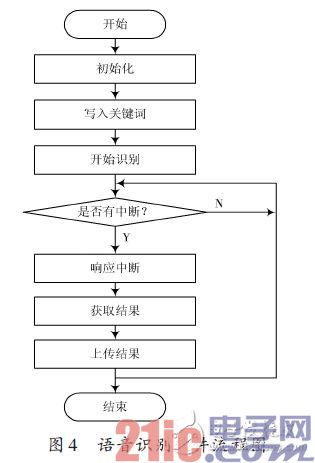
語音識別流程采用中斷方式工作,其工作流程分為初始化、寫入關鍵詞、開始識別和響應中斷等。MCU的程序采用ARDUINO IDE編寫[5],調試完成后通過串口進行燒錄,控制LD3320完成語音識別,并將識別結果上傳至Arduino mega2560控制器。其軟件流程如圖4所示。
2.2 聲強檢測單元設計
在進行語音識別時需要判斷是某一臺從設備操作人員的口令,為此設計聲強檢測單元電路,該電路僅需能夠判斷出相對聲強的大小,無需檢測聲級,對檢測精度要求較低。
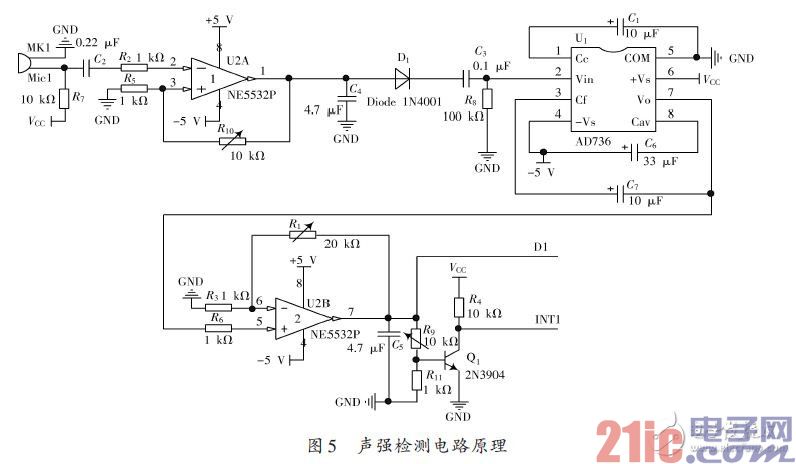
電容式MIC聲音傳感器將外部聲音信號轉換成電信號,經NE5532放大電路進行放大,將輸入的微弱音頻信號轉換為具有一定幅值的電壓信號,該電壓信號經AC/DC有效值轉換電路進行裝換后進行再次放大,最終由Arduino mega2560控制器的A/D進行采樣。圖5給出了聲強檢測單元的電路原理圖,其中D1 端接Arduinomega2560控制器的A/D,INT1端接Arduino mega2560控制器的外部中斷1.當外界聲音信號大于預設的閾值時,三極管導通INT1端由高電平變為低電平產生外部中斷,控制器響應中斷并進行A/D 采樣,采樣數據經均值濾波后保存,待測控計算機查詢時上傳該聲強數據。
2.3 語音合成單元設計
TTS(Text To Speech)文本轉語音技術是人機智能對話發展的趨勢。基于TTS技術的語音系統無需事先錄音就能夠隨時根據查詢條件查出并合成語音進行播報,從而大大減少了系統維護的工作量。利用此技術,通過MCU或者PC機就能控制語音芯片發音[4]。
本文采用SYN6658中文語音合成芯片進行語音合成。SYN6658 通過UART 接口或SPI接口通信方式,接收待合成的文本數據,實現文本到語音(或TTS語音)的轉換[6]。控制器和SYN6658 語音合成芯片之間通過UART接口連接,控制器通過串口通信向SYN6658語音合成芯片發送控制命令和文本,SYN6658語音合成芯片把接收到的文本合成為語音信號輸出,輸出的信號經LM386 功率放大器進行放大后連接到喇叭進行播放。
如圖6所示。
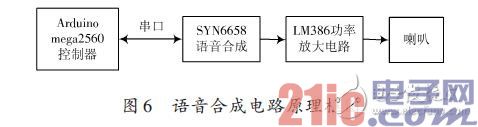
SYN6658語音合成電路采用芯片硬件數據手冊提供的典型應用電路進行設計[5],在此不做介紹,功率放大電路采用美國國家半導體生產的音頻功率放大器LM386進行放大。
在進行語音合成時首先進行初始化,包括發音人選擇、數字處理策略、語速調節、語調調節、音量調節等。
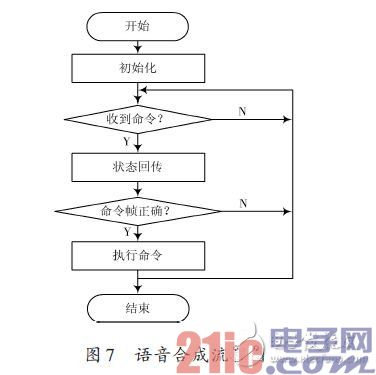
由于該系統要模擬多人發音,所以不同的從設備設置不同的發音人及語調與語速以便于區分。初始化后等待測控計算機的語音合成命令,待收到命令后芯片會向上位機發送1字節的狀態回傳,上位機可根據這個回傳來判斷芯片目前的工作狀態。語音合成流程圖如圖7所示。
3 系統軟件設計
示教與回放系統的軟件設計包括測控計算機的軟件設計和各從設備Arduino mega260控制器的軟件設計。
測控計算機是整個系統的控制核心,其軟件采用C#進行編寫,在示教與回放系統中主要是對操作數據的記錄以便根據所記錄的數據對操作過程進行精確回放,需要記錄的數據包括:各從設備操作人員的操作口令,操作動作,口令及動作時間,各操作對應的操作現象。為簡化記錄數據,事先編制好各事件代碼,記錄過程只記錄代碼,大大提高程序效率。建立結構體如下:

在操作訓練過程中測控計算機每隔50 ms 對下位機進行控制及輪詢,并記錄反饋數據,在數據記錄時以50 ms 為一個單位。采用定時器對時間進行控制。在回放過程中首先比對當前時間和所記錄的時間,當所記錄的時間與當前時間吻合時測控計算機控制下位機執行該事件,完成事件回放。
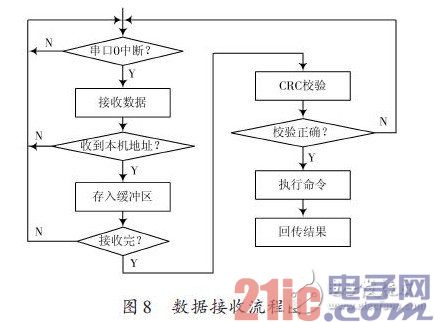
Arduino mega2560控制器負責接收測控計算機的控制指令并執行指令,讀取語音識別結果,對聲強數據采集和處理,控制語音合成單元進行語音合成等。Arduinomega2560 控制器采用串口中斷的方式進行命令接收。
只有正確接收到命令才會執行并回傳結果,若測控計算機在限定時間內未收到回傳結果則表明發生錯誤,測控計算機需重新發送。數據接收流程圖如圖8所示。
4 總結
本文利用智能語音芯片設計了某模擬訓練器的示教與回放系統,該系統不需要現在流行的虛擬現實技術的支持,僅在MCU 的控制下就可以運行。該系統也可以在小型的便攜式設備上實現,具有良好的應用前景。



評論