Linux 網絡文件系統的數據備份及恢復機制實現

網絡文件系統(NFS)協議是由 Sun MicroSystem 公司在 20 世紀 80 年代為了提供對共享文件的遠程訪問而設計和實現的,它采用了經典的客戶機/服務器模式提供服務。為了達到如同 NFS 協議通過使用 Sun 公司開發的遠在本機上使用本地文件系統一樣便捷的效果,NFS 通過使用遠程過程調用協議(RPC Protocol)來實現運行在一臺計算機上的程序來調用在另一臺遠程機器上運行的子程序。同時,為了解決不同平臺上的數據交互問題,它提供了外部數據表示(XDR)來解決這個問題。為了靈活地提供文件共享服務,該協議可以在 TCP 協議或者是 UDP 協議上運行,典型的情況是在 UDP 協議上運行。在此基礎上,NFS 在數據的傳送過程中需要 RPC 命令得到確認,而且在需要的時候會要重傳,這樣既可以通過 UDP 協議獲得較高的通信效率,也能通過 RPC 來獲得較高的通信可靠性。
由于 NFS 基于 C/S 模式提供服務,所以它的核心組件主要包括客戶機和服務器兩部分。圖 1 詳細說明了 NFS 的主要組件以及主要的配置文件。在服務器端,portmap、mountd、nfsd 三個監控程序將在后臺運行。portmap 監控程序用來注冊基于 RPC 的服務。當一個 RPC 的監控程序啟動的時候,它告訴 portmap 監控程序它在哪一個端口進行偵聽,并且它在進行什么樣的 RPC 服務。當一個客戶機向服務器提出一個 RPC 請求,那么它就會和 portmap 監控程序取得聯系以確定 RPC 消息應該發往的端口號。而 Mountd 監控程序的功能是來讀取服務器端的/etc/exportfs 文件并且創建一個將服務器的本地文件系統導出的主機和網絡列表,因而客戶機的掛接(mount)請求都被定位到 mountd 監控程序(daemon)。當驗證了服務器確實具有掛接所請求的文件系統的權限以后,mountd 為請求的掛接點返回一個文件句柄。而 nfsd 監控程序則被服務器用來處理客戶機端發送過來的請求。由于服務器需要同時處理多個客戶機的請求,所以在缺省情況下,操作系統將會自動啟動八個 nfsd 線程。當然,如果 NFS 服務器特別忙的時候,系統有可能根據實際情況啟動更多的線程。
圖 1 網絡文件系統簡圖
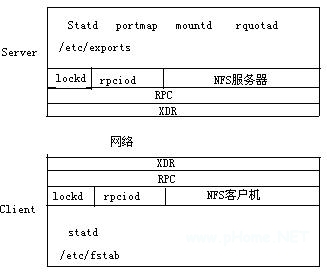
NFS 的客戶機與服務器之間通過 RPC 進行通信,通信過程如下所示:
用戶將 NFS 服務器的共享目錄掛載到本地文件系統中。
客戶訪問 NFS 目錄中的文件時,NFS 客戶端向 NFS 服務器端發送 RPC 請求。
NFS 服務端接收客戶端發來的 RPC 請求,并將這個請求傳遞給本地文件訪問程序,然后訪問服務器主機上的一個本地的磁盤文件。NFS 服務器可以同時接收多個 NFS 客戶端的請求,并對其進行并發控制。
NFS 客戶端向服務器主機發出一個 RPC 調用,然后等待服務器的應答。NFS 客戶端收到服務器的應答后,把結果信息展現給用戶或應用程序。
NFS 下的數據備份、恢復的主要功能
對數據進行備份與恢復是保證數據安全和業務連續性的非常成熟的做法。在 Linux 下的本地文件系統(例如 Ext2、Ext3 等)中,數據備份和恢復一般采用常規的辦法來進行操作,例如使用 Tar、Archive 等。而對于 NFS 來說,其數據備份需要采用量身定制的方法來進行。
為了保證數據在災難環境中的可用性和業務連續性,針對它的數據備份、恢復方案應具備如下重要功能:
通過對系統重要數據的快速備份,切實保證系統數據的安全;
可以根據指令完成備份系統的實時切入,保證服務不被中斷,保持系統持續運行的能力;
通過實時記錄所有文件的操作日志,系統管理員能夠在發生災難的情況下對日志進行分析和取證,從而發現入侵者的蛛絲馬跡。
NFS 多版本備份技術
為了保證服務器出現故障后能迅速恢復,要求系統數據能快速恢復到一個最近的正確狀態,所有這些都需要多版本技術的支持,通過同步記錄文件的在某些時刻的狀態,在整個系統范圍內建立起類似于數據庫系統的”檢查點”,以保證上述目標的實現。
對于多版本系統而言,需要較好地解決兩個方面的問題:性能和空間利用率。對于前者,最主要的是保證在生成版本的時候能夠快速完成,同時恢復時也具有較好的性能。此外,系統引入多版本造成的整體開銷也應該比較理想。對于第二點,主要考慮是節約磁盤空間,雖然隨著硬件技術的不斷發展,磁盤空間越來越大,性價比也越來越高,但是當版本較多而且文件數量較多、較大時,引入多版本增加的開銷也可能相當可觀,同時,較大的空間也意味著版本生成時可能需要更多的寫操作,這樣也必將影響總體性能。
為了保證引入多版本特性后文件系統仍具有較好的性能,以及保證較高的空間利用率,我們開發了一種高效的惰性版本生成算法。主要思想是:生成版本時不進行文件的復制,僅復制目錄結構,在新版本生成后到下一版本生成前,如果有文件需要修改,則第一次修改時對該文件進行復制,從而保證該文件狀態與對應的版本保持一致。
在一般情況下,目錄結構的數據量遠遠小于文件的數據量,因而這種方法可以大大降低版本生成時需要復制的數據量,因而具有較高的性能。同時,這種把單個文件版本生成的實際操作推后到非做不可的時候,并且任意文件在兩次版本之間最多生成一次版本,因此這種惰性策略可以使需要實際生成版本的文件數量達到最少,同時還可以把多個文件版本生成操作分散到具體的文件操作中,從而避免了集中的一次性版本生成方法可能造成的服務暫時停頓的問題。
版本生成后的結構如圖 2 所示。
圖 2 多版本生成示意圖
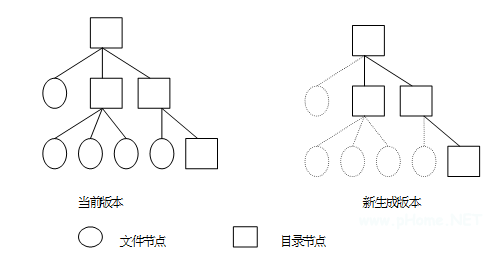
具體算法包括兩個部分,即版本生成算法和文件第一次修改處理算法,版本生成算法主要完成版本生成工作,主要過程如下:
找到需要形成版本的最高層目錄作為原目錄;
利用文件系統提供的函數,生成新的目錄節點,稱為新目錄;








評論