常用數據無損壓縮算法分析

當今,各種信息系統的數據量越來越大,如何更快、更多、更好地傳輸與存儲數據成為數據信息處理的首要問題,而數據壓縮技術則是解決這一問題的重要方法。事實上,從壓縮軟件WINRAR到熟知的MP3,數據壓縮技術早已應用于各個領域。
2 數據壓縮技術概述
本質上壓縮數據是因為數據自身具有冗余性。數據壓縮是利用各種算法將數據冗余壓縮到最小,并盡可能地減少失真,從而提高傳輸效率和節約存儲空間。
數據壓縮技術一般分為有損壓縮和無損壓縮。無損壓縮是指重構壓縮數據(還原,解壓縮),而重構數據與原來數據完全相同。該方法用于那些要求重構信號與原始信號完全一致的場合,如文本數據、程序和特殊應用場合的圖像數據(如指紋圖像、醫學圖像等)的壓縮。這類算法壓縮率較低,一般為1/2~1/5。典型的無損壓縮算法有:Shanno-Fano編碼、Huffman(哈夫曼)編碼、算術編碼、游程編碼、LZW編碼等。而有損壓縮是重構使用壓縮后的數據,其重構數據與原來數據有所不同,但不影響原始資料表達信息,而壓縮率則要大得多。有損壓縮廣泛應用于語音、圖像和視頻的數據壓縮。常用的有損壓縮算法有PCM(脈沖編碼調制)、預測編碼、變換編碼(離散余弦變換、小波變換等)、插值和外推(空域亞采樣、時域亞采樣、自適應)等。新一代的數據壓縮算法大多采用有損壓縮,例如矢量量化、子帶編碼、基于模型的壓縮、分形壓縮和小波壓縮等。
3 常用數據無損壓縮算法
3.1 游程編碼
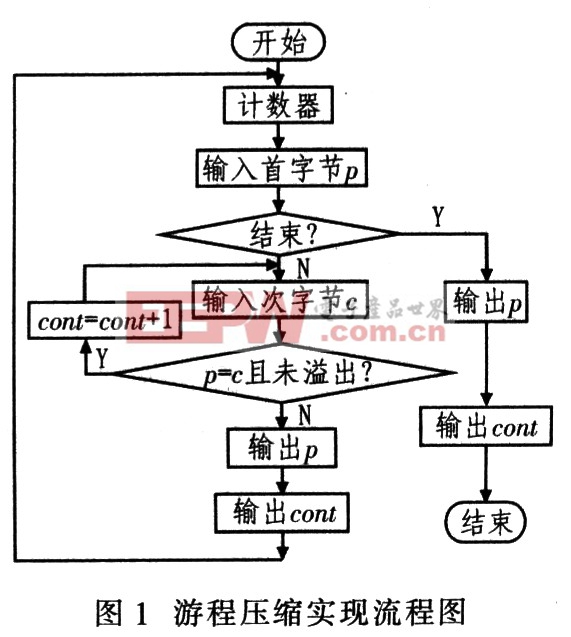
這種數據壓縮思想:如果數據項d在輸入流中連續出現n次,則以單個字符對nd來替換連續出現n次的數據項,這n個連續出現的數據項叫游程n,這種數據壓縮方法稱游程編碼(RLE),其實現流程如圖1所示。RLE算法具有實現簡單,壓縮還原速度快等優點,只需掃描一次原始數據即可完成數據壓縮。其缺點是呆板,適應性差,不同的文件格式的壓縮率波動大,平均壓縮率低。實踐表明,RLE能夠壓縮復雜度不高的原始點陣圖像。
3.2 基于字典編碼技術的LZW算法
LZW算法是LZ78的流行變形,由Terrv Welch在1984年開發。LZW算法首先將字母表中的所有字符初始化到字典,常用8位字符,在輸入任何數據前優先占用字典的前256項(0~255)。LZW編碼的原理:編碼器逐個輸入字符并累積一個字符串I。每輸入一個字符則串接在I后面,然后在字典中查找I;只要找到I,該過程繼續執行搜索。直到在某一點,添加下一個字符x導致搜索失敗,這意味著字符串I在字典中,而Ix(字符x串接在I后)卻不在。此時編碼器輸出指向字符串,的字典指針;并在下一個可用的字典詞條中存儲字符串Ix;把字符串I預置為x。其壓縮流程如圖2所示。
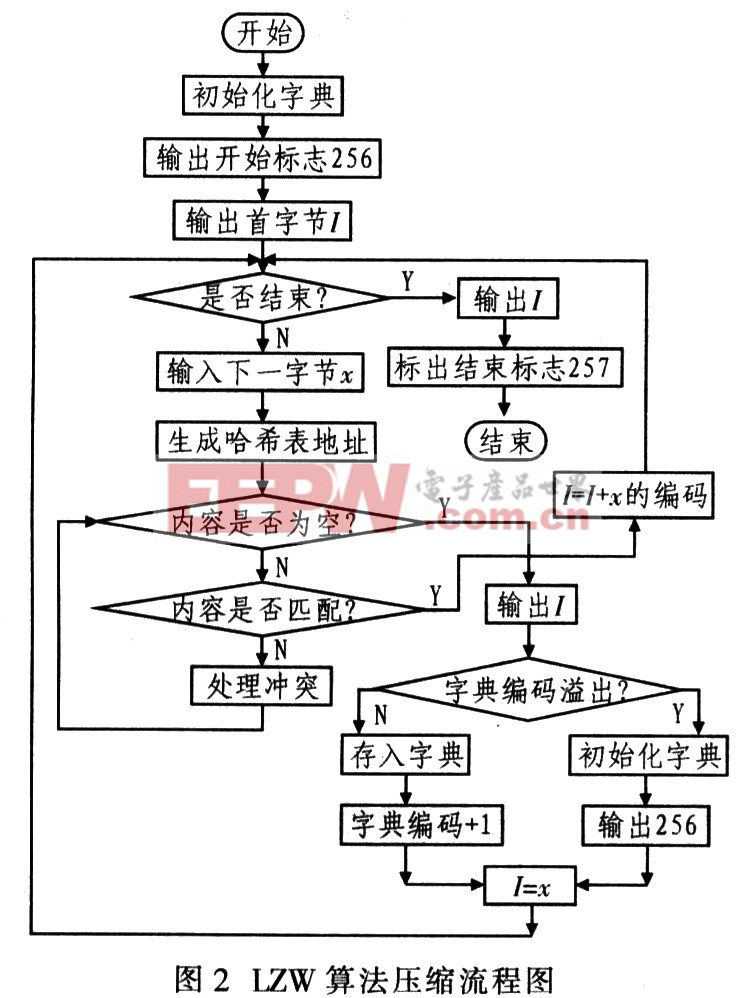
因為字典的前256項被占用,因此字典指針必須高于8位。由于LZW算法的字典中的字符串每次僅增加一個字符。因此,要獲得長字符串則需較長時間,這樣才能較好地壓縮.IZW編碼能夠適應輸入數據。
LZW算法與其他算法相比具有自適應的特點,即可以根據壓縮內容不同來建立不同字典,以減少冗余度,提高壓縮比;并且解壓時這個字典無需與壓縮代碼同時傳送,而是在解壓過程中逐步建立與壓縮時完全相同的字典,從而完整、準確地恢復被壓縮內容。因此,LZW算法是一種解碼速度與壓縮性能較好的壓縮算法。
實現LZW算法需要考慮以下幾點:
(1)字典建立(數據結構與字典大小) LZW字典的數據結構是一棵多叉樹。字典越大,代替的子串越多。但應用中字典容量則受一定限制,要權衡利弊選擇合適的字典。




評論