JPEG圖像硬件解碼低功耗設計

為了實現數據的實時處理和低功耗應用,本文提出了一種帶有時鐘管理機制的并行、全流水結構的JPEG解碼器實現方案。
1 JPEG解碼算法
JPEG(Joint Photographic Experts Group)是一種適用范圍很廣的靜態圖像數據壓縮標準。JPEG壓縮是一種有損壓縮,它利用了人的視覺系統特性,使用量化和無損壓縮編碼相結合的方式去掉視覺的冗余信息和數據本身的冗余信息。JPEG解碼器包括:霍夫曼(Huffman)解碼、反量化(IQ)和IDCT變換。在JPEG中,對于圖像的解碼是分塊進行的。整個圖像被劃分為若干個8×8的數據塊(MCU),每1個塊對應于原圖像的1個8×8的像素陣列。各行的編解碼順序從上到下,行內的編解碼順序從左到右[1]。
2 并行Huffman解碼器
Huffman編碼后代碼的長度不一致,如果解碼器用串行技術實現,由于其代碼長度不一致,解1個碼字所需的周期數也不一樣。對于實時系統,串行技術的效率比較低。另外,如果數據在傳播過程中被噪聲中斷,整組數據就變得沒有價值了。針對這兩方面的問題,本文提出如下的解決方案。如圖1所示為Huffman解碼的主要元件和算法流程。
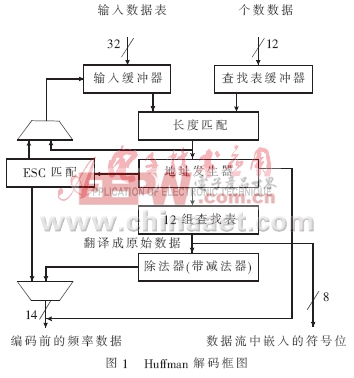
算法流程:從輸入端獲取32位的壓縮圖像數據,分析輸入的數據流,判斷出碼長,把輸入的數據移位,同時從輸入端補充新的數據。輸入的數據通過Huffman表翻譯成原始數據,提取出數據流中嵌入的符號位,經過一系列的除法、減法運算后得到編碼前的頻率數據,與之前得到的符號位合并后輸送到輸出緩存。
本文采用的算法靈活地利用了Huffman表的特點,消除了算法中的乘法運算,完成碼長的判斷只需要1個周期。把碼表的數據按照碼長分類從小到大排列,再把碼長相同的數據按照碼字的大小從小到大排列。每張表按照排列后的順序把碼字對應的解碼結果DR(Decoding Results)存入到ROM中。這樣既有利于查表,需要的ROM也是最小的,符合低功耗要求。查表的地址發生器由“長度匹配”模塊傳遞到的碼長得到1個基地址,碼長從輸入數據中截取連續的幾個與碼長相同位數的bit作為偏移地址,2個地址相加就是DR保存的地址[2]。
因關鍵bit出現的位置都是在碼字的最后幾位,因此根據碼長將輸入數據進行移位,使關鍵bit的最后1位出現在第n位,移位的結果只輸出第n位以前的幾個bit,這樣的電路只需要1個只受碼長控制的桶形移位寄存器。另外,再為每張表產生1個1串0加上1串1的地址修正串,有幾個關鍵bit就有幾個1,這部分電路邏輯簡單且占用的電路不多。用這個地址修正串和桶形移位寄存器的輸出做一個“與”邏輯運算,得到的就是正確的偏移地址。由于Huffman表需要的最長bit是9位,碼長最大為19位,所以本文設計了1個19位輸入、9位輸出的桶形移位寄存器。改進后的電路面積縮小到改進前的50%左右。
3 IDCT處理器
逆向離散余弦變換IDCT(Inverse Discrete Cosine Transform)電路的總體實現框圖和其中的2D IDCT框圖如圖2所示。DCT系數經過反量化和反掃描電路處理后輸入到IDCT的緩存器,由全局控制電路控制輸入到2D IDCT單元及將最終變換好的數據送到輸出緩存器中,發送Ready信號到運動補償單元,通知該單元可以讀出IDCT數據。2D IDCT單元進行2次1D IDCT運算,首先進行基于行的1D IDCT,然后將第1次IDCT的中間結果經轉置存儲器進行轉置處理和緩存,再進行基于列的1D IDCT變換,得到最終的IDCT變換結果[3]。






評論