一種基于密度的聚類的算法

2.2 改進的算法
DBSCAN算法在對類的劃分時采用的方法是:比較此數據點到各類中心的距離,若小于某閾值,則屬于此類。可見閾值的選擇直接影響類的劃分及類的數目。但是如圖1所產生的聚類模塊[3]所示,這種方法帶來的問題就是:距離近的不一定屬于同一類,在閾值半徑內的不一定屬于同一類。

針對此問題,本文提出一種改進的算法M-DBSCAN。首先實現在線聚類,可以動態調整聚類的數目;之后,通過將數據點到類的平均距離與類內平均距離以及新半徑與原半徑作比較進行雙重判決,確定數據點是否可以加入此類中,以實時調整閾值半徑,解決了類劃分錯誤的問題。
改進后整個算法描述如下:
(1)積累一小段時間內的數據,得到相似度矩陣
(2)給定閾值dthr,找出鄰域密度最大的數據點作為第一個初始類的中心c1,計算S中每行值大于dthr的個數,個數最多的行號即為第一個類的中心,將第一類中的數據點存放到矩陣S’(n×n+2)的第一行,每行中的第一個為類中心,計算類的平均半徑r,同時計算此類的平均距離d2,放到最后兩位。
(3)對尚未加入的數據點,計算某一個數據點到類c1中的所有點的平均距離d1,類的平均距離d2;
若d1d2,則判斷加入此數據后類的半徑是否變大;如果變小,將數據點加入此類,同時改變此類的平均半徑;否則尋找下一個聚類,計算同上。
如果不能加入到任何一個已有聚類,則創建一個新的類,將其存入S’中。


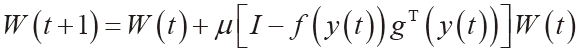
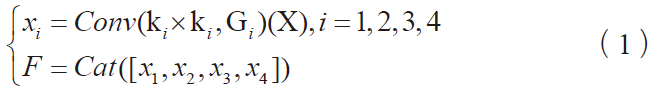




評論