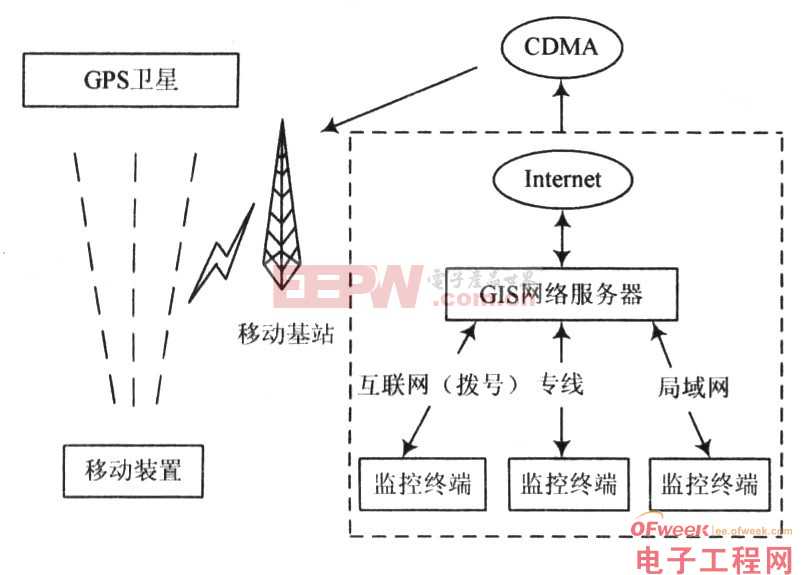
linux dma cache

說到DMA,就會想到Cache,兩者本身似乎是好不相關的事物。的確,假設DMA針對內存的目的地址和Cache緩存的對象沒有重疊區域,DMA和Cache之間就相安無事,但是,如果有重疊呢,經過DMA操作,Cache緩存對應的內存的數據已經被修改,而CPU本身并不知道,它仍然認為Cache中的數據仍然還是內存中的數據,以后訪問Cache映射的內存時,它仍然使用陳舊的Cache數據,這就會發生Cache與內存之間數據不一致性的錯誤。一旦出現這樣的情況,沒有處理好,驅動就將無法正常運行。那么怎樣解決呢?最簡單的方法是直接禁止DMA目標地址范圍內內存的Cache功能,當然這是犧牲性能的,但卻高可靠。不是嗎,所以這兩者之間究竟怎么平衡,還真不好解決。 其實啊,Cache不一致的情況在其他地方也是可能發生的,比如,對于帶MMU功能的arm處理器,在開啟MMU之前,需要設置Cache無效,TLB也是如此。
本文引用地址:http://www.j9360.com/article/149251.htm說了,那么多DMA理論的東西,剩下的來點Linux下DMA編程的東西,當然,這里也是點一下,具體怎么操作,我可要賣個關子到下節了。 在內存中用于與外設交互數據的一塊區域被稱作DMA緩沖區,在設備不支持scatter/gatherCSG,分散/聚集操作的情況下,DMA緩沖區必須是物理上聯系的。
對于ISA設備而言,其DMA操作只能在16MB以下的內存進行,因此,在使用kmalloc()和__get_free_pages()及其類似函數申請DMA緩沖區時應使用GFP_DMA標志,這樣能保證獲得的內存是具備DMA能力的。內核中定義了__get_free_pages()針對DMA的快捷方式__get_dma_pages(),它在申請標志中添加了GFP_DMA,如下所示:
#define __get_dma__pages(gfp_mask, order)
__get_free_pages((gfp_mask) | GFP_DMA, (order))
我不想使用order為參數的申請DMA內存,感覺就是怪怪的,那咋辦?
那?這樣吧,你就用另外一個函數dma_mem_alloc()源代碼如下:
/* dma_mem_alloc()返回值為虛擬地址 */
static unsigned long dma_mem_alloc(int size)
{
int order = get_order(size);//大小->指數
return __get_dma_pages(GFP_KERNEL, order);
}
上節我們說到了dma_mem_alloc()函數,需要說明的是DMA的硬件使用總線地址而非物理地址,總線地址是從設備角度上看到的內存地址,物理地址是從CPU角度上看到的未經轉換的內存地址(經過轉換的那叫虛擬地址)。在PC上,對于ISA和PCI而言,總線即為物理地址,但并非每個平臺都是如此。由于有時候接口總線是通過橋接電路被連接,橋接電路會將IO地址映射為不同的物理地址。例如,在PRep(PowerPC Reference Platform)系統中,物理地址0在設備端看起來是0X80000000,而0通常又被映射為虛擬地址0xC0000000,所以同一地址就具備了三重身份:物理地址0,總線地址0x80000000及虛擬地址0xC0000000,還有一些系統提供了頁面映射機制,它能將任意的頁面映射為連續的外設總線地址。內核提供了如下函數用于進行簡單的虛擬地址/總線地址轉換:
unsigned long virt_to_bus(volatile void *address);
void *bus_to_virt(unsigned long address);
在使用IOMMU或反彈緩沖區的情況下,上述函數一般不會正常工作。而且,這兩個函數并不建議使用。
需要說明的是設備不一定能在所有的內存地址上執行DMA操作,在這種情況下應該通過下列函數執行DMA地址掩碼:
int dma_set_mask(struct device *dev, u64 mask);
比如,對于只能在24位地址上執行DMA操作的設備而言,就應該調用dma_set_mask(dev, 0xffffffff)。DMA映射包括兩個方面的工作:分配一片DMA緩沖區;為這片緩沖區產生設備可訪問的地址。結合前面所講的,DMA映射必須考慮Cache一致性問題。內核中提供了一下函數用于分配一個DMA一致性的內存區域:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);
這個函數的返回值為申請到的DMA緩沖區的虛擬地址。此外,該函數還通過參數handle返回DMA緩沖區的總線地址。與之對應的釋放函數為:
void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle);
以下函數用于分配一個寫合并(writecombinbing)的DMA緩沖區:
void *dma_alloc_writecombine(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);
與之對應的是釋放函數:dma_free_writecombine(),它其實就是dma_free_conherent,只不過是用了#define重命名而已。
此外,Linux內核還提供了PCI設備申請DMA緩沖區的函數pci_alloc_consistent(),原型為:
void *pci_alloc_consistent(struct pci_dev *dev, size_t size, dma_addr_t *dma_addrp); 對應的釋放函數為:
void pci_free_consistent(struct pci_dev *pdev, size_t size, void *cpu_addr, dma_addr_t dma_addr);
相對于一致性DMA映射而言,流式DMA映射的接口較為復雜。對于單個已經分配的緩沖區而言,使用dma_map_single()可實現流式DMA映射:
dma_addr_t dma_map_single(struct device *dev, void *buffer, size_t size, enum dma_data_direction direction); 如果映射成功,返回的是總線地址,否則返回NULL.最后一個參數DMA的方向,可能取DMA_TO_DEVICE, DMA_FORM_DEVICE, DMA_BIDIRECTIONAL和DMA_NONE;
與之對應的反函數是:
void dma_unmap_single(struct device *dev,dma_addr_t *dma_addrp,size_t size,enum dma_data_direction direction);
通常情況下,設備驅動不應該訪問unmap()的流式DMA緩沖區,如果你說我就愿意這么做,我又說寫什么呢,選擇了權利,就選擇了責任,對吧。這時可先使用如下函數獲得DMA緩沖區的擁有權:
void dma_sync_single_for_cpu(struct device *dev,dma_handle_t bus_addr, size_t size, enum dma_data_direction direction);
在驅動訪問完DMA緩沖區后,應該將其所有權還給設備,通過下面的函數:
linux操作系統文章專題:linux操作系統詳解(linux不再難懂)







評論