Meta研究員破解大模型逆轉詛咒,推出《語言模型物理學》

就拿大語言模型的典型代表 GPT-4 來說,即便時至今日,它依然會對一些在人類看來很簡單的問題,給出錯誤的回答(如下圖所示的兩個案例)。
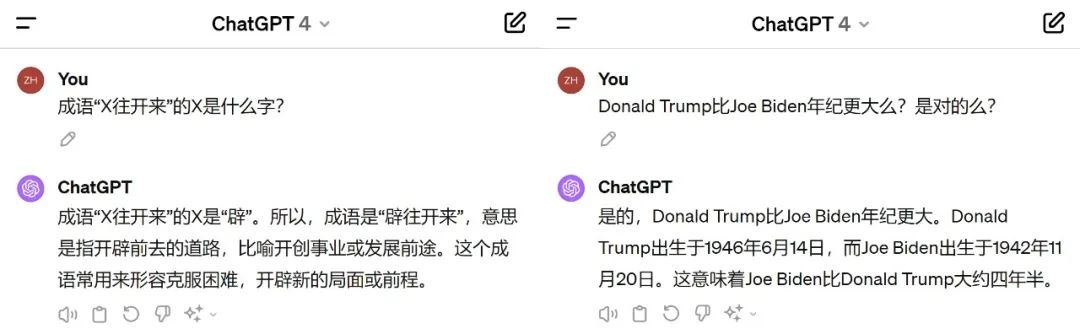 圖丨案例截圖(來源:朱澤園)
圖丨案例截圖(來源:朱澤園)那么,這到底是 GPT-4 本身的問題,還是它的訓練數據不足,亦或是它的數學能力太弱?其他模型會有這個問題嗎?
對于追求嚴謹的科學家來說,有必要思考這一系列問題的原因,并嘗試發現其背后存在的普適性定律。
6 個月前,來自 Meta 旗下的人工智能基礎研究實驗室(FAIR Labs)的朱澤園和合作者 MBZUAI 的李遠志教授,在研究大語言模型是“如何學習知識”的過程中,發現了一些意想不到的復雜情況。
譬如:有些知識,模型可以記住,但說不出來;有些知識,模型可以說出來,但是無法推演。
有些具備順序性的知識,比如成語“繼往開來”這四個字,始終是按順序出現的,所以不管大語言模型有多大以及訓練了多久,它都只能記住正序,而無法記住逆序知識。這種涉及到“知識的順序性”的現象,被學術界稱為“逆轉詛咒”。
 圖丨逆轉詛咒的案例:如果一個事實大多只在一個方向上出現,例如詩歌的上下句,那么即使是最有能力的大語言模型也無法反向回憶起這個事實。在該案例中,兩個模型顯然都知道這些歌詞的順序(左),但卻無法反向生成(右)(來源:arXiv [3])
圖丨逆轉詛咒的案例:如果一個事實大多只在一個方向上出現,例如詩歌的上下句,那么即使是最有能力的大語言模型也無法反向回憶起這個事實。在該案例中,兩個模型顯然都知道這些歌詞的順序(左),但卻無法反向生成(右)(來源:arXiv [3])為了克服這一難題,近日,FAIR Labs 實驗室提出了一種替代訓練方案名為“逆轉訓練”,大致思路是對所有的數據,都正向和“逆向”同時訓練兩次,然后通過尋找最可靠的“逆向”訓練方法,來效地解決逆轉詛咒問題。
近日,相關論文以《逆轉訓練攻克逆轉詛咒》(Reverse Training to Nurse the Reversal Curse)為題在預印本平臺 arXiv 上發表[1]。
作者包括 FAIR Labs 研究工程師奧爾加·戈洛夫涅娃(Olga Golovneva)、研究科學家朱澤園(Zeyuan Allen-Zhu)、研究科學家杰森·韋斯頓(Jason Weston)和研究科學家桑巴亞爾·蘇赫巴托爾(Sainbayar Sukhbaatar)。
 圖丨相關論文(來源:arXiv)
圖丨相關論文(來源:arXiv) 提出逆轉訓練方案,攻克大語言模型的逆轉詛咒難題
提出逆轉訓練方案,攻克大語言模型的逆轉詛咒難題其實,在探究大模型針對簡單的問題卻給出錯誤回答背后的原因時,朱澤園認為,過度追求大語言模型在基準數據集上的表現,也可能讓人類和通用人工智能漸行漸遠。
例如,最近發表在 Nature 上的 AlphaGeometry[2],是 DeepMind 開發的一個 AI 系統,能夠解決國際數學奧林匹克競賽 30 道平面幾何題中的 25 道。
但它的主算法卻是一個沒有 AI 參與的暴力搜索,搜索的步驟從數百條由人工挑選的引理中選擇。
有沒有一種可能是,DeepMind 人工挑選了上百條為 30 道國際數學奧林匹克競賽題量身定做的引理呢?
“我們對此表示質疑(僅代表本團隊,并非 Meta 官方立場)。但從科學的角度來看,我們應該盡量避免人工干預,以防‘有多少人工,就有多少智能’。” 朱澤園表示。
 圖丨朱澤園(來源:朱澤園)
圖丨朱澤園(來源:朱澤園)基于類似以上的擔憂,朱澤園提出了“語言模型物理學”這一新概念。
此概念主張,在物理學的啟發下化繁為簡,將“智能”分拆成多個維度,包括語法、知識、推理、解題等,并給每個維度創建全新的合成數據,搭建理想化的大語言模型訓練和測試環境,以探索模型所具備的普適性定律。類似在真空中研究牛頓定律,或是理想環境下研究氣體方程。
需要說明的是,研究人員并不應該局限于類似 GPT-4 這樣的個別模型,而是應該總結出在理想的數據集下,任何模型所展現出的普適性質。
“對于人工智能領域來說,通過在理想環境中去偽存真,我們可以排除數據作弊、人工挑選等因素,真正找出大語言模型的普適定律,并提出增強性能的方案。”朱澤園表示。
據了解,《語言模型物理學》項目的第一部分專注于語法研究,第二部分側重于推理研究,第三部分則聚焦于知識研究,其他更多部分的研究也在積極推進中,并在 Meta 內部立項,得到 FAIR 研究院的海量算力支持。
“不過因為發現過多,僅是其中第三部分‘知識研究’就拆成了至少三篇論文 Part 3.1、3.2、3.3,每篇都有幾個甚至十幾個結論,均已在 arXiv 上發表。”朱澤園說。
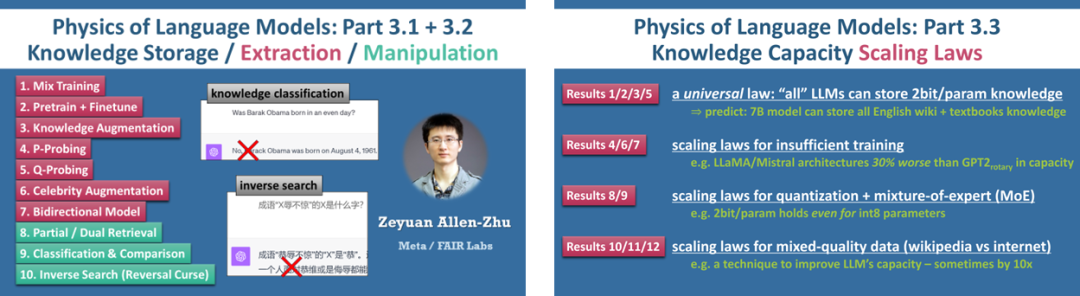
對于發表在 Part 3.2 論文中的“知識的順序性”這一現象來說,朱澤園和李遠志最早是在理想環境中觀察到它,而后又在市面上可見的預訓練模型,如 GPT-4 和 LLaMA-2 中,驗證了它的存在。
那么用“理想環境”而不是現實模型來做研究,有什么好處呢?
譬如這個課題里,在理想環境中我們可以固定知識的順序,也不用擔心測試數據的污染。
假如我們永遠都說“某某人,在 XXXX 年 X 月 XX 日出生”,以保證數據集中的知識都是人名在生日之前;然后,再提取出該數據集中一半的人員信息,訓練模型的逆向知識提取能力,比如“在 XXXX 年 X 月 XX 日出生的人,叫什么名字”。
我們就會發現,不管模型多大、訓練多久,它都只能對這一半的人完成逆向知識提取(正確率 100%,因為這一半人在訓練集里),而無法推演(generalize)到剩下一半的人(正確率 0%)。
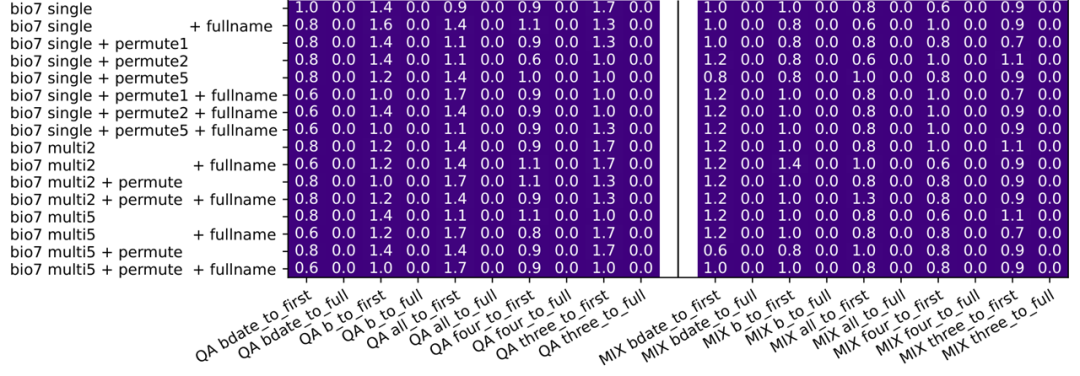 圖 | 在理想環境下,所有逆向知識提取的正確率都幾乎是 0(來源:arxiv[3])
圖 | 在理想環境下,所有逆向知識提取的正確率都幾乎是 0(來源:arxiv[3])換言之,理想環境下,不僅可以將測試集和訓練集完全分開,也能讓數據量無限增大,甚至還可以把模型打開,觀察出“為什么”知識無法逆向提取,并得到提取知識的充分必要條件。
更重要的是,理想環境下的研究,可以推廣到包括 GPT-4 在內的現實模型上,也能觀察到“逆轉詛咒”。
比如,除了如上所說的成語逆轉,還可以向大語言模型詢問“西出陽關無故人”的上一句話,或是給出百科上名人的出生年月日/工作單位/城市,來反問大語言模型這個人名是誰。
“大量的測試告訴我們,現實模型也無法很好地回答這樣的逆序知識類問題。”朱澤園說。
不過,需要指出的是,在現實模型上很難確定造成這些錯誤回答的原因,究竟是模型訓練得不夠久,還是數據不夠多。
即便現實模型答對了,會不會它的訓練數據中看到了原題(也就是數據污染)。綜上,在現實模型上直接研究,很難得到令人信服的、科學的結論。
“這就是為什么我們要做《語言模型物理學》的原因,即希望探索出一種全新的研究 AI 模型的思路。”朱澤園表示。
發現問題是一方面,要想解決“逆轉詛咒”,就是一個新的延伸課題了。為此,朱澤園和 FAIR Labs 實驗室的“推理記憶”課題組聯手,基于理想環境中的發現,給出現實生活中的一個解決方案——隨機拆詞反轉訓練。
主要是把每 1-25 個連續 token(對應約 1-15 個英語單詞)隨機拆成一組,在保持每組順序不變的前提下,將整個文章進行反轉。
同時使用正向的原文,和反轉后的文字對語言模型進行訓練。如果同一數據會多次進行反轉訓練,則可以每次用不同的隨機方法拆詞,這在無形之中增加了數據的多樣性,從而增強大模型對知識的存取效率。
從另一方面來看,隨機拆詞并翻轉也模擬了人類速讀。也就是說,當我們快速閱讀一段文字的時候,眼睛也在進行隨機拆解,甚至也會無序地閱讀。包括在學習重要知識時,還會前后翻書和反復閱讀。
研究人員將上述方法稱為“逆轉訓練”,并且在 LLaMA-2 模型上做了真實數據的測試。

同時,他們還得到了一個重要的發現:如果正反向都進行訓練,既不會影響正向的訓練結果,又不會讓傳統的基準數據集得分降低。
對于《語言模型物理學》系列作品給應用領域帶來的影響,朱澤園認為會是非常全面的。作為該系列作品的一個衍生成果,《逆轉訓練攻克逆轉詛咒》很可能在幫助解決大語言模型的諸多問題之一的同時,在所有公司的所有應用場景中得到應用。
“當然,一切的理論研究走到實際落地都有一個過程。我歡迎所有的研究人員參考我們論文給出的理論指導建議,在實際應用中找到增益。”朱澤園說。
另外,值得一提的是,2024 年 7 月,朱澤園將在 ICML 2024 上,受邀開展《語言模型物理學》系列講壇(tutorial)課程。
 致力于挑戰人工智能的每個維度,希望探索出大語言模型的普適性物理定律
致力于挑戰人工智能的每個維度,希望探索出大語言模型的普適性物理定律據了解,朱澤園本科就讀于清華大學物理系,博士畢業于美國麻省理工計算機系,是圖靈獎得主希爾維奧·米卡利(Silvio Micali)教授的弟子,后在美國普林斯頓大學和從事博士后研究,師從剛剛獲得圖靈獎的艾維·維格森(Avi Wigderson)教授。
他曾是國際信息學奧林匹克競賽兩屆金牌、國際大學生程序設計競賽全球總決賽金牌的獲得者,也在谷歌全球編程挑戰賽(Google Code Jam)中獲得世界第二的成績。
在 2022 年加入 FAIR Labs 之前,朱澤園曾在微軟研究院總部任職。
“加入 FAIR Labs 以后,我被給予了 100% 的科研自由,可以獨立發起項目,選擇我認為最重要的人工智能課題進行長期研究。《語言模型物理學》項目,就是我所負責的長期項目。”朱澤園介紹說。
如上所說,《逆轉訓練攻克逆轉詛咒》,是該項目的一個衍生課題。
不過,在最早參與該課題時,朱澤園并不十分“積極”。這主要是因為他考慮到精力有限,所以對參與科研課題一貫持謹慎態度。
“當這一課題負責人蘇赫巴托爾聯系我時,我從理論的角度出發,告訴他已經在理想環境下證明了數據反向訓練有效。所以,我認為逆轉訓練這個方法太過簡單,只需要多做點大規模的實驗而已。”他說。
但蘇赫巴托爾反問道:“那你當初為什么要發表 LoRA 呢?”
這個問題促使朱澤園進行了長時間的思考和反省,并最終做出了改變想法的決定。
其中,LoRA 是朱澤園在微軟研究院供職時參與開發的一個簡單有效的微調工具。當時他也曾認為該工具過于簡單,但如今后者已經成為行業內最常用的微調算法,業內幾乎無人不曉。
《逆轉訓練攻克逆轉詛咒》課題開始進行之后,朱澤園和合作者發現不同的逆轉訓練策略在效果上存在差異,與他們最初的預期不同。對此,他們也在論文中進行了詳細的比較。
“總的來說,如果一個算法簡易且有用,還不需要復雜的數學公式,這不正是我們人類最希望獲得的嗎?”朱澤園表示。
另外,在目前研究的基礎上,他告訴我們,《語言模型物理學》項目也制定了后續計劃,包括 2 個月內可以發布的項目第二部分“語言模型推理研究”的兩篇論文,會在理想環境下研究并提高 AI 模型在小學數學題上的推理能力等。
朱澤園說:“我們有一個很遠大的目標,那就是在理想的環境里去偽存真,挑戰人工智能的每一個維度,總結出大語言模型的普適物理定律。”
與此同時,他也認為,致力于研究理想環境下的大語言模型的《語言模型物理學》項目,與大部分科研都不相同。
“在我眼中,這仿佛是一個新的學科和一個新的研究問題的方式,非常刺激。因此,我幾乎停下了手上一切科研方向,全身心地撲向其中。”他表示。
即便在研究過程中受到諸多批評和質疑,包括測得的數據是否過于理想化、可能太過局限,以及和實際有差異等,但他對此卻依然毫不擔心。
他始終奉行堅持日心說的意大利科學家喬爾丹諾·布魯諾(Giordano Bruno)曾經說過的這句話,“真理不會因為大多數人相信或不相信而改變”。
排版:劉雅坤
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

