比GPT-4快18倍,世界最快大模型Groq登場!每秒500 token破紀錄,自研LPU是英偉達GPU 10倍


編輯:桃子 好困
一覺醒來,每秒能輸出500個token的Groq模型刷屏全網。堪稱是「世界上速度最快的LLM」!
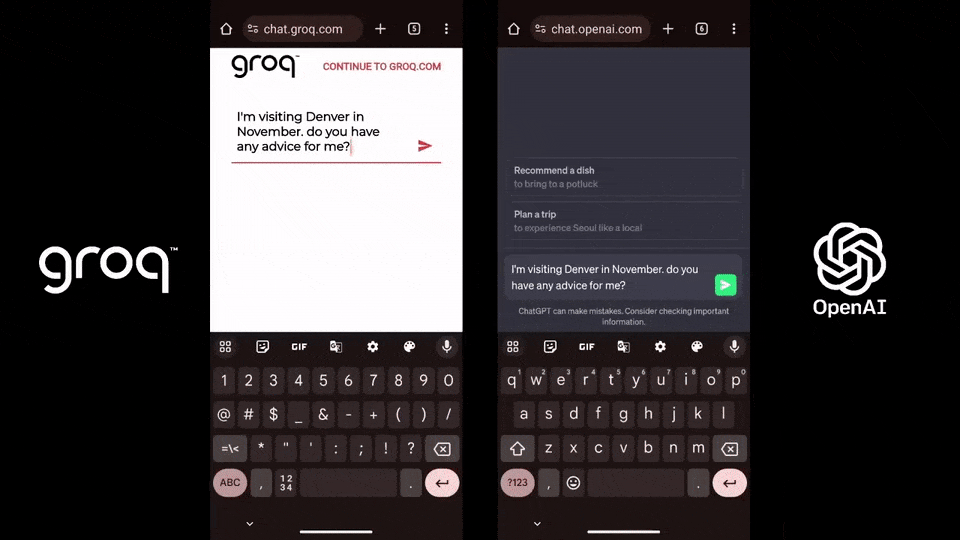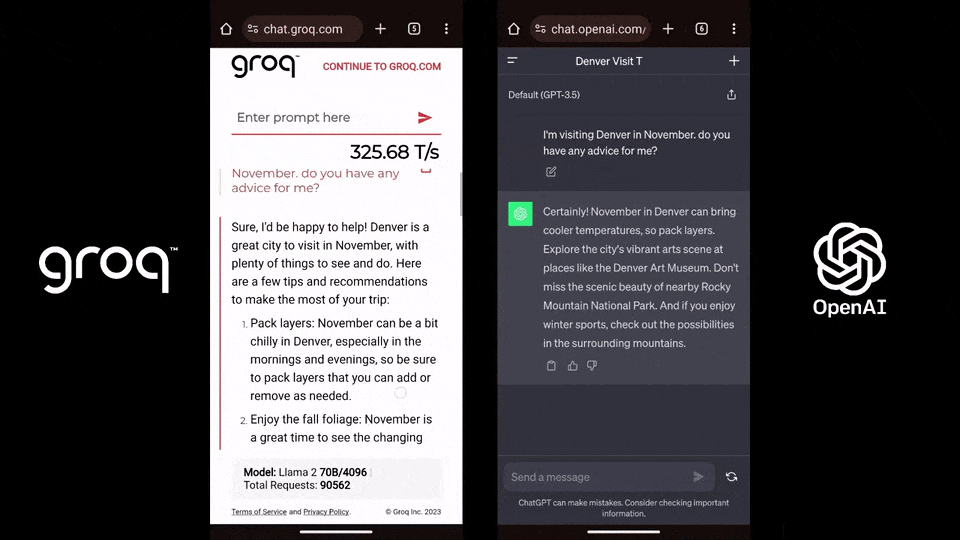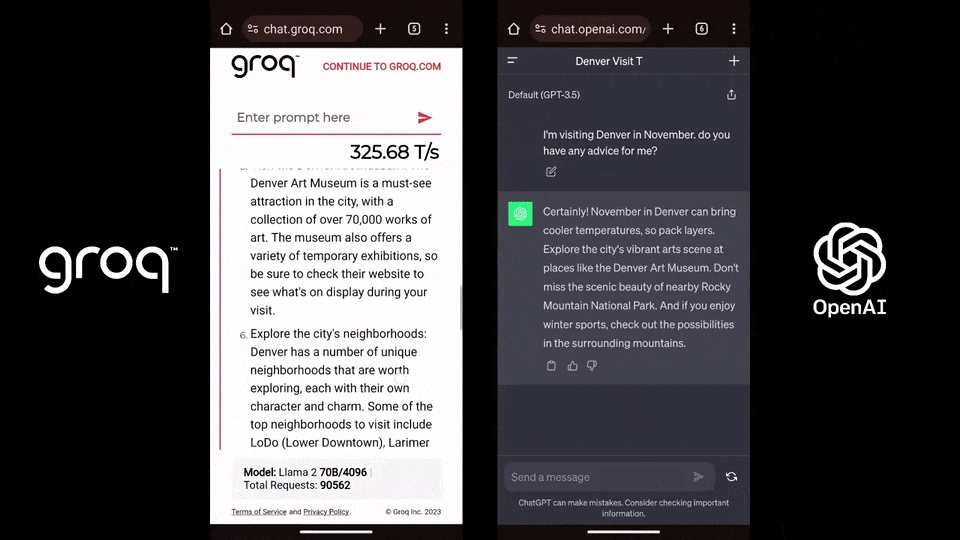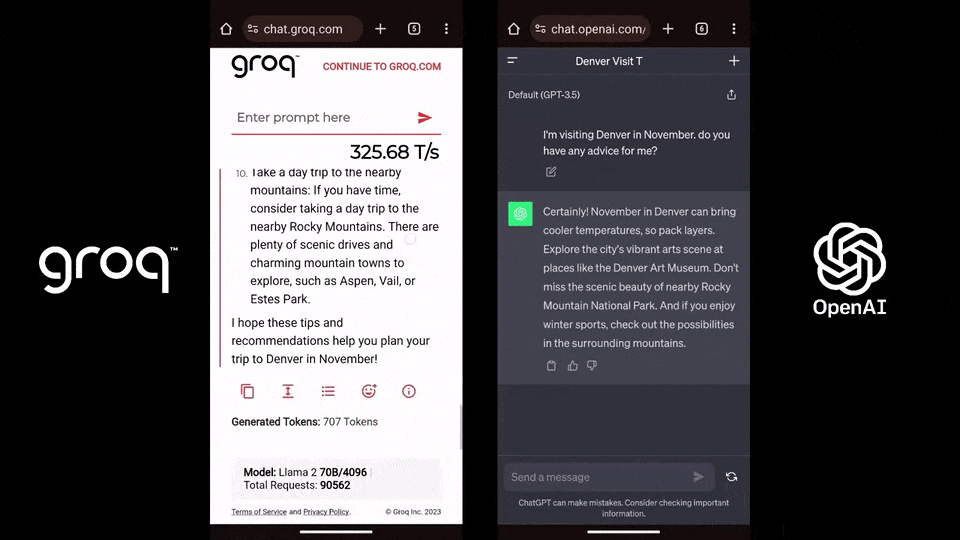 相比之下,ChatGPT-3.5每秒生成速度僅為40個token。有網友將其與GPT-4、Gemini對標,看看它們完成一個簡單代碼調試問題所需的時間。沒想到,Groq完全碾壓兩者,在輸出速度上比Gemini快10倍,比GPT-4快18倍。(不過就答案質量來說,Gemini更好。)
相比之下,ChatGPT-3.5每秒生成速度僅為40個token。有網友將其與GPT-4、Gemini對標,看看它們完成一個簡單代碼調試問題所需的時間。沒想到,Groq完全碾壓兩者,在輸出速度上比Gemini快10倍,比GPT-4快18倍。(不過就答案質量來說,Gemini更好。) ,時長01:23

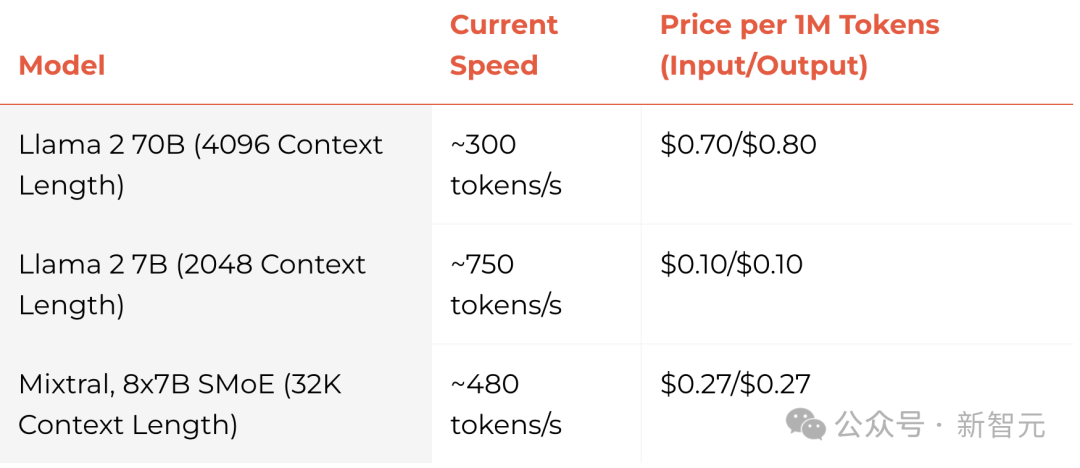 目前,他們還提供100萬token的免費試用。Groq突然爆火,背后最大的功臣不是GPU,而是自研的LPU——語言處理單元。單卡僅有230MB內存,2萬美元一張。在LLM任務上,LPU比英偉達的GPU性能快10倍。
目前,他們還提供100萬token的免費試用。Groq突然爆火,背后最大的功臣不是GPU,而是自研的LPU——語言處理單元。單卡僅有230MB內存,2萬美元一張。在LLM任務上,LPU比英偉達的GPU性能快10倍。 在前段時間的基準測試中,Groq LPU推理引擎上運行的Llama 2 70B直接刷榜,而且比頂級云提供商快18倍的LLM推理性能。
在前段時間的基準測試中,Groq LPU推理引擎上運行的Llama 2 70B直接刷榜,而且比頂級云提供商快18倍的LLM推理性能。
網友大波演示
Groq火箭般的生成速度,讓許多人為之震驚。網友們紛紛放出的自己做的demo。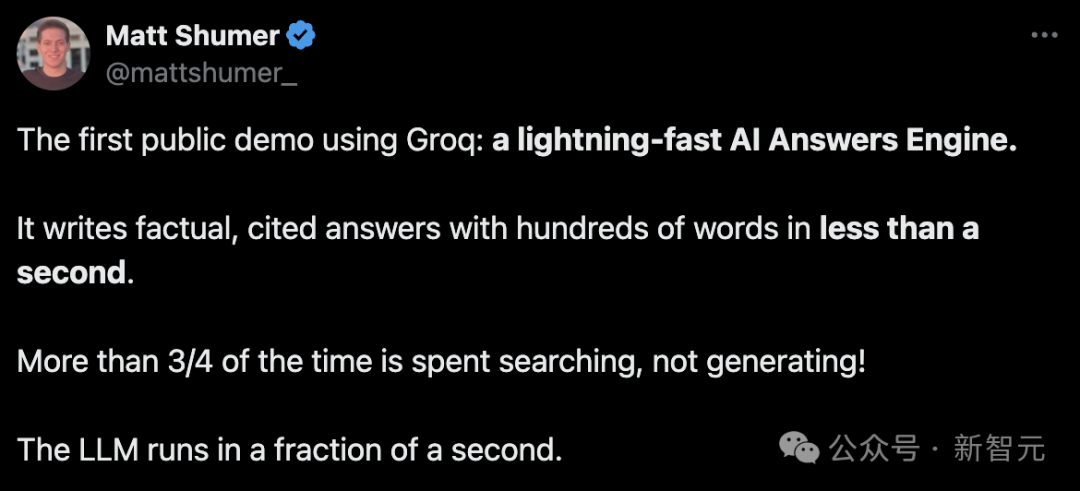 在不到一秒鐘的時間里,生成幾百詞的、帶有引用的事實性回答。實際上,搜索占據了超過四分之三的處理時間,而非內容的生成!
在不到一秒鐘的時間里,生成幾百詞的、帶有引用的事實性回答。實際上,搜索占據了超過四分之三的處理時間,而非內容的生成!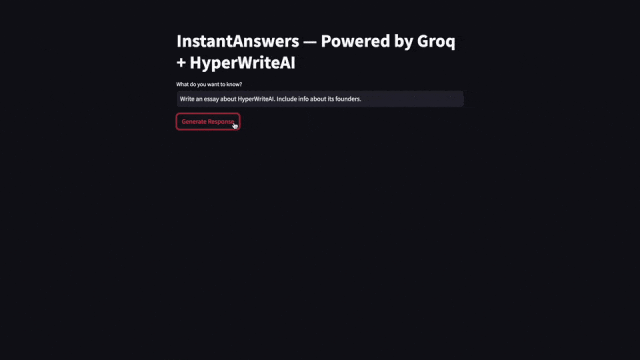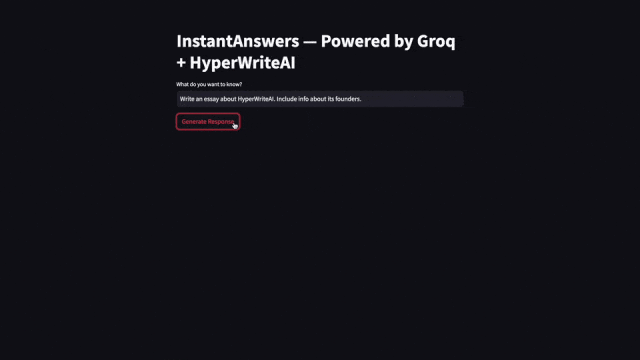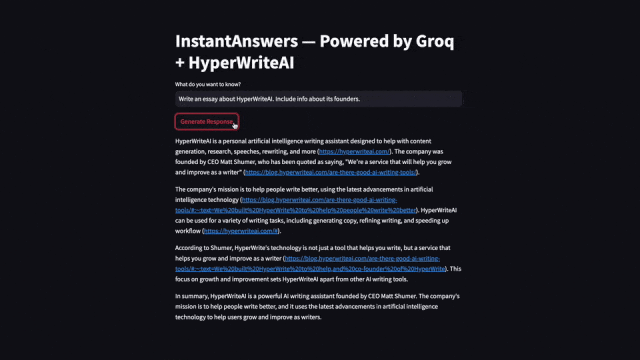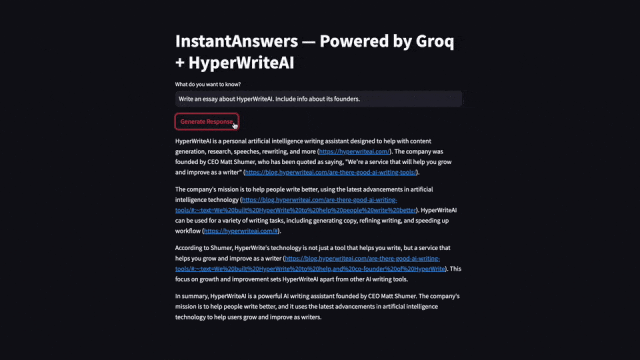 針對「創建一個簡單的健身計劃」同一提示,Groq與ChatGPT并排響應,速度差異。
針對「創建一個簡單的健身計劃」同一提示,Groq與ChatGPT并排響應,速度差異。

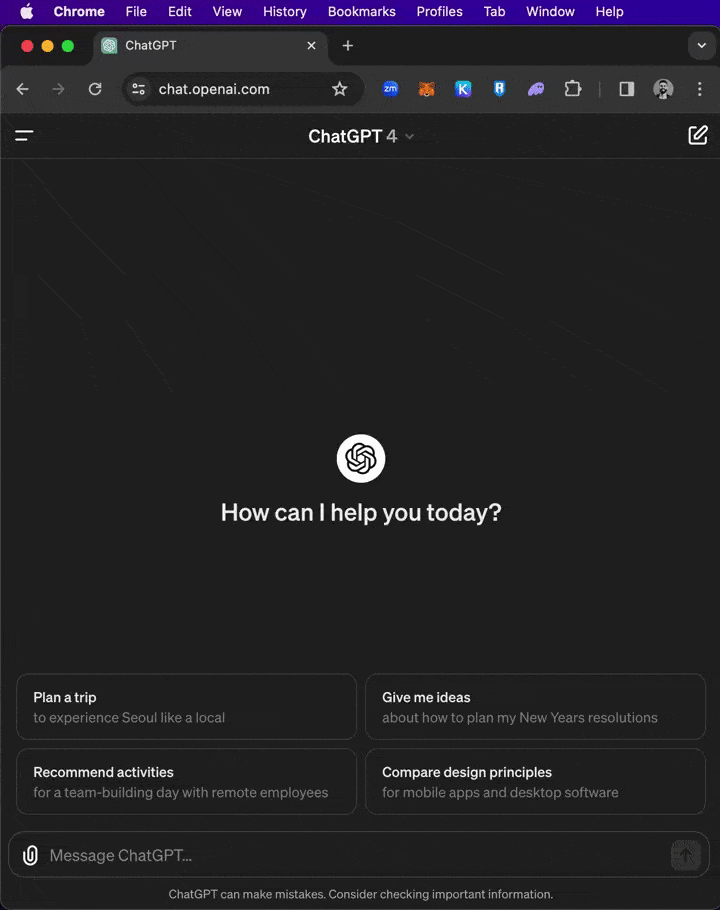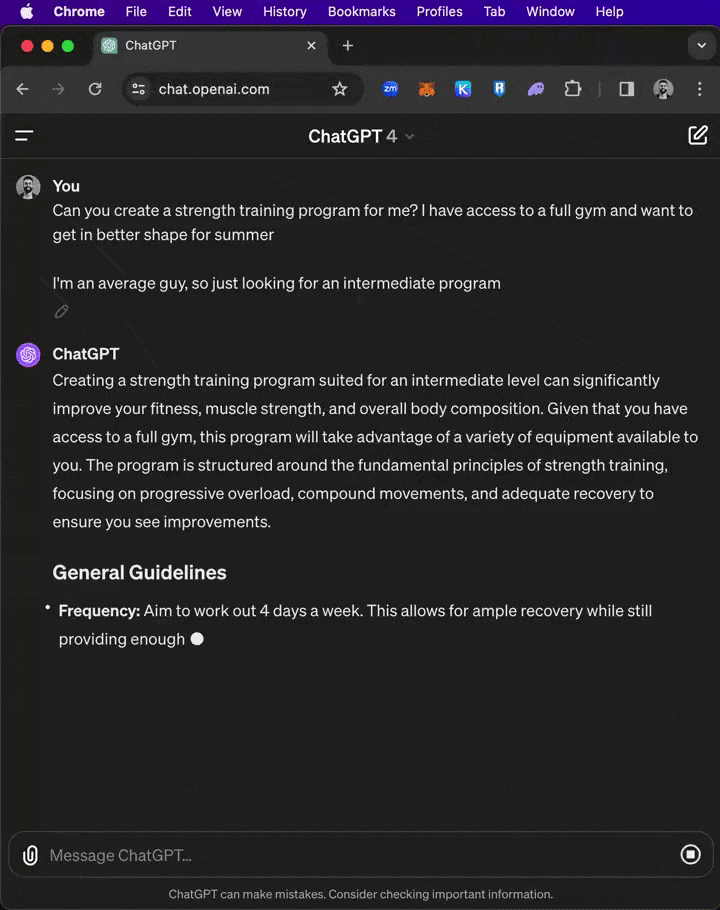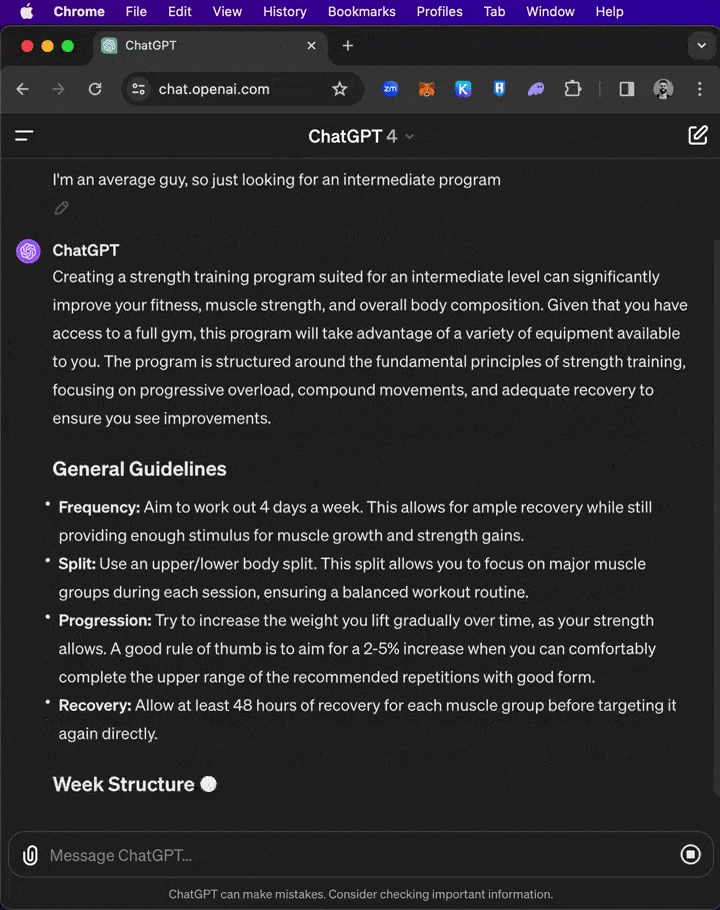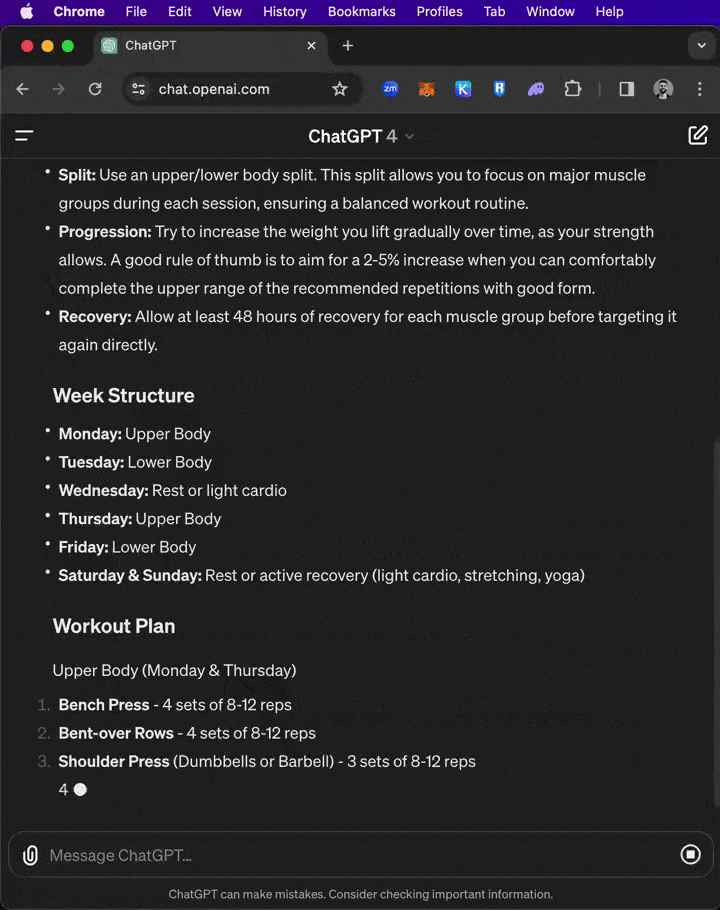 面對300多個單詞的「巨型」prompt,Groq在不到一秒鐘的時間里,就為一篇期刊論文創建了初步大綱和寫作計劃!
面對300多個單詞的「巨型」prompt,Groq在不到一秒鐘的時間里,就為一篇期刊論文創建了初步大綱和寫作計劃! Groq完全實現了遠程實時的AI對話。在GroqInc硬件上運行Llama 70B,然后在提供給Whisper,幾乎沒有延遲。
Groq完全實現了遠程實時的AI對話。在GroqInc硬件上運行Llama 70B,然后在提供給Whisper,幾乎沒有延遲。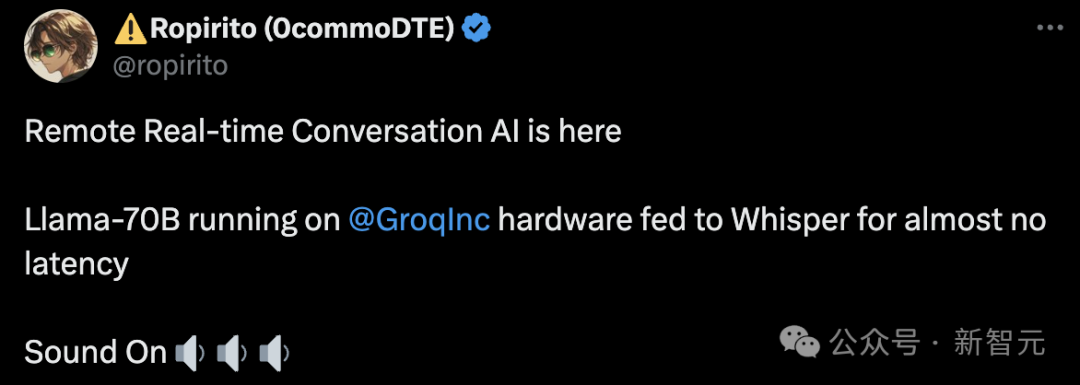
,時長02:05
GPU不存在了?
Groq模型之所以能夠以驚人速度響應,是因為背后公司Groq(同名)開發了獨特的硬件——LPU。并非是,傳統的GPU。 簡而言之,Groq自研的是一種名為張量流處理器(TSP)的新型處理單元,并將其定義為「語言處理單元」,即LPU。它是專為圖形渲染而設計、包含數百個核心的并行處理器,能夠為AI計算提供穩定的性能。
簡而言之,Groq自研的是一種名為張量流處理器(TSP)的新型處理單元,并將其定義為「語言處理單元」,即LPU。它是專為圖形渲染而設計、包含數百個核心的并行處理器,能夠為AI計算提供穩定的性能。
 不同于英偉達GPU需要依賴高速數據傳輸,Groq的LPU在其系統中沒有采用高帶寬存儲器(HBM)。它使用的是SRAM,其速度比GPU所用的存儲器快約20倍。
不同于英偉達GPU需要依賴高速數據傳輸,Groq的LPU在其系統中沒有采用高帶寬存儲器(HBM)。它使用的是SRAM,其速度比GPU所用的存儲器快約20倍。 鑒于AI的推理計算,相較于模型訓練需要的數據量遠小,Groq的LPU因此更節能。在執行推理任務時,它從外部內存讀取的數據更少,消耗的電量也低于英偉達的GPU。LPU并不像GPU那樣對存儲速度有極高要求。如果在AI處理場景中采用Groq的LPU,可能就無需為英偉達GPU配置特殊的存儲解決方案。
鑒于AI的推理計算,相較于模型訓練需要的數據量遠小,Groq的LPU因此更節能。在執行推理任務時,它從外部內存讀取的數據更少,消耗的電量也低于英偉達的GPU。LPU并不像GPU那樣對存儲速度有極高要求。如果在AI處理場景中采用Groq的LPU,可能就無需為英偉達GPU配置特殊的存儲解決方案。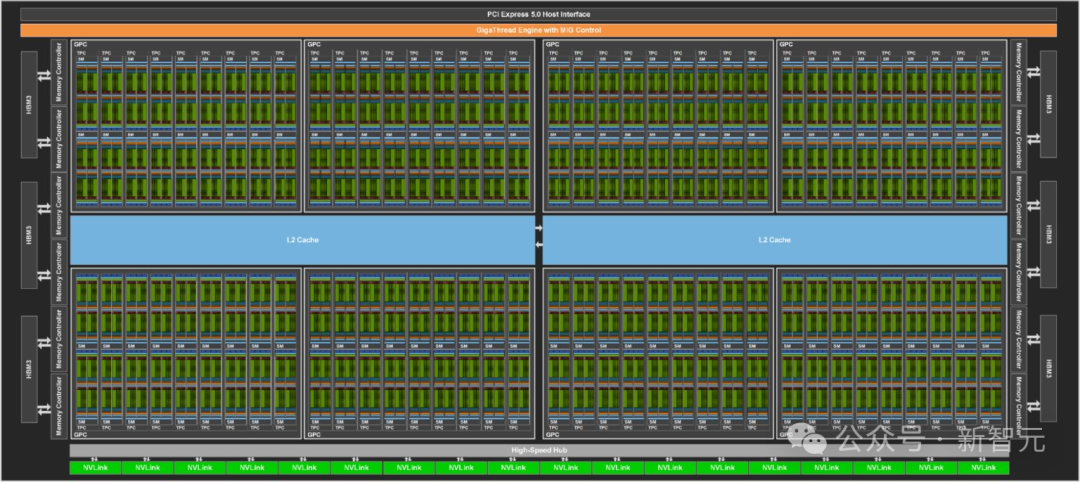 Groq的創新芯片設計實現了多個TSP的無縫鏈接,避免了GPU集群中常見的瓶頸問題,極大地提高了可擴展性。這意味著隨著更多LPU的加入,性能可以實現線性擴展,簡化了大規模AI模型的硬件需求,使開發者能夠更容易地擴展應用,而無需重構系統。Groq公司宣稱,其技術能夠通過其強大的芯片和軟件,在推理任務中取代GPU的角色。網友做的具體規格對比圖。
Groq的創新芯片設計實現了多個TSP的無縫鏈接,避免了GPU集群中常見的瓶頸問題,極大地提高了可擴展性。這意味著隨著更多LPU的加入,性能可以實現線性擴展,簡化了大規模AI模型的硬件需求,使開發者能夠更容易地擴展應用,而無需重構系統。Groq公司宣稱,其技術能夠通過其強大的芯片和軟件,在推理任務中取代GPU的角色。網友做的具體規格對比圖。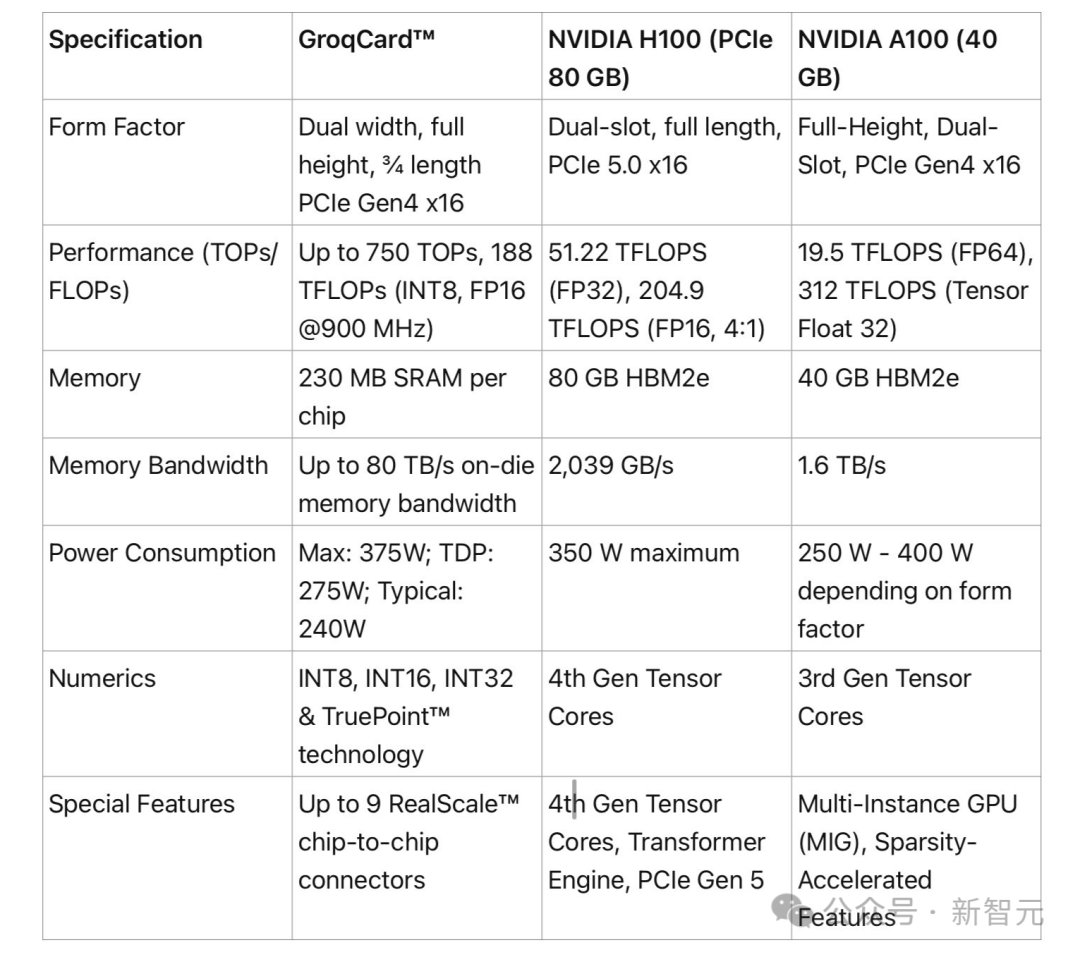 這一切意味著什么?對開發者來說,這意味著性能可以被精確預測并優化,這一點對于實時AI應用至關重要。對于未來AI應用的服務而言,LPU可能會帶來與GPU相比巨大的性能提升!考慮到A100和H100如此緊缺,對于那些初創公司擁有這樣的高性能替代硬件,無疑是一個巨大的優勢。目前,OpenAI正在向全球政府和投資者尋求7萬億美元的資金,以開發自己的芯片,解決擴展其產品時遇到算力不足的問題。
這一切意味著什么?對開發者來說,這意味著性能可以被精確預測并優化,這一點對于實時AI應用至關重要。對于未來AI應用的服務而言,LPU可能會帶來與GPU相比巨大的性能提升!考慮到A100和H100如此緊缺,對于那些初創公司擁有這樣的高性能替代硬件,無疑是一個巨大的優勢。目前,OpenAI正在向全球政府和投資者尋求7萬億美元的資金,以開發自己的芯片,解決擴展其產品時遇到算力不足的問題。
2倍吞吐量,響應速度僅0.8秒
前段時間,在ArtifialAnalysis.ai的LLM基準測試中,Groq的方案擊敗了8個關鍵性能指標。其中包括在延遲與吞吐量、隨時間的吞吐量、總響應時間和吞吐量差異。在右下角的綠色象限中,Groq取得最優的成績。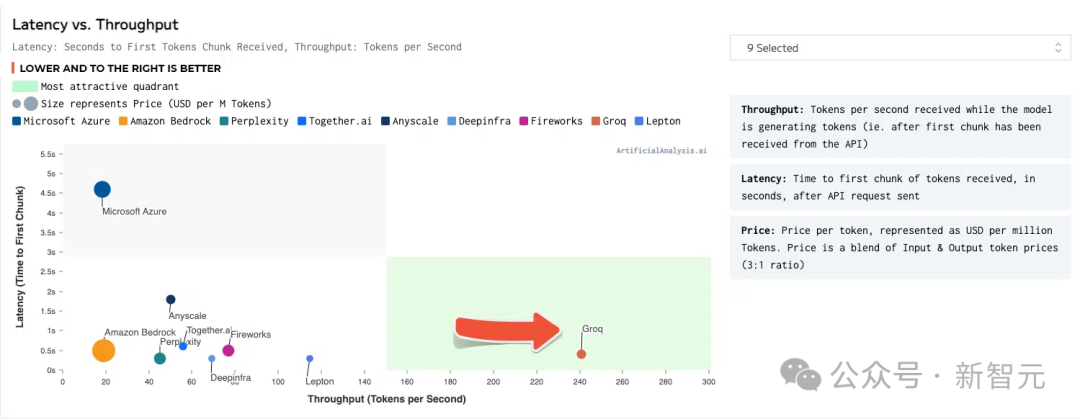

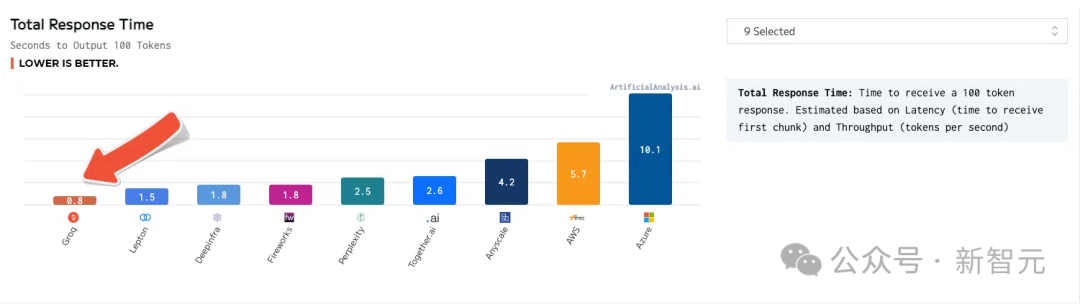 另外,Groq已經運行了幾個內部基準,可以達到每秒300個token,再次設定了全新的速度標準。Groq首席執行官Jonathan Ross曾表示,「Groq的存在是為了消除「富人和窮人」,并幫助人工智能社區中的每個人發展。而推理是實現這一目標的關鍵,因為『速度』是將開發人員的想法轉化為商業解決方案和改變生APP的關鍵」。
另外,Groq已經運行了幾個內部基準,可以達到每秒300個token,再次設定了全新的速度標準。Groq首席執行官Jonathan Ross曾表示,「Groq的存在是為了消除「富人和窮人」,并幫助人工智能社區中的每個人發展。而推理是實現這一目標的關鍵,因為『速度』是將開發人員的想法轉化為商業解決方案和改變生APP的關鍵」。
一塊卡2萬刀,內存230MB
想必大家在前面已經注意到了,一張LPU卡僅有230MB的內存。 而且,售價為2萬+美元。
而且,售價為2萬+美元。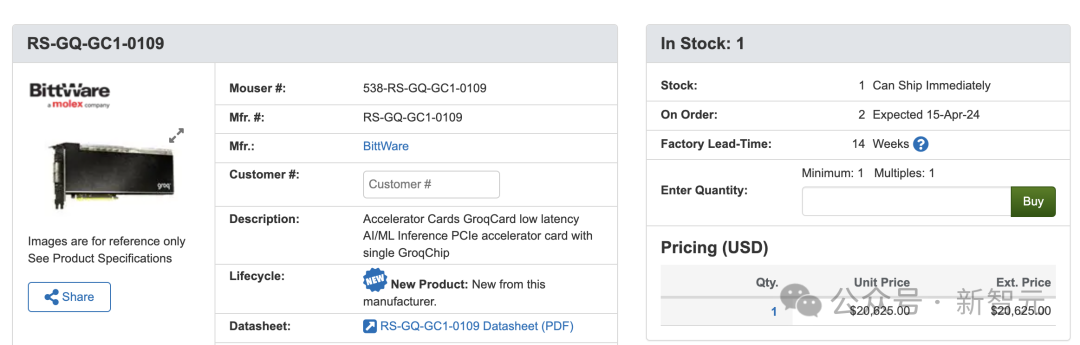 根據The Next Platform的報道,在以上的測試中,Groq實際上使用了576個GroqChip,才實現了對Llama 2 70B的推理。
根據The Next Platform的報道,在以上的測試中,Groq實際上使用了576個GroqChip,才實現了對Llama 2 70B的推理。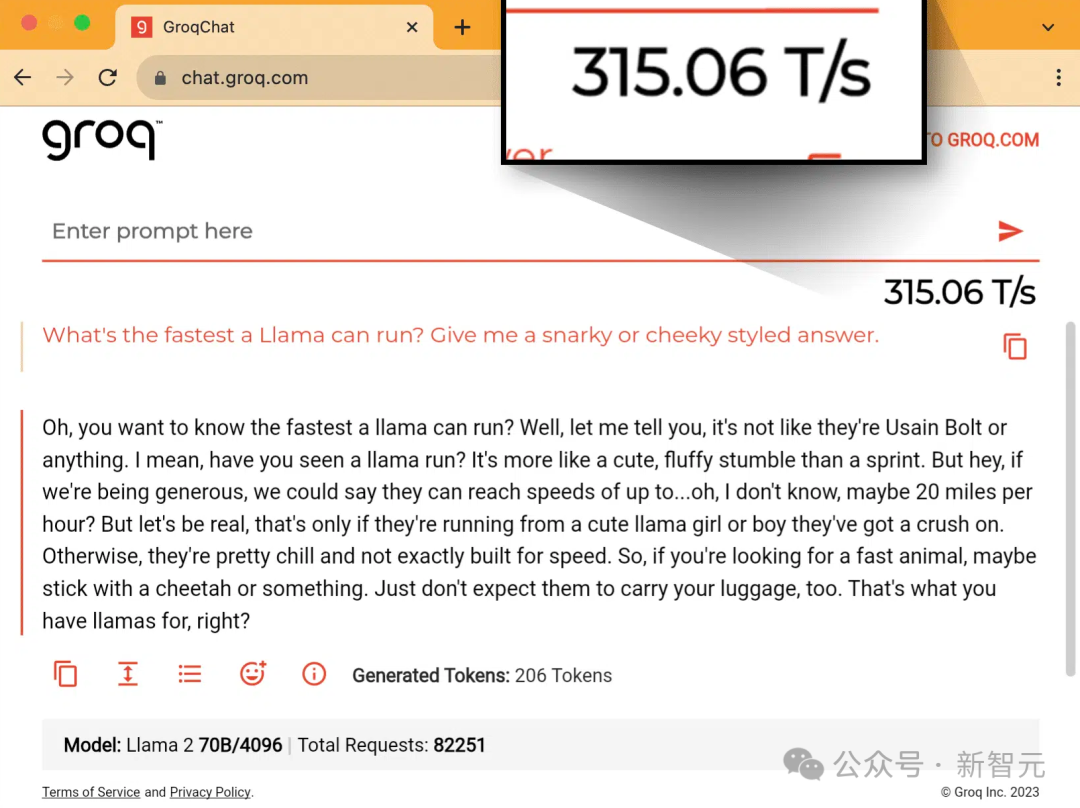 通常來說,GroqRack配備有9個節點,其中8個節點負責計算任務,剩下1個節點作為備用。但這次,9個節點全部被用于計算工作。
通常來說,GroqRack配備有9個節點,其中8個節點負責計算任務,剩下1個節點作為備用。但這次,9個節點全部被用于計算工作。 對此網友表示,Groq LPU面臨的一個關鍵問題是,它們完全不配備高帶寬存儲器(HBM),而是僅配備了一小塊(230MiB)的超高速靜態隨機存取存儲器(SRAM),這種SRAM的速度比HBM3快20倍。這意味著,為了支持運行單個AI模型,你需要配置大約256個LPU,相當于4個滿載的服務器機架。每個機架可以容納8個LPU單元,每個單元中又包含8個LPU。相比之下,你只需要一個H200(相當于1/4個服務器機架的密度)就可以相當有效地運行這些模型。這種配置如果用于只需運行一個模型且有大量用戶的場景下可能表現良好。但是,一旦需要同時運行多個模型,特別是需要進行大量的模型微調或使用高級別的LoRA等操作時,這種配置就不再適用。此外,對于需要在本地部署的情況,Groq LPU的這一配置優勢也不明顯,因為其主要優勢在于能夠集中多個用戶使用同一個模型。
對此網友表示,Groq LPU面臨的一個關鍵問題是,它們完全不配備高帶寬存儲器(HBM),而是僅配備了一小塊(230MiB)的超高速靜態隨機存取存儲器(SRAM),這種SRAM的速度比HBM3快20倍。這意味著,為了支持運行單個AI模型,你需要配置大約256個LPU,相當于4個滿載的服務器機架。每個機架可以容納8個LPU單元,每個單元中又包含8個LPU。相比之下,你只需要一個H200(相當于1/4個服務器機架的密度)就可以相當有效地運行這些模型。這種配置如果用于只需運行一個模型且有大量用戶的場景下可能表現良好。但是,一旦需要同時運行多個模型,特別是需要進行大量的模型微調或使用高級別的LoRA等操作時,這種配置就不再適用。此外,對于需要在本地部署的情況,Groq LPU的這一配置優勢也不明顯,因為其主要優勢在于能夠集中多個用戶使用同一個模型。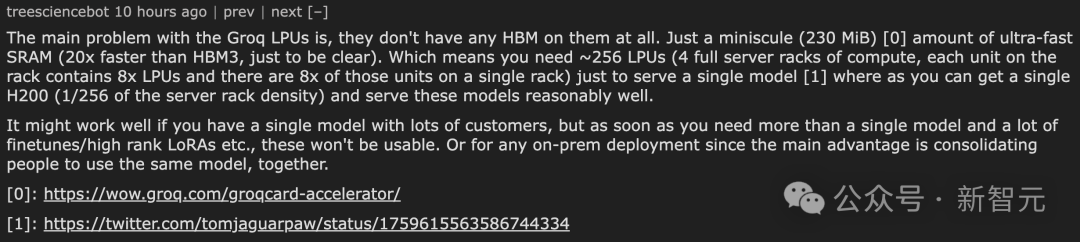 另有網友表示,「Groq LPU似乎沒有任何HBM,而且每個芯片基本上都帶有少量的SRAM?也就是說他們需要大約256個芯片來運行Llama 70B?」沒想到得到了官方回應:是的,我們的LLM在數百個芯片上運行。
另有網友表示,「Groq LPU似乎沒有任何HBM,而且每個芯片基本上都帶有少量的SRAM?也就是說他們需要大約256個芯片來運行Llama 70B?」沒想到得到了官方回應:是的,我們的LLM在數百個芯片上運行。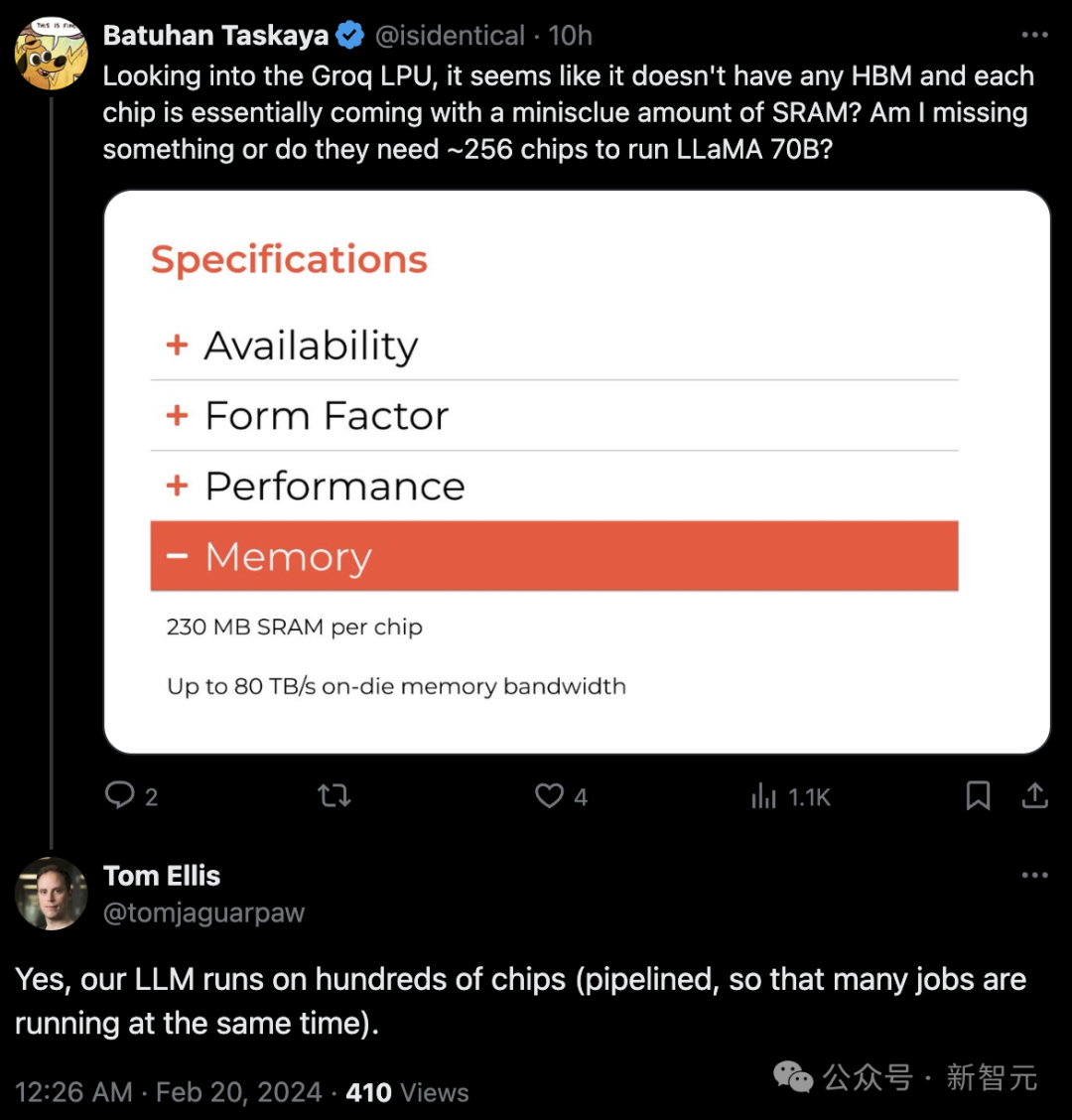 還有人對LPU的卡的價錢提出了異議,「這難道不會讓你的產品比H100貴得離譜嗎」?
還有人對LPU的卡的價錢提出了異議,「這難道不會讓你的產品比H100貴得離譜嗎」?
馬斯克Grok,同音不同字
前段時間,Groq曾公開基準測試結果后,已經引來了一大波關注。而這次,Groq這個最新的AI模型,憑借其快速響應和可能取代GPU的新技術,又一次在社交媒體上掀起了風暴。不過,Groq背后的公司并非大模型時代后的新星。它成立于2016年,并直接注冊了Groq這一名字。 CEO兼聯合創始人Jonathan Ross在創立Groq之前,曾是谷歌的員工。曾在一個20%的項目中,設計并實現了第一代TPU芯片的核心元素,這就是后來的谷歌張量處理單元(TPU)。隨后,Ross加入了谷歌X實驗室的快速評估團隊(著名的「登月工廠」項目初始階段),為谷歌母公司Alphabet設計和孵化新的Bets(單元)。
CEO兼聯合創始人Jonathan Ross在創立Groq之前,曾是谷歌的員工。曾在一個20%的項目中,設計并實現了第一代TPU芯片的核心元素,這就是后來的谷歌張量處理單元(TPU)。隨后,Ross加入了谷歌X實驗室的快速評估團隊(著名的「登月工廠」項目初始階段),為谷歌母公司Alphabet設計和孵化新的Bets(單元)。 或許大多數人對馬斯克Grok,還有Groq模型的名字感到迷惑。
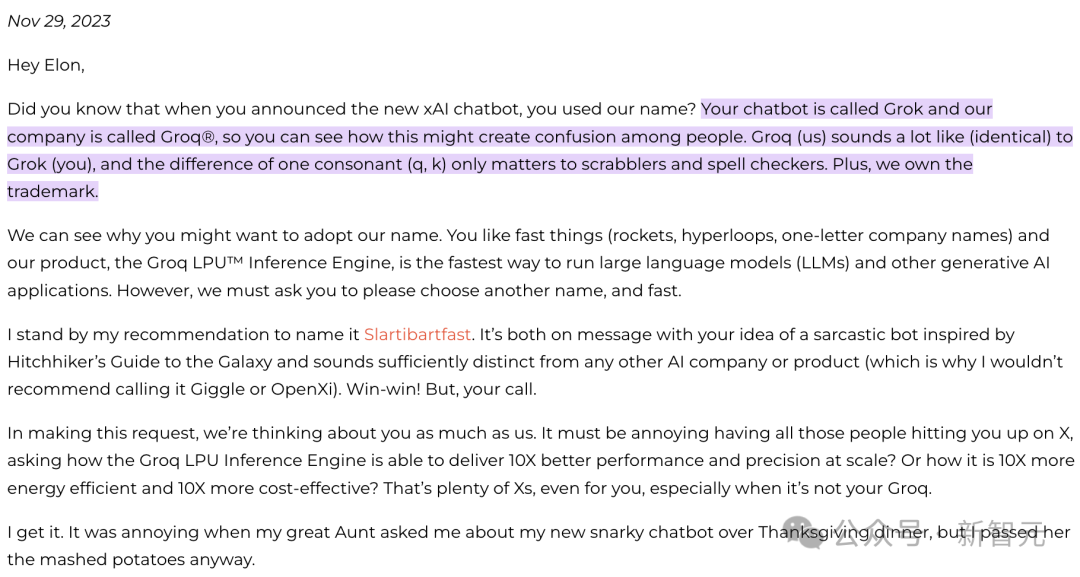
或許大多數人對馬斯克Grok,還有Groq模型的名字感到迷惑。 其實,在勸退馬斯克使用這個名字時,還有個小插曲。去年11月,當馬斯克的同名AI模型Grok(拼寫有所不同)開始受到關注時,Groq的開發團隊發表了一篇博客,幽默地請馬斯克另選一個名字:
其實,在勸退馬斯克使用這個名字時,還有個小插曲。去年11月,當馬斯克的同名AI模型Grok(拼寫有所不同)開始受到關注時,Groq的開發團隊發表了一篇博客,幽默地請馬斯克另選一個名字:我們明白你為什么會喜歡我們的名字。你對快速的事物(如火箭、超級高鐵、單字母公司名稱)情有獨鐘,而我們的Groq LPU推理引擎正是運行LLM和其他生成式AI應用的最快方式。但我們還是得請你趕緊換個名字。
 不過,馬斯克并未對兩個模型名稱的相似之處作出回應。
不過,馬斯克并未對兩個模型名稱的相似之處作出回應。 *博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
