將 ChatGPT 用于數據科學項目的指南

推薦:使用NSDT場景編輯器快速搭建3D應用場景
我們都知道 ChatGPT 的受歡迎程度以及人們如何使用它來提高生產力。但是,如果您是新手,則值得注冊ChatGPT免費演示并嘗試它所能做的一切。您還應該參加我們的 ChatGPT 簡介課程,學習制作有效提示的最佳實踐,并探索利用這一強大 AI 工具的常見業務用例。
在本教程中,我們將學習如何使用 ChatGPT 來處理端到端的數據科學項目。我們將使用各種提示來創建項目大綱、編寫 Python 代碼、進行研究和調試應用程序。此外,我們將學習編寫有效的 ChatGPT 提示的技巧。
使用 ChatGPT 進行端到端數據科學項目在項目中,我們將使用來自DataCamp Workspace的貸款數據,并圍繞它規劃數據科學項目。
ChatGPT 在這里完成了 80% 的工作,我們只需要掌握快速工程就可以讓一切正確,為此,我們有令人驚嘆的 ChatGPT 數據科學備忘單。它帶有60 + ChatGPT提示,用于基于SQL,R和Python的數據科學任務。
項目規劃這是項目中最重要的部分,我們在其中查看可用資源和目標以提出最佳策略。
您可以轉到 chat.openai.com 并發起新的聊天。之后,我們將提及可用的貸款數據集,并要求 ChatGPT 提出構建端到端通用投資組合項目的步驟。
提示:“我有一個由 9500 行和 14 列組成的貸款數據集:['credit.policy', 'purpose', 'int.rate', 'installment', 'log.annual.inc', 'dti', 'fico', 'days.with.cr.line', 'revol.bal', 'revol.util', 'inq.last.6mths', 'delinq.2yrs', 'pub.rec', 'not.full.paid']。你能列出我必須遵循的步驟來為我的投資組合開發一個端到端的項目嗎?
我們確實拿到了清單,但是忘了提階級失衡問題和項目目標,就是準確預測“貸款不還”。
更新提示:“請包括階級不平衡問題,并準確預測貸款是否會償還,而不是貸款是否償還。
同樣,我們對模型監控不感興趣,我們希望構建一個Gradio應用程序并將其部署在Huggingface Spaces上。
更新提示:“我們將使用 Gradio 創建一個 Web 應用程序并將其部署到 Spaces 上,我們不會在生產中監控模型。

作者動圖 |項目中涉及的步驟的最終列表
我們得到了一個包含 9 個步驟的列表,如上所示,并詳細說明了我們應該如何處理每個步驟。
以下是我們將在本教程中遵循的任務列表:
數據清理和預處理。處理缺失值、將分類變量轉換為數值變量、縮放/規范化數據以及處理數據中的任何異常值或異常。此外,您需要通過對少數階級(未全額支付的貸款)進行過度抽樣或對多數階級(全額支付的貸款)進行過抽樣來解決階級不平衡問題。
探索性數據分析 (EDA)。瀏覽數據集以深入了解數據,例如變量的分布、變量之間的相關性以及識別數據中的任何模式。
特征工程。創建新特征或轉換現有特征以提高模型的預測能力。
型號選擇。嘗試多種模型,例如決策樹、隨機森林、邏輯回歸或支持向量機 (SVM)。
模型訓練和評估。根據數據訓練所選模型,并使用各種指標(如準確性、精度、召回率和 F1 分數)評估其性能。
超參數優化。微調所選模型的超參數以提高其性能。
使用 Gradio 創建 Web 應用程序。選擇最佳模型后,您可以使用 Gradio 創建 Web 應用程序。
在空間上部署 Web 應用程序。使用 Gradio 創建 Web 應用程序后,您可以將其部署到 Spaces 上。
測試 Web 應用。測試它以確保它按預期工作。
探索性數據分析是關于數據操作、統計分析和數據可視化的。我們可以通過編寫有關編寫 Python 代碼以在我們的數據集上進行探索性數據分析的后續提示來完成它。
后續提示:“請編寫一個 Python 代碼來加載并執行貸款數據集的探索性數據分析 (EDA)”
機器人將理解上下文,并提出帶有注釋和詳細說明其工作原理的 Python 代碼。
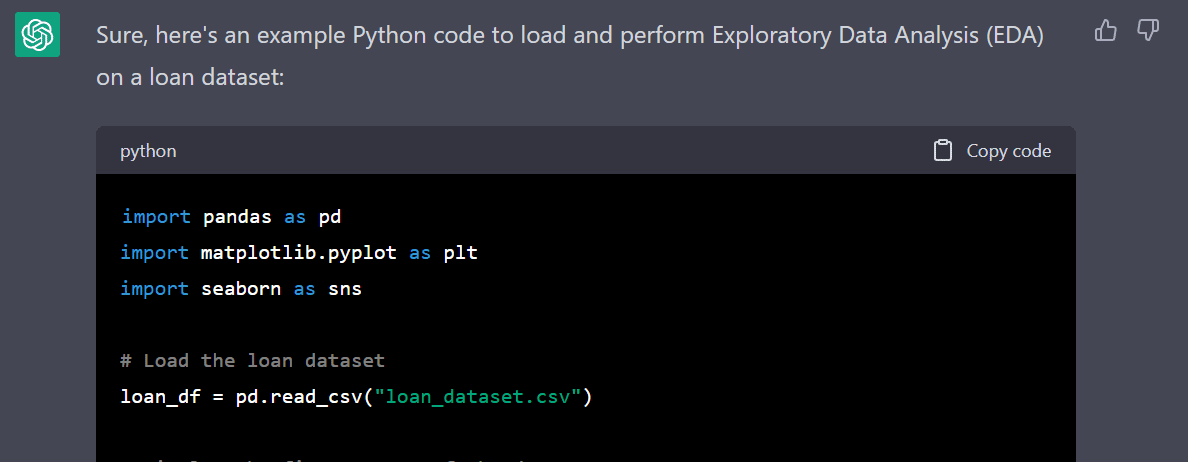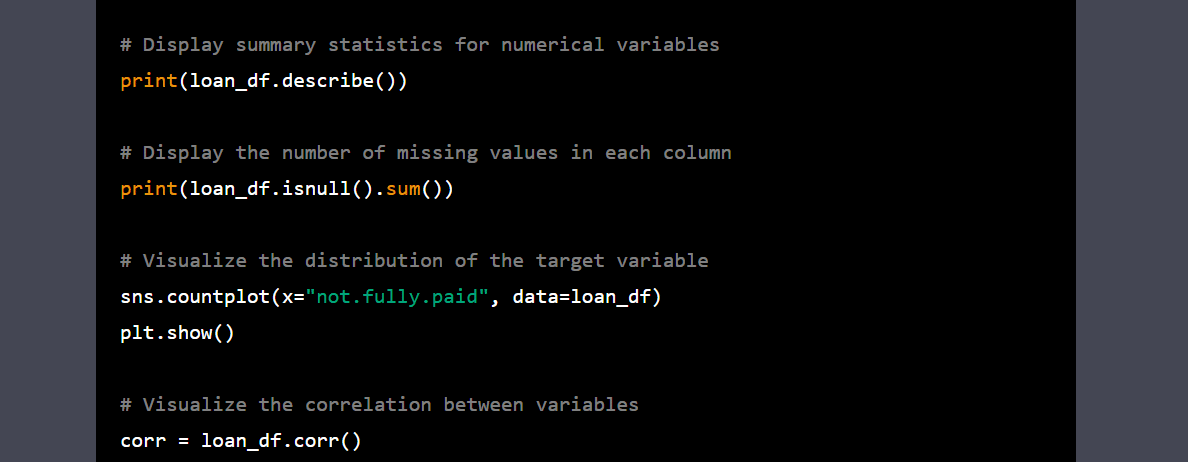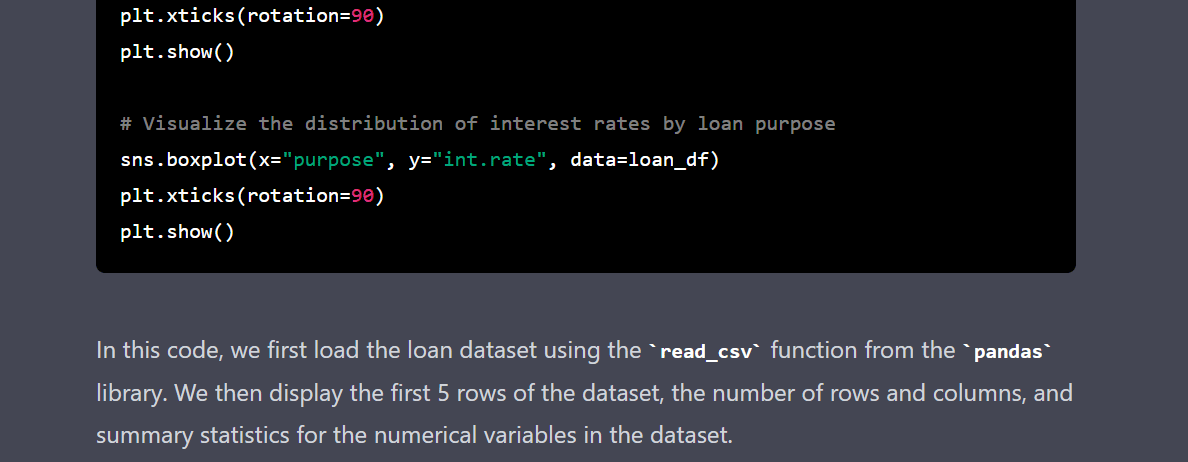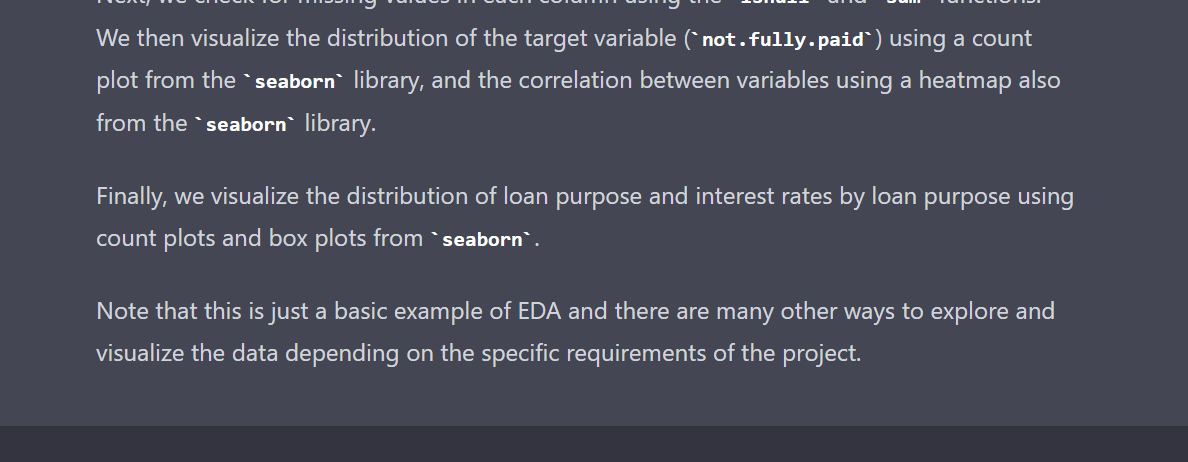
作者動圖 |用于 EDA 的 Python 代碼
將數據集加載并顯示為 Pandas 數據幀。


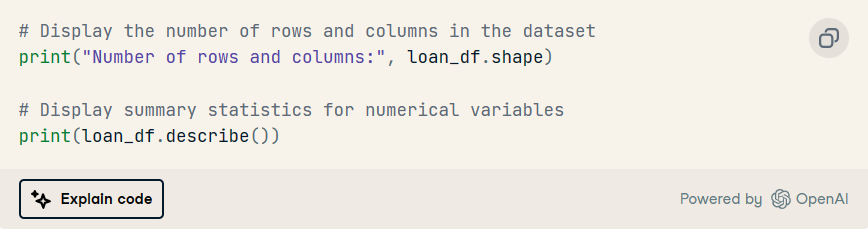
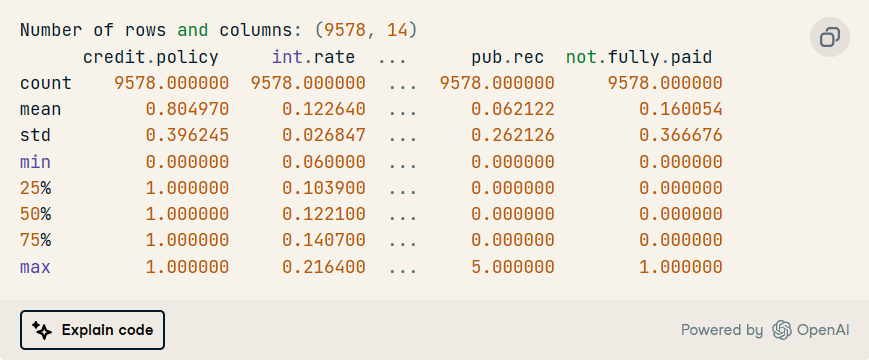
2. 顯示數值變量的行數和列數以及統計摘要。
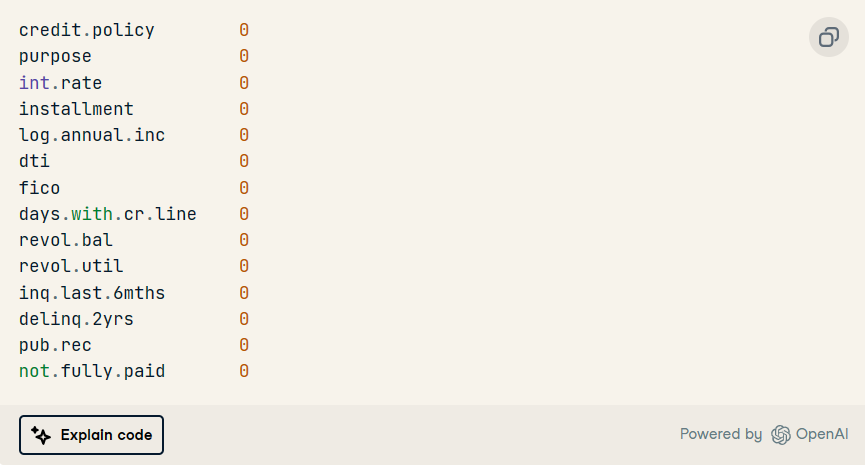
3. 在每列中顯示缺失值。正如我們所看到的,我們沒有。

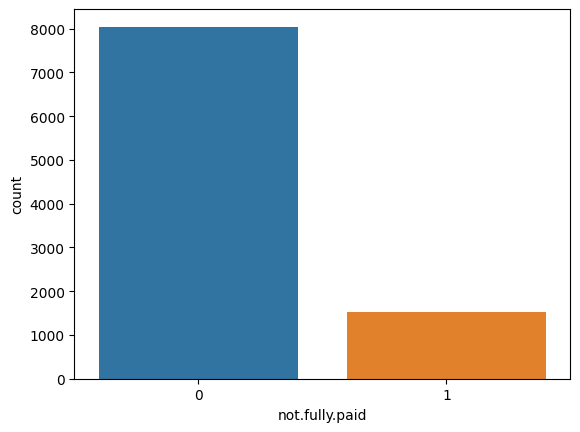
4. 可視化目標變量“not.full.paid”的分布

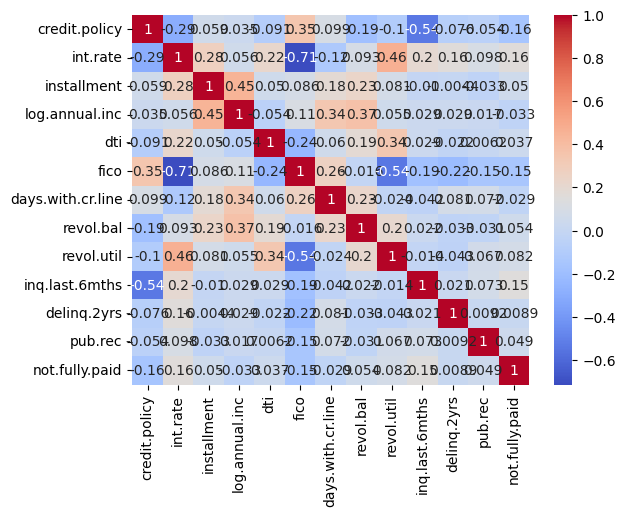
5. 可視化變量之間的相關性。

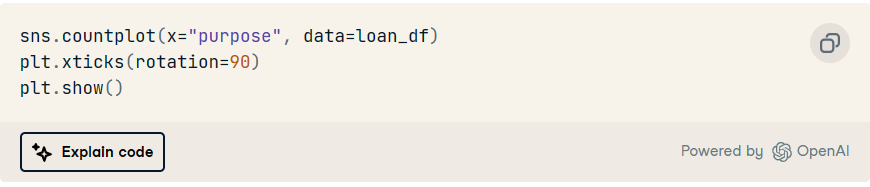
6. 了解貸款用途分布。
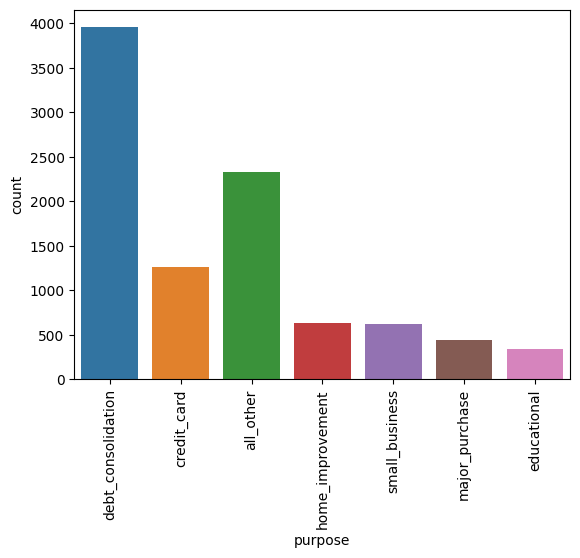
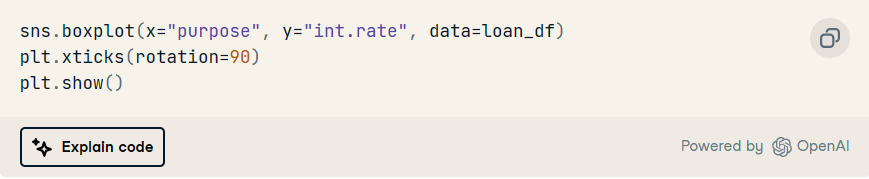
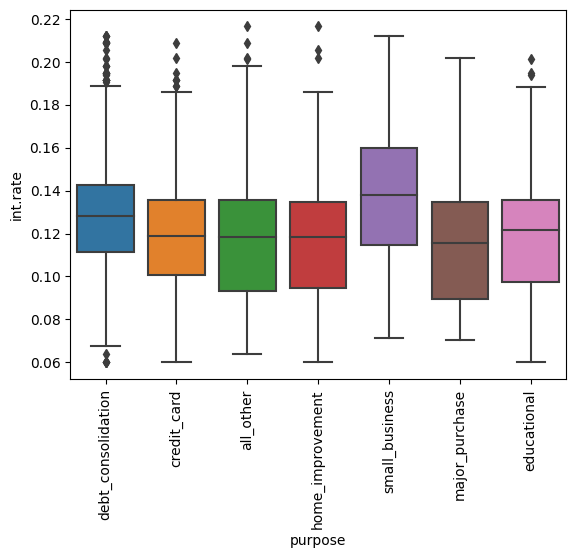
7. 了解按貸款用途劃分的利率分布。
我們將執行特征工程以簡化預處理任務,而不是預處理和清理數據。
后續提示:“編寫 Python 代碼執行特征工程”
我們確實得到了正確的解決方案,但它包含不相關的代碼,因此我們必須編寫更新提示來修改代碼。
更新提示:“僅添加特征工程部分。
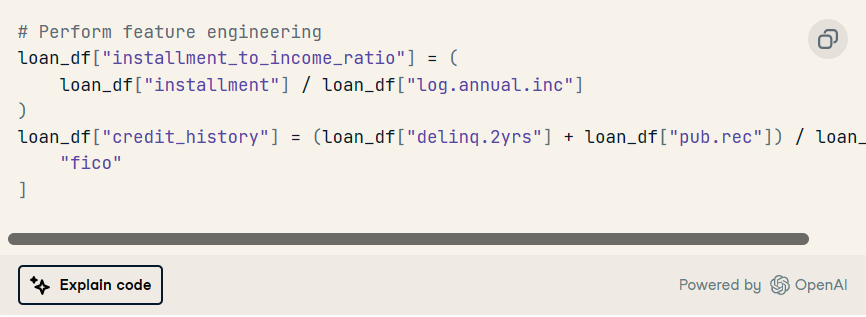
ChatGPT提出了兩個新功能:“installment_to_income_ratio”和“credit_history”。
預處理和平衡數據同樣,ChatGPT知道項目的背景。我們不必再次解釋一切。因此,我們將簡單地要求它編寫一個 Python 代碼來清理和預處理數據。
后續提示:“現在編寫一個python代碼來清理和預處理數據集”
刪除不必要的列并將分類變量轉換為數字變量。
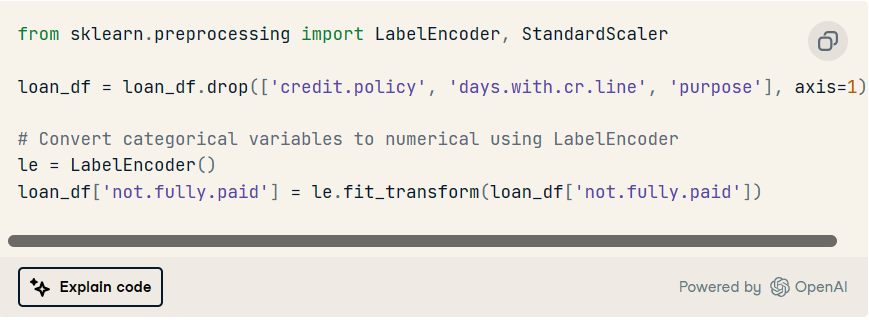
2. 使用標準縮放器縮放數值要素。
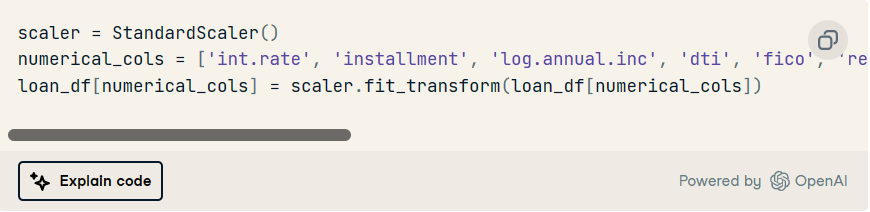
3. 使用 imblearn 的過采樣方法處理類不平衡。
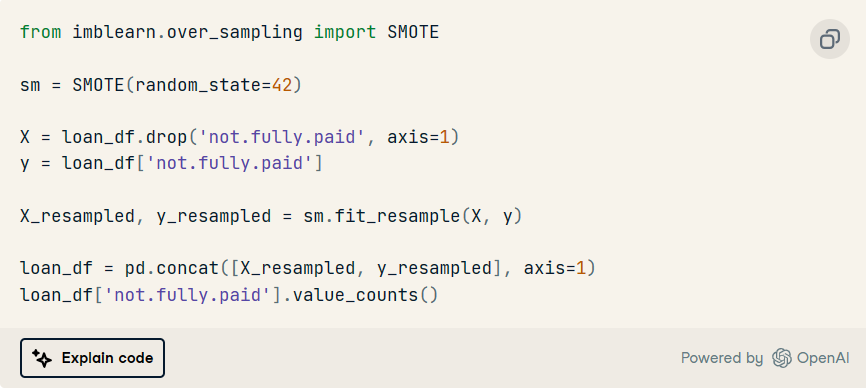
正如我們所看到的,我們已經成功地平衡了班級。
在這一部分中,我們要求 ChatGPT 為模型選擇任務訓練各種模型的數據。
后續提示:“編寫用于模型選擇的后續 python 代碼。嘗試決策樹、隨機森林、邏輯回歸或支持向量機 (SVM)。注意:僅包括模型選擇部分。
它生成了 Python 腳本,用于將數據集拆分為訓練和測試,并在指定模型上訓練數據集以顯示準確性指標。
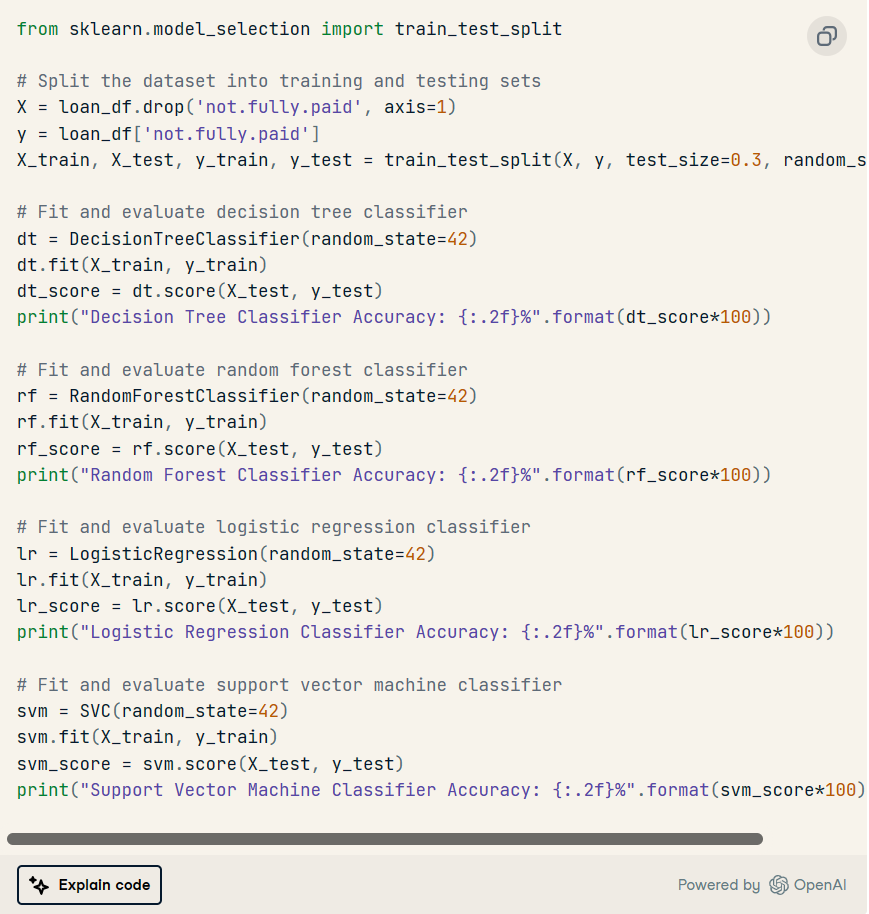
隨機森林算法的性能明顯優于其他模型。
我們將選擇性能更好的模型并進行模型評估。我們指定使用準確性、精度、召回率和 F1 分數作為指標和交叉驗證,以確保模型的穩定性。
后續提示:“選擇 RandomForestClassifier 并編寫用于模型評估的 python 代碼。使用準確性、精度、召回率和 F1 分數作為指標和交叉驗證,以確保模型不會過度擬合訓練數據。
我們將更新 Python 以添加超參數調優任務并保存性能最佳的模型。
更新提示:“在上面的代碼中還包括超參數調優并保存性能最佳的模型”
代碼的最終版本使用 GridSearchCV 進行具有五個交叉驗證拆分的超參數優化,并使用 f1 指標進行評估以查找最佳超參數。
之后,ChatGPT 自動添加代碼,在測試集上選擇最佳模型進行模型評估,并顯示性能最佳的超參數。
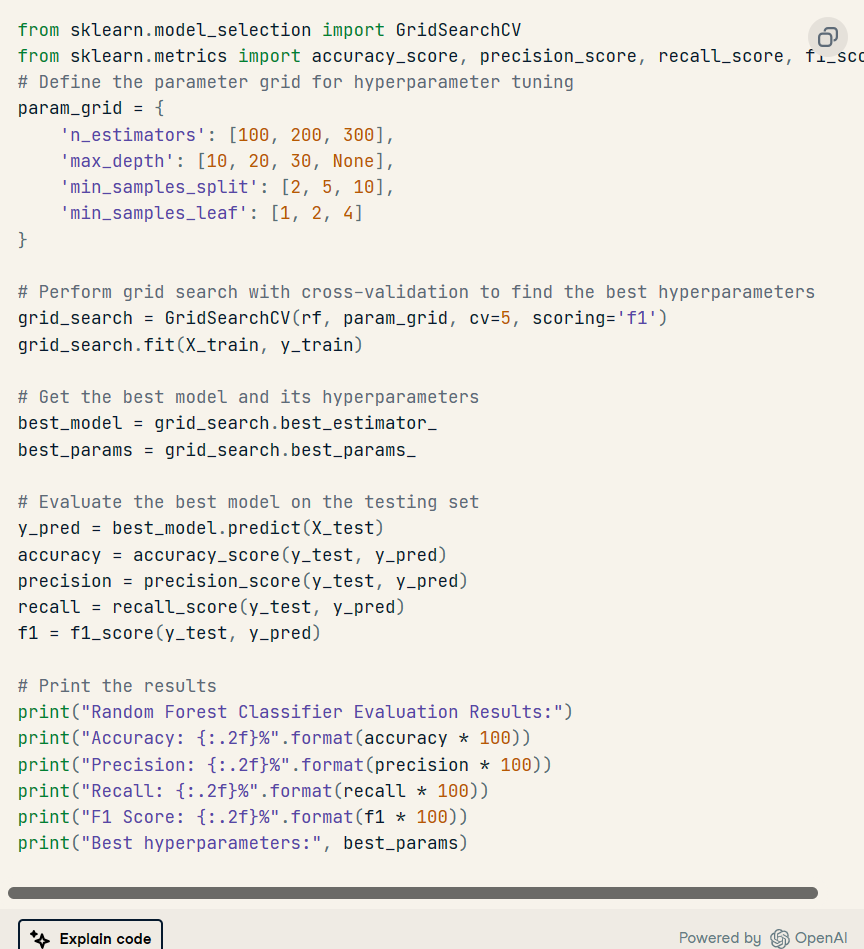
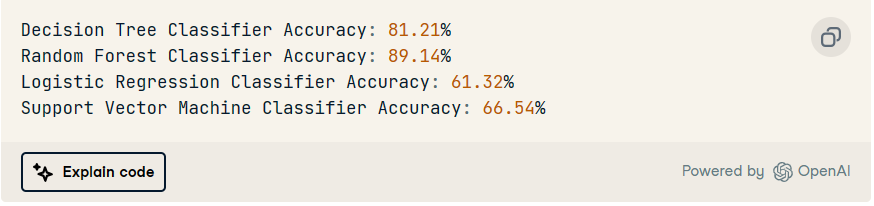
我們有一個穩定的模型,準確率為 89.35。精度和召回率相似。
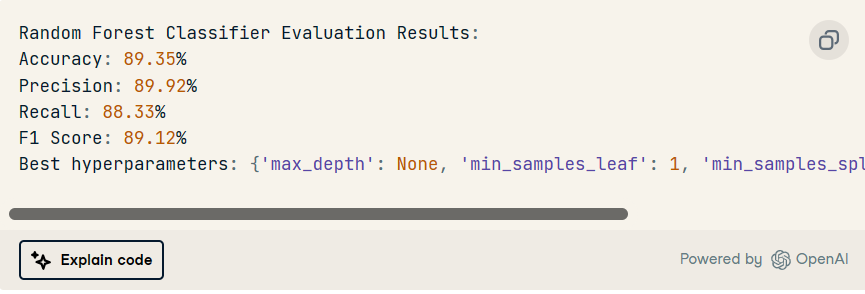
最后,我們將使用 joblib 保存模型。
可以在 DataCamp 工作區中找到包含輸出的源代碼。
使用 Gradio 創建 Web 應用程序現在是最有趣的部分。我們將僅使用提示來創建完全可自定義的 Web 應用程序,該應用程序將接受數字輸入并使用機器學習模型顯示結果。
ChatGPT 已經知道上下文,所以我們需要讓它為貸款數據分類器編寫一個 Gradio Web 應用程序。
后續提示:“編寫 Python 代碼以創建用于貸款數據分類器的 Gradio Web 應用程序。我們不使用列['credit.policy', 'days.with.cr.line', 'purpose']。
要求 ChatGPT 只包含 Gradio 應用程序部分,而不是訓練,然后包含推理腳本。
更新提示:“只需包含 gradio 應用程序部分。
我們得到的代碼顯示預測類概率,我們希望顯示分類標簽。
更新提示:“修改代碼以顯示分類而不是類概率。
運行代碼后,我們看到了多個警告和錯誤。您可以通過向 ChatGPT 提及錯誤來改進它。
我們需要了解 ChatGPT 的局限性。它是在一個舊數據集上訓練的,如果你希望它使用最新的API更新代碼,你會碰壁。相反,我們必須閱讀 Gradio 文檔并手動更新代碼。
失敗提示:“使用 gradio.components 中的組件更新 Gradio 代碼”
在 Gradio 應用程序中,我們正在加載保存的模型并從用戶那里獲取輸入以顯示模型預測。
通過閱讀 Gradio 文檔了解 Gradio 的工作原理。

您可以將上述代碼保存在“app.py”文件中,并通過在終端中運行“python app.py”腳本在瀏覽器中啟動應用程序。
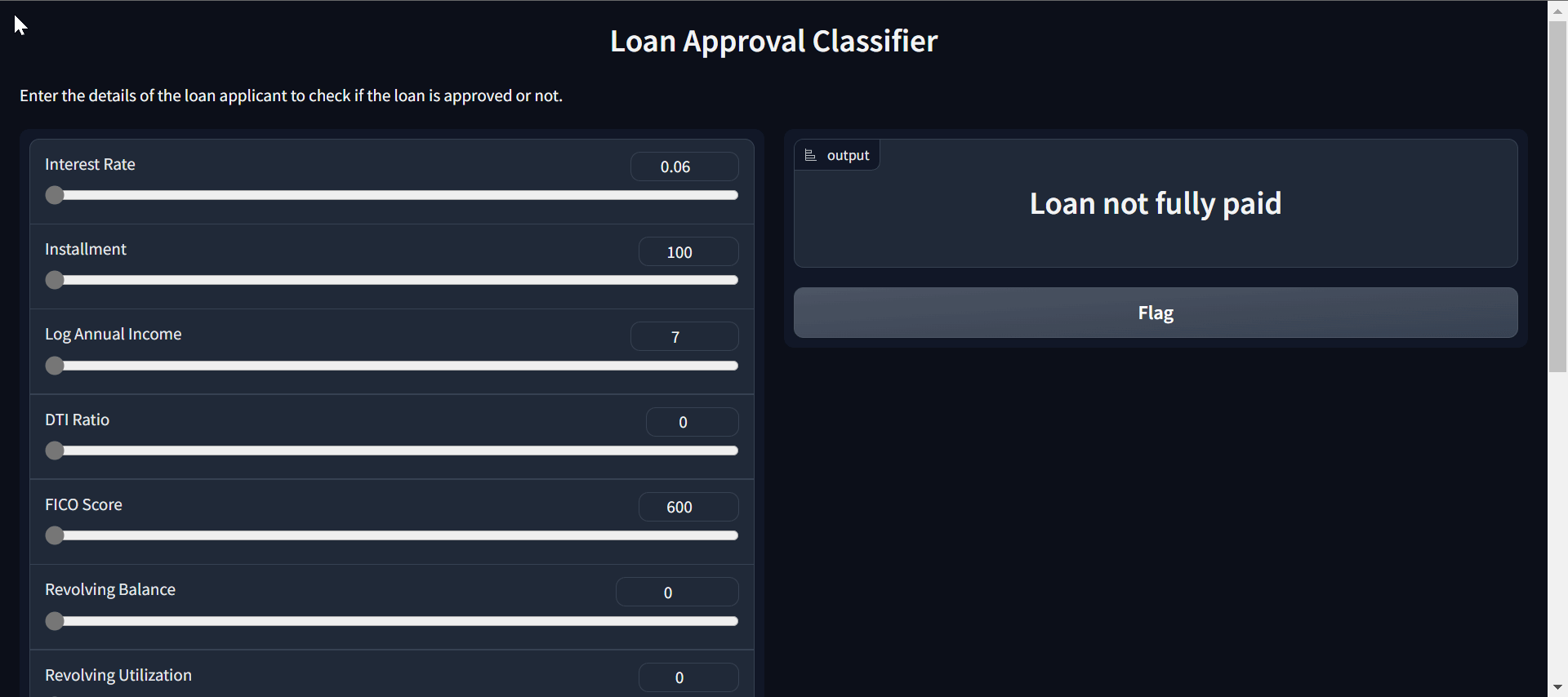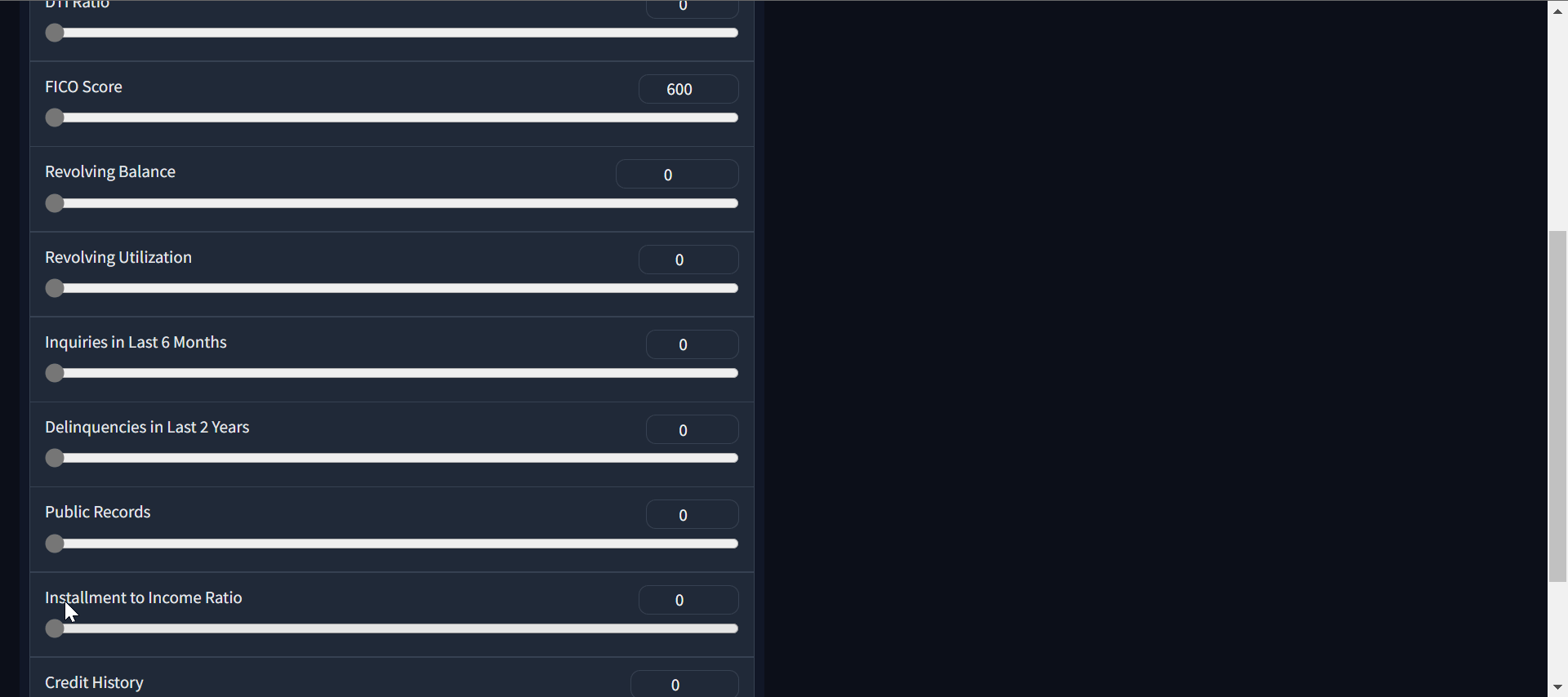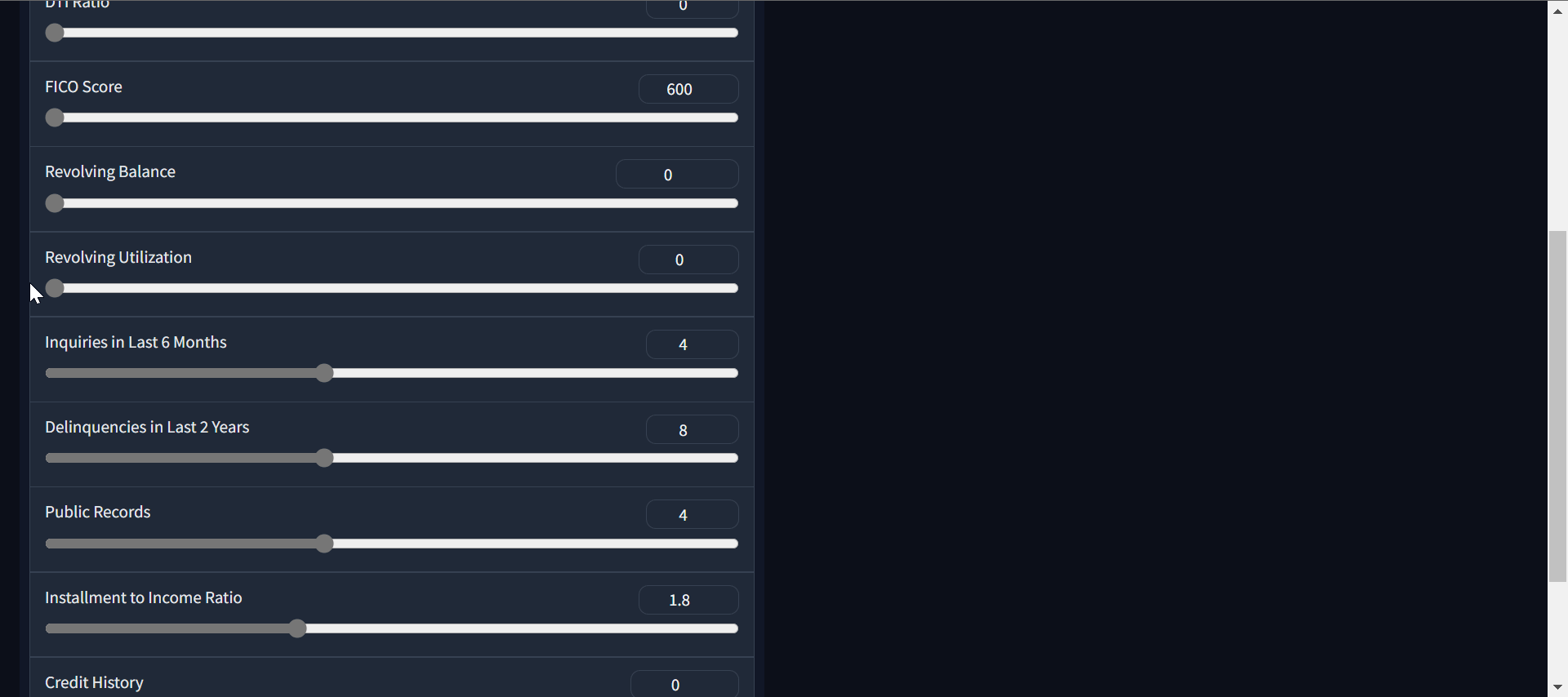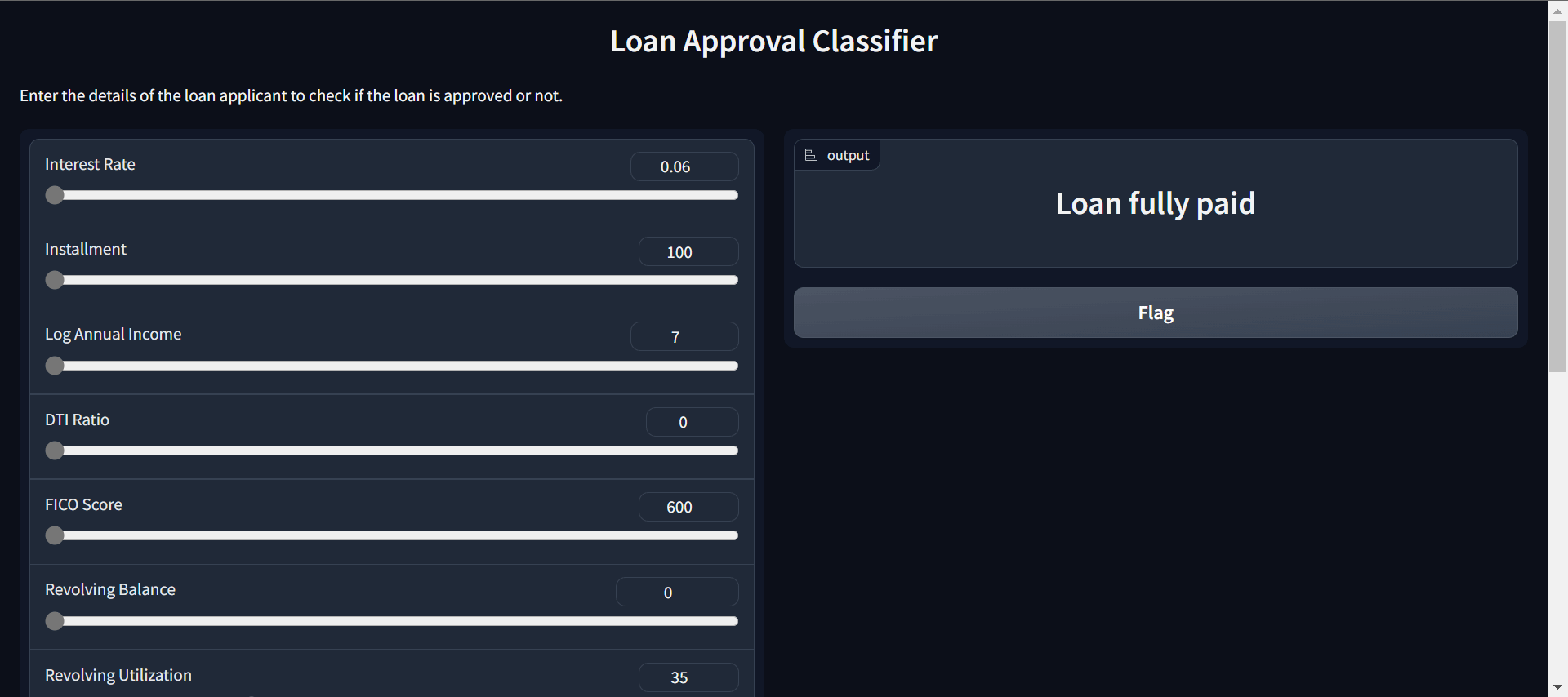
作者動圖 |貸款審批分類器應用
盡管我們的應用程序運行良好,但 ChatGPT 完全錯過了我們縮放了數字特征。因此,您可以返回并保存標準標量參數,而不是要求更新代碼。

之后,使用 joblib 在您的應用程序中加載標量。

那么,我們為什么要手動執行此操作?如果你要求 ChatGPT 修改一行,它可能會修改整個代碼甚至變量名稱。
是的,ChatGPT并不完美,它永遠不會取代開發人員。
在空間上部署 Web 應用程序您可以簡單地要求ChatGPT教您在Hugging Face Spaces上部署gradio應用程序的簡單方法,它將列出必要的步驟。
提示:“如何將 gradio 應用程序部署到擁抱面孔空間。
轉到擁抱臉網站,然后單擊左上角的個人資料圖片以選擇“新空間”選項。
圖片來源:作者
添加名稱和許可證類型以創建應用程序存儲庫。
單擊“文件和版本”選項卡> + 添加文件>“上傳文件”以在存儲庫中添加文件。
拖動 app.py、模型和縮放器文件,然后單擊“將更改提交到主”按鈕,然后使用提交消息保存提交。類似于 Git。
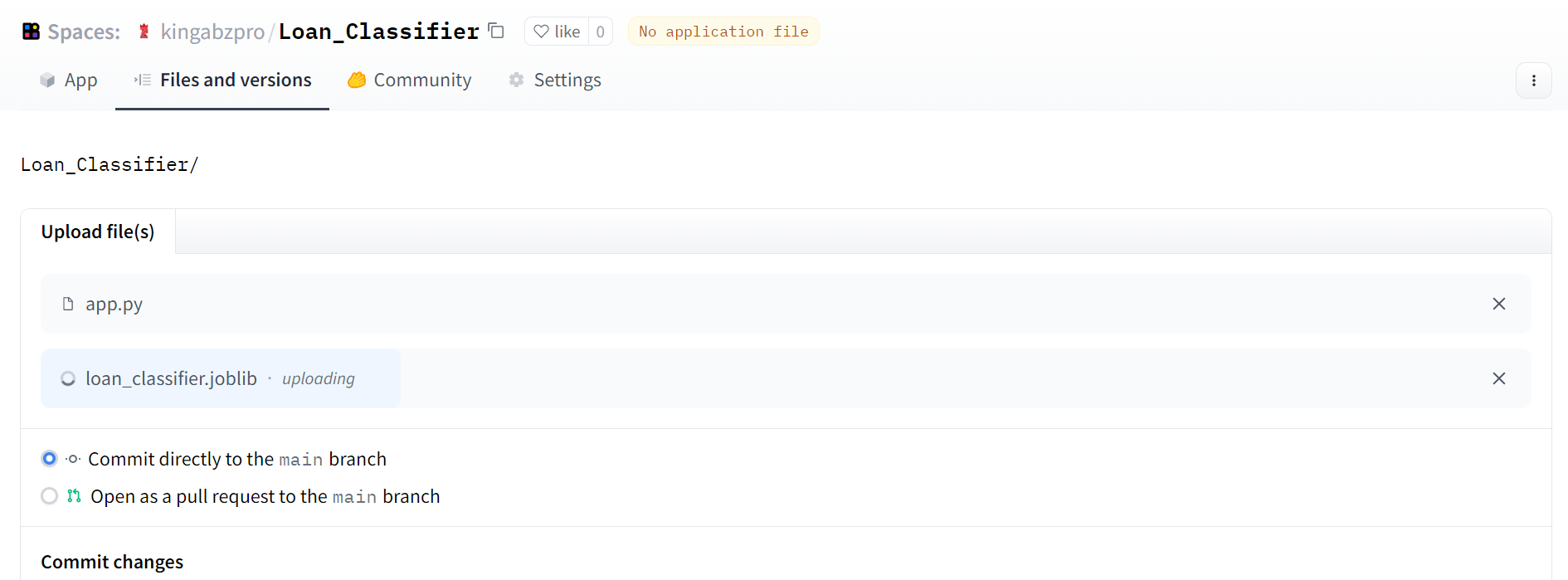
圖片來源:作者
如果您遇到運行時錯誤,那是因為您忘記添加 requirements.txt 文件。選擇“文件和版本”選項卡> + 添加文件>創建一個新文件,并添加文件名和 Python 庫以及如下所示的版本。
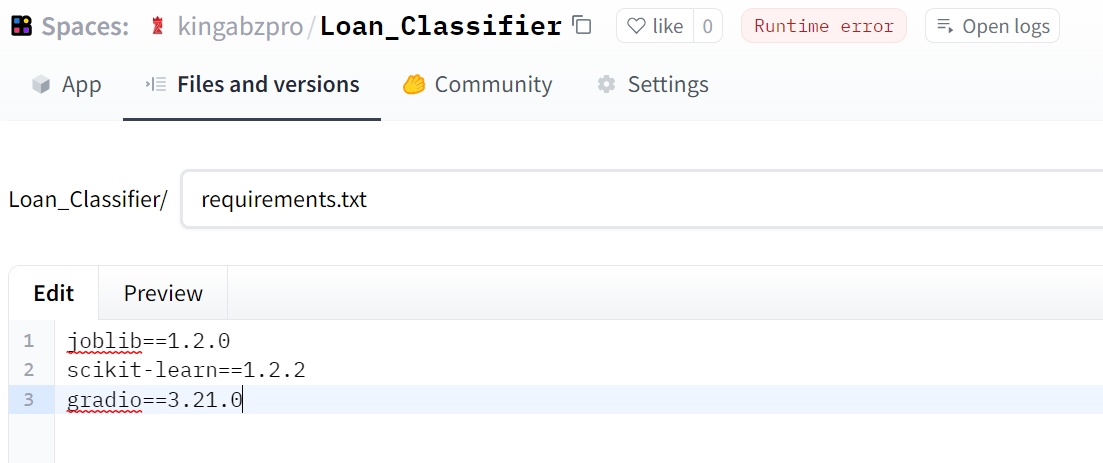
圖片來源:作者
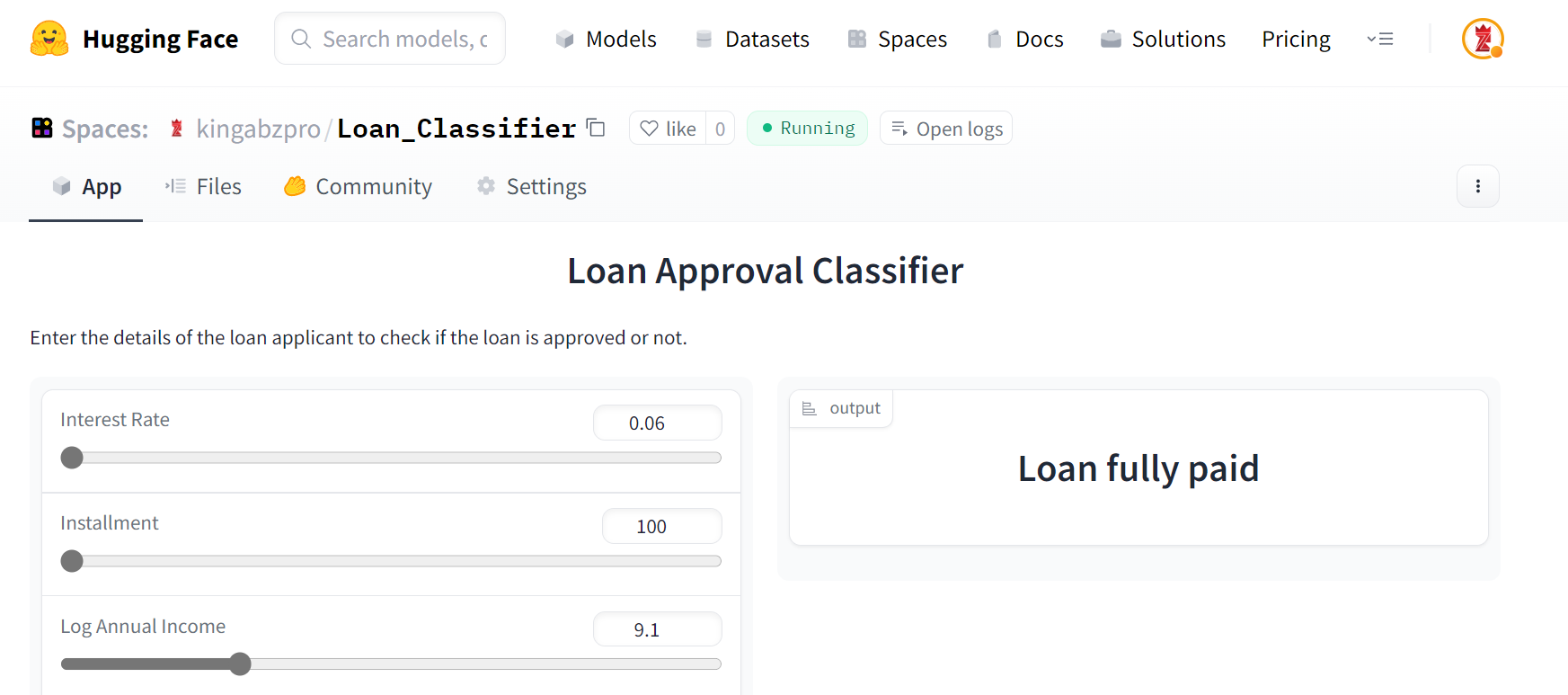
你的應用已準備就緒。您可以使用滑塊更改輸入并預測客戶是否應該獲得貸款。
您可以在kingabzpro的擁抱面部空間上嘗試現場演示。
在將其用于現實生活中的項目時,快速工程是棘手的。我們需要了解我們可以做什么或我們必須介入以糾正 ChatGPT 的規則。
以下是有關如何在不影響項目的情況下改善 ChatGPT 體驗的一些提示。
始終寫出清晰簡潔的提示。確保在開始時詳細解釋您需要什么的所有內容。
創建項目的歷史記錄。ChatGPT 是一個聊天機器人,因此為了有效地理解上下文,您需要建立歷史記錄。
繼續努力。沒有標準的提示編寫方式。您需要從基本提示開始,并通過編寫后續更新提示來不斷改進套裝。
提及代碼錯誤。如果在本地計算機上運行代碼并引發錯誤,請嘗試在后續提示中提及該錯誤。ChatGPT將立即從錯誤中吸取教訓,并提出更好的解決方案。
手動進行更改。ChatGPT 是在舊數據上進行訓練的,如果你期望它提出這個想法或新的 API 命令,你會失望的。盡可能嘗試對代碼進行手動更改,因為生成的代碼并不完美。
將其用于常見任務。如果您要求常見任務,則使用 ChatGPT 成功的機會更大。
用它來學習新東西。始終要求 ChatGPT 解釋新事物或“如何做”教程。它將為您提供完成工作的簡單步驟列表。如果您有學習障礙,這將非常有幫助。
如果您對 ChatGPT 和 OpenAI API 感興趣,請注冊參加網絡研討會:OpenAI API 和 ChatGPT 入門。您將學習如何使用 OpenAI API 等執行語言和編碼生成任務。
結論開發貸款審批分類器是將 ChatGPT 用于數據科學項目的眾多示例之一。我們可以使用它來生成合成數據、運行 SQL 查詢、創建數據分析報告、進行機器學習研究等等。生成式人工智能將繼續存在,它將使我們的生活更輕松。您無需在項目上花費數周和數月的時間,而是可以在數小時內開發、測試和部署數據科學應用程序。
在本教程中,我們學習了使用 ChatGPT 進行項目規劃、數據分析、數據清理和預處理、模型選擇、超參數優化以及創建和部署 Web 應用程序。
使用ChatGPT有一個問題。您需要具有統計分析和Python編碼的經驗,才能理解項目中的不同任務;沒有它,你就是盲目行走。通過參加 Python 數據科學家職業軌跡開始您的數據科學之旅,并獲得成功成為數據科學家所需的職業建設技能。
原文鏈接:將 ChatGPT 用于數據科學項目的指南 (mvrlink.com)
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。









