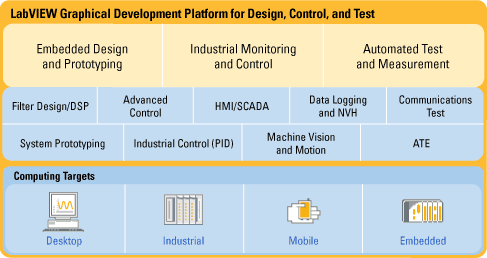
LabVIEW馳騁多核技術時代

任務并行化(Task Parallelism)
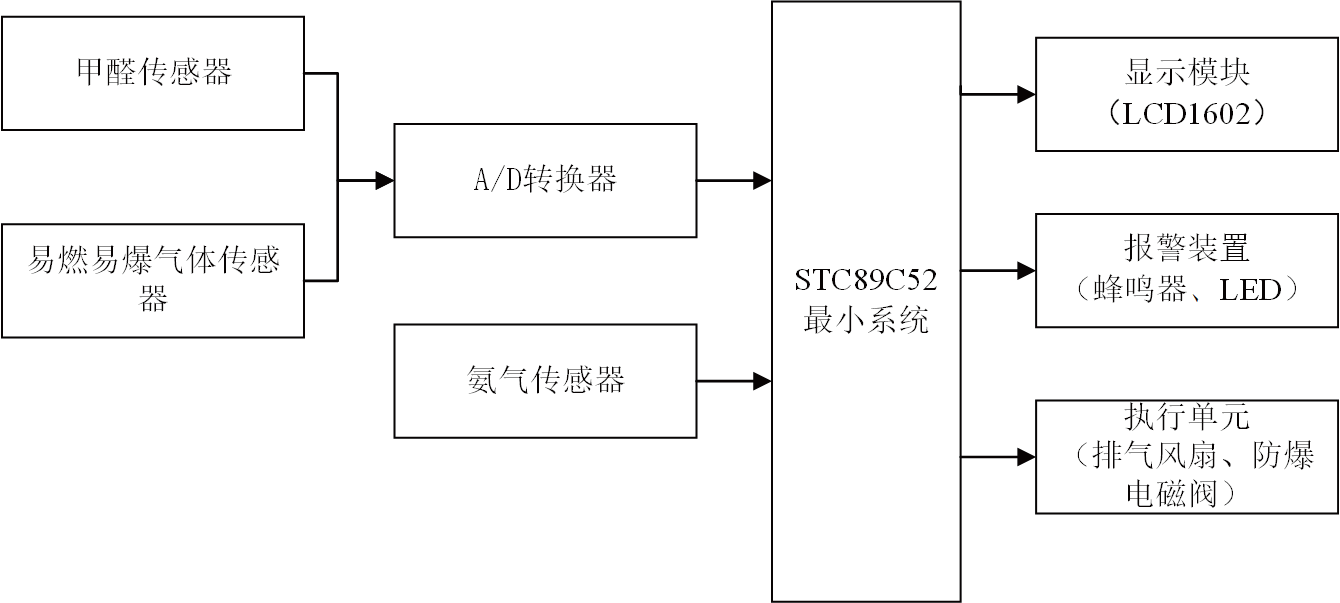
本文引用地址:http://www.j9360.com/article/88205.htm將整個程序分成多個線程來并發運行,是并行編程的一個基本理念,那么通常一個程序都會由幾個子任務組成,例如在某個測試測量程序中,就可以分為模擬采集和數字輸出兩個任務,那么如果我們將這些獨立的任務并發地執行在多核處理器中,那么就自動提高了運行的效率。這種將獨立的幾個任務在程序中并發執行的方法,就叫做任務并行化。
對于任務并行化,如何合理地去實現任務分配是需要解決的問題。首先,我們可以將本身就互相獨立的任務分配在不同線程中,如上例所提到的模擬采集與數字輸出任務,之間就沒有任何的數據連接,因此在LabVIEW中我們就可以并行地將代碼放在程序框圖中,不需要添加任何其他代碼,如圖5所示。
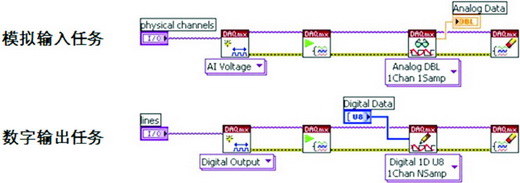
圖5 LabVIEW對獨立任務自動實現“任務并行化”
此外,編程中常見的生產者—消費者循環也是一種任務并行化,在LabVIEW下我們可以將生產者(讀取數據)與消費者(分析數據)分成并行的兩個任務,任務之間的數據交互可以使用隊列結構(Queue)來實現,如圖6所示。
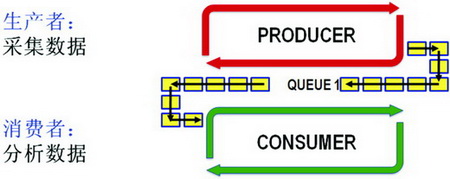
圖6 生產者—消費者模型實現任務并行
數據并行化(Data Parallelism)
除了可以將程序任務進行并行化之外,對于一些海量數據的處理分析,我們還可以將數據分成幾個可并行操作的小數據集,然后分別在各個核上實現并行處理,最后將結果整合起來作為整體數據集的處理分析結果,這種方式稱為數據并行化。
如圖7(a)所示,一個大的數據集僅僅在一個核上進行處理和運算,當核1在處理數據時,其它的三個CPU核都處在閑置狀態,整個系統的運行效率很低。
那么,使用了數據并行化之后,如圖7(b),之前的大數據集被分割成4個小數據集,并將它們在各自的核上進行處理運算,最終再將各自的運算結果整合起來作為大數據集的處理結果。經過了數據并行化之后,整個系統的運算效率有了直線的提升。
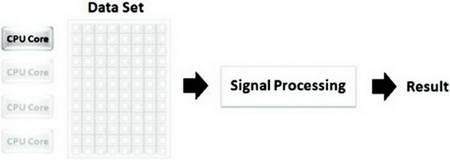
(a)
(b)
圖7 數據并行化
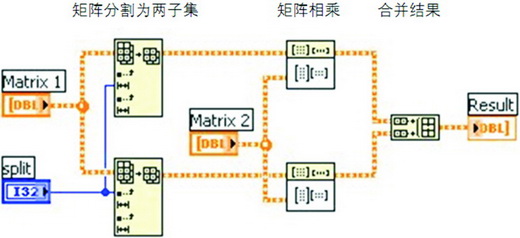
與“任務并行化”類似,在LabVIEW下實現“數據并行化”也相當的直觀與方便,圖8就顯示了一個矩陣相乘的代碼,程序中將兩個大矩陣各自分割成小矩陣進行相乘,最 后再整合起來,僅僅這樣一個簡單的改變就可以在一個雙核處理器上得到0.9倍的性能提高。
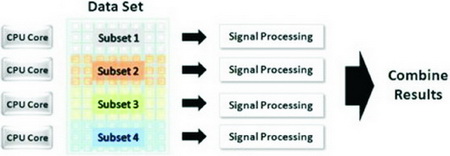
圖8 LabVIEW矩陣相乘的數據并行化
流水線式(Pipeline)
流水線,顧名思義,就是指將一系列的任務分割成固定的幾個步驟,然后按照裝配線的方式來執行。
我們以一個最簡單的汽車裝配線為例,一輛車的裝配完成需要3個步驟:底盤安裝、零件安裝以及上漆。如果每個步驟都需要花費1個小時的話,那么如果一次就裝配一輛車的話,我們需要花3個小時來完成(圖9a)。
那么,如果我們換一種思路,分別對每個步驟設立一個工作站(例如工作站1就專門負責底盤安裝,以此類推,如圖9b)。這樣一來,我們看到,當一輛車在上漆時,另外一輛車可能正在進行底盤安裝。通過這種方式,我們成功實現了每一個小時就能完成一輛車的裝配,是之前裝配速度的3倍。這個例子中所說的工作站,其實就可以算作是CPU各個核,那么通過這種流水線的操作方式,就可以充分利用多核技術,大大提高整個程序的運行速率。

(a)

(b)
圖9 流水線式編程思路
而在LabVIEW下實現流水線式編程也是非常方便,圖10就是一個最簡單的4個步驟的流水線式代碼,在一個For循環中,并行地執行4個處理步驟,系統將這并行的4個步驟放在不同的核上運行,從而起到“工作站”的作用,實現了流水線式的編程。
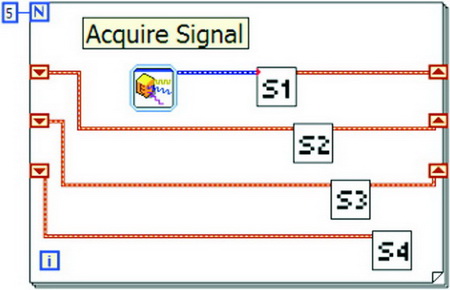
圖10 LabVIEW下實現流水線式編程
綜上所述,任務并行化、數據并行化以及流水線式是并行編程的三種最常用的方式,相對于以往的順序結構,這些編程方式可以在多核處理器上發揮更強大的作用,而在LabVIEW下可以很方便地實現這些編程方式,從而幫助工程師們從多核處理器技術中得益,提升系統的性能和運算速度。
結語
隨著新一代處理器技術的日益普遍,工程師與開發人員的一個必要考慮因素就是他們使用的軟件如何從多核系統中獲得潛在的性能提升。LabVIEW作為天生并行的圖形化編程環境,可以自動將程序多線程化,避免了開發人員繁瑣的底層實現,將主要精力投入在高層的編程模式上;而作為并行編程的三種常用模式(任務并行化、數據并行化以及流水線式),在LabVIEW下也都能高效地予以實現。因此,不容置疑的是,隨著具有更多核的處理器不斷涌現,LabVIEW將幫助開發人員真正邁入并行,馳騁多核技術時代!
參考文獻:
1. 劉全周,汪看華,張宏偉,基于LabVIEW和PXI的汽車數字儀表測控系統,電子產品世界,2008.2






評論