LTE標準下Turbo碼編譯碼器的集成設計

LTE[1](Long Term Evolution)是3GPP展開的對UMTS技術的長期演進計劃。LTE具有高數據速率、低延遲、分組傳送、廣域覆蓋和向下兼容等顯著優勢[2],在各種“準4G”標準中脫穎而出,最具競爭力和運營潛力。運營商普遍選擇LTE,為全球移動通信產業指明了技術發展的方向。設備制造商亦紛紛加大在LTE領域的投入,其中包括華為、北電、NEC和大唐等一流設備制造商,從而有力地推動LTE不斷前進,使LTE的商用相比其他競爭技術更加令人期待。
Turbo碼[3]以其接近香農極限的優異糾錯性能被選為LTE標準的信道編碼方案之一[4]。對Turbo編譯碼器進行FPGA集成設計,能夠加速LTE的商用步伐,具有廣闊的應用前景。在不同的信道環境中,通信系統對信息可靠性和數據實時性具有不同的指標要求,實際應用中必須對二者進行適當折中。因此,硬件設計一種糾錯性能與譯碼時延可靈活配置的Turbo碼編譯碼器更具商業價值。
Altera公司推出的功率優化、性能增強的Stratix III系列產品采用了與業界領先的Stratix II系列相同的FPGA體系結構,含有高性能自適應邏輯模塊(ALM),支持40多個I/O接口標準,具有業界一流的靈活性和信號完整性。Stratix III FPGA和Quartus II軟件相結合后,為工程師提供了極具創新的設計方法,進一步提高了性能和效能[5]。Stratix III L器件邏輯單元較多,為幀長可配置Turbo碼編譯碼器的FPGA設計提供了便利條件。
Turbo碼的誤碼性能在很大程度上取決于信息幀長,信息幀越長,譯碼性能越好,代價是譯碼延時的增大。基于這一點,本設計提出一種幀長可配置的Turbo碼編譯碼器的FPGA實現方案,詳細介紹了該系統中交織器的工作原理,并對時序仿真結果和功能實現情況進行了分析,為LTE標準下Turbo編譯碼專用集成芯片的開發提供了參考。
1 幀長可配置的Turbo編譯碼器的系統結構
LTE標準中,信道編碼主要采用Tail Biting(咬尾)卷積碼和Turbo編碼[4]兩種方案。其中Turbo碼碼率為1/3,由兩個生成多項式系數為(13,15)的遞歸系統卷積碼(RSC)和一個QPP(二次置換多項式)隨機交織器組成,采用典型的PCCC編碼結構。
根據Turbo碼編譯碼結構原理可知,信息幀長關鍵取決于交織深度的大小,如果交織器能夠根據不同幀長參數自動植入不同的交織圖樣,并對其他模塊進行相應參數控制,即可實現設計功能。由此得到可配置Turbo編譯碼器的設計思想:在編譯碼之前,由鍵盤電路輸入信息幀長,系統據此對編譯碼器進行初始化,主要包括設置電路中存儲器的深度,計算、存儲交織圖樣,并通過LCD同步顯示幀長信息;初始化過程結束時輸出狀態標志位,編譯碼器進入準備狀態,一旦有數據輸入,即啟動編譯碼流程。由此得到Turbo編譯碼器系統結構圖如圖1所示。
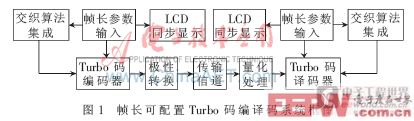
圖1的Turbo碼編譯碼器中,所有有關信息長度的參數均設置為輸入變量,包括存儲器深度、計數器周期等,以方便配置。
2 FPGA功能模塊的設計與實現
2.1 交織模塊的設計
交織器是Turbo編譯碼器的主要構成部分之一,其能否根據幀長參數產生相應的交織圖樣也是本設計的關鍵所在。LTE標準中規定交織器采用QPP偽隨機交織方案,交織長度范圍為40~6 114,該方案對不同幀長產生不同的交織圖樣,能夠有效改善碼字的漢明距離和碼重分布。假設輸入交織器的比特序列為d0,d1,…,dK-1,其中K為信息序列幀長,交織器輸出序列d′0,d′1,…,d′K-1。則有:

參數f1和f2取決于交織長度K,具體值可參見參考文獻[4]。
傳統交織器的FPGA設計一般采用軟件編程的方法。根據通信協議,將所確定幀長的交織圖樣預先計算出來,生成存儲器初始化文件(.mif或.hex格式)載入到ROM中[6]。這樣雖然降低了硬件復雜度,卻不能自行配置編碼幀長,缺乏靈活性和通用性。因此,設計中將交織算法集成于FPGA內部,需要改變信息幀長時啟動交織器重新計算交織地址存儲于RAM中。QPP交織器的硬件結構框圖如圖2所示。
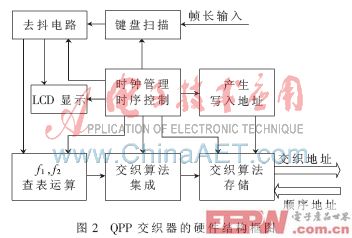
圖2中,在系統初始化階段,由鍵盤電路采集輸入的信息幀長K,經消抖處理,一路傳輸給LCD同步顯示模塊,另一路傳送到f1、f2運算單元,查表得到f1、f2的值,提供給交織算法集成模塊。
交織算法集成單元是交織器設計的核心部分。主要功能是根據LTE協議標準以及參數K、f1、f2,在時序控制模塊的約束下,計算交織地址。運算過程中,將FPGA不能綜合的對任意整數取余的運算,均轉化為固定次數的加減循環操作,在時鐘管理模塊的控制下,采取小時鐘計算、大時鐘輸出的措施,保證交織數據的正確讀取。
計算交織地址的同時產生寫入地址,將交織地址順序存儲到雙口RAM中,由此完成了交織器的主體設計。隨后發送握手信號,可以開始Turbo碼編譯碼流程。
因為并不是每幀信息編譯碼時都需要運行交織算法模塊,所以只是在初始化階段載入交織地址,使交織算法與編譯碼器分時工作。調用交織器模塊時只需將順序地址輸入到雙口RAM的讀地址端,便能得到既定幀長的QPP偽隨機交織地址,不會增加譯碼延時。得到交織圖樣以后即可進行交織、解交織過程[7]。
2.2 Turbo碼編碼器的設計
在完成交織模塊的基礎上對Turbo碼編碼器進行FPGA設計。Turbo碼編碼器由RSC(遞歸系統卷積碼)子編碼器、交織器、復接電路等構成,硬件實現框圖如圖3所示。
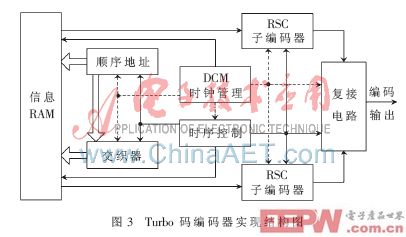
系統初始化完畢后,交織器已存儲有對應幀長的交織圖樣,編碼器首先接收到一幀信息存儲于RAM中,開始信號啟動編碼過程。在時鐘管理模塊和時序控制模塊的指引下,計數器產生順序地址,再按該順序地址訪問交織器得到交織地址,分別以順序地址和交織地址從存儲有信息序列的RAM中讀取數據進入對應的RSC進行編碼,同時復接電路對信息位和校驗位進行并串轉換,一幀信息編碼完畢對子編碼器做歸零處理。
2.3 Turbo碼譯碼器的設計
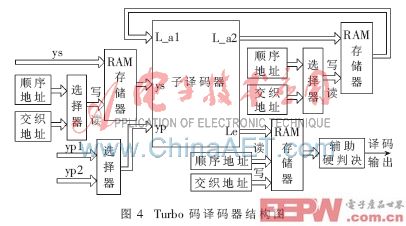
Turbo碼譯碼器相對于編碼器來說硬件結構更加復雜,根據譯碼原理和交織器實現方式,得到譯碼器實現結構圖如圖4所示。











評論