高性能路由器硬件抽象層的關鍵技術研究

1 引 言
隨著Internet的飛速發展和寬帶技術的不斷出現,骨干網絡核心路由器的體系結構也發生了一些變化。近年來,高性能路由器體系結構的研究和國內外主流廠商生產的大部分商用高端路由器的實現方案中,普遍采用了集中式交換、分布式報文處理和轉發的體系結構[1,2]。
文獻[3]提出了硬件抽象層(Hardware AbstractionLayer,HAL)的設計思想,成功地解決了分布式路由器面臨的通用性支撐軟件系統結構設計問題,為構建開放通用的路由器軟件基礎平臺提供了保證。硬件抽象層包括虛擬驅動、系統管理和內部通信3大模塊,在整個路由器系統中的位置如圖1所示。
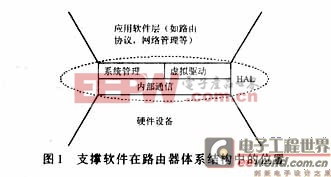
結合國家863重大課題“高性能IPv6路由器基礎平臺及實驗系統”,將文獻[3]中提出的硬件抽象層在嵌入式實時操作系統Hard HatLinux中進行了實現。本文針對高性能路由器體系結構的特點,研究了硬件抽象層在實現過程中的關鍵技術。主要包括虛擬驅動的動態加載模式、基于分隔符的TCP實時傳輸方法、基于地址映射的內核態與用戶態間的阻塞式數據交換機制幾個內容。
2 支撐軟件在高性能IPv6路由器中實現的關鍵技術
2.1 虛擬驅動的動態加載模式
虛擬驅動模塊是模擬線路接口單元動作的重要部分,他的靈活性和可擴展性直接影響硬件抽象層的可用性。
在Linux操作系統下,該模塊是作為一個內核模塊來實現的。他可以實現實時動態加載,與靜態加載相比具有很大的靈活性。編譯時,內核模塊可單獨進行模塊的編譯調試,縮短了調試時間;使用時,將該模塊鏈接到內核,便可發揮模擬線路接口單元的作用;擴展或升級時,可以將其卸載后進行修改。除此之外,動態加載還可以縮減Linux內核的大小,使編譯后的內核小巧,占用內存較少,提高了運轉速度。
2.2 基于地址映射的內核態與用戶態間的阻塞式數據交換機
Linux操作系統中的進程分為用戶態進程和內核態進程2類,用戶態進程不能直接執行運行在內核態的內核代碼或者存取操作系統內核的數據結構。在內存管理方面,Linux系統采用虛擬內存管理機制,設置了兩級頁表結構,通過頁面地址和在該頁中的偏移量就可以惟一確定虛擬地址所對應的物理地址。
在硬件抽象層的實現中,內部通信處于用戶態,虛擬驅動處于內核態。而他們之間不可避免地需要進行一些數據的傳遞,即處于Linux 不同空間的2個進程要進行通信。但是,這2個模塊分處于Linux系統的用戶空間和內核空間,數據指針如何傳遞是一個問題,指針傳遞后如何映射又是一個問題。因此用戶態與內核態之間內存地址的傳遞和轉換成為了提高硬件抽象層工作效率的關鍵。
2.2.1 內核態與用戶態的指針傳遞
先來解決內存地址的傳遞問題,根據Linux驅動程序的特點,選擇ioctl()函數來傳遞指針。該函數屬于系統調用,調用后將一個類型為ifreq的結構指針變量ral_ifr從用戶態傳入內核態,該結構的定義在/include/linux/if.h中。
使用了其中的ifrn_name和ifru_data兩個域,其中ifrn_name代表設備的名稱,即虛擬網絡接口設備名,ifru_data為所要傳遞的數據指針。使用系統調用ioctl()之后,用戶空間到內核空間的指針傳遞就完成了。內核空間到用戶空間的指針傳遞過程與其相反。因此,下一步要進行的是內核空間與用戶空間數據指針的映射。
2.2.2 內核態與用戶態的內存映射
由2.2.1可知,用戶空間的指針通過ioctl傳入內核空間后,他本身并沒有發生改變,需要進行虛擬地址到物理地址的映射才可以對其進行讀寫操作。
由文獻[4]分析可知,可以使用內核kiobuf機制,他能提供從內核空間對用戶內存的直接訪問。內核kiobuf機制的設計初衷就是為了便于將用戶空間的緩沖區映射到內核。使用他能夠獲得數據的頁面起始位置、頁數和偏移量等具體參數,因此可在內核空間對用戶態申請的內存進行操作。
首先分配一個內核I/O向量(kiovec)來產生kiobuf,使用函數如圖2所示。

然后再對其進行初始化,如圖3所示。

最后,將通過ioctl傳入的用戶空間指針ifru_data映射到內核態,使用函數map_user_kiobuf,如圖4所示。

這樣就完成了將指針由用戶空間映射到內核空間的過程,實現了從虛擬地址向物理地址的轉換。
至此,內核空間與用戶空間的內存映射問題得到了很好的解決。通過解決內存地址映射的問題,內部通信和虛擬驅動之間就可以只傳遞數據指針,大大提高了模塊的運行效率。
2.3 基于分隔符的TCP實時傳輸方法
2.3.1 Nagle算法的弊端
糊涂窗口綜合癥(Silly WindowSyndrome)的出現使網絡開銷過大,從而造成TCP性能變壞。根據文獻[5]所述,糊涂窗口綜合癥的解決方法就是采用文獻[6]中所建議的Nagle算法。但是在實際應用時發現,Nagle算法的不足之處主要有2點:
(1)在限制數據報頭部信息消耗的帶寬總量的同時,是以犧牲網絡延遲為代價的。
(2)在發送方的緩沖區中,應用程序發送的數據包發生了粘滯的現象,即發送的若干數據包到接收方接收時變成一包,分不出各個包的界線。
前者因為數據被排隊而不是立即發送的,因此不適用于需要快速響應時間的系統。后者則會影響到接收方的數據處理的準確性。第一種不足可以通過使用PUSH標記來實現,發送方如果使用了該標志,會立即將緩沖區中的數據發送出去。對于第二個問題,解決起來就比較復雜,因為出現數據包粘滯現象的原因既可能由發送方造成,也可能由接收方造成。
2.3.2 基于分隔符的TCP實時傳輸方法
采用了基于分隔符的TCP實時傳輸方法來解決包粘滯問題。該方法在應用層數據包的起始部分附加上有特定格式的分隔符和數據長度域,其中分隔符用于界定數據包之間的界限,長度域則用于表示該數據包的實際長度。
首先,所有經內部通信模塊傳輸的數據,都需要進行一次內部固定格式的封裝。封裝后數據包的包頭,是由內部通信模塊自定義的,起始位置是分隔符和長度域。其次,接收方按照內部通信模塊的自定義的包結構,接收后對數據流進行預處理,還原成為應用程序可正確識別的數據包。預處理的原理如下:先查找包頭中的分隔符,他標識著一個數據包的開始;接下來的域表示的是實際數據包的長度len,取出緊跟在包頭后的長度為len的那段數據,這就是需要應用程序處理的數據包。
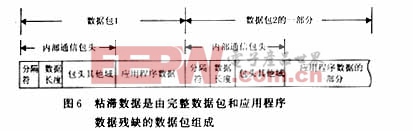
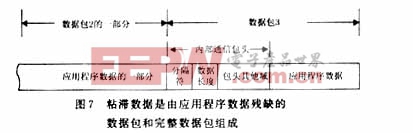
包粘滯的情況具體可細分為3大類,這里均以2個應用程序數據包粘滯成一段的情況為例,如圖5~圖9所示,當應用程序數據包個數為n時,可采用類似的方法進行處理。



第1類,粘滯數據是由完整的數據包組成的,如圖5所示。這種情況的處理非常簡單,按分隔符找到數據包的起始位置,再根據數據長度取出應用程序數據即可。
第2類,粘滯數據是由完整數據包和應用程序數據殘缺的數據包組成,如圖6和圖7所示。處理時,需要對殘缺數據包2的應用程序數據部分進行保存,內部通信包頭的數據長度域也要記錄下來,以便下次接收時知道應用程序數據剩余部分的長度。再次收到數據時,就根據剩余長度取出一段數據,與上次保存的應用程序數據合為一個完整的數據包。
第3類,粘滯數據是由完整數據包和內部通信包頭殘缺的數據包組成,如圖8和圖9所示。首先,要將如圖8所示數據段中收到的殘缺的這部分包頭保存起來,然后收取下一次數據如圖9所示。再從收取的數據中,截取可以與上次殘缺包頭組成完整的內部通信包頭的一段報文,形成所需要的內部通信包頭。當然,該段數據有可能并不是內部通信包頭,這可以從分隔符是否正確等內部通信封裝格式來判斷。如果發生這種情況,就要將指針以字節為單位,順次向后滑動,直到找到真正的內部通信包頭為止。然后根據包頭中的信息,取出相應長度的應用程序數據交送給應用程序接收者。
解決了上述分析的2大不足之后,內部通信模塊中實現的TCP傳輸,在保證數據傳輸的良好的可靠性和流控性之外,還具備了一定的實時性能和防止數據包粘滯的功能。
3 結 語
本文研究了硬件抽象層在高性能IPv6路由器實現中的關鍵技術,主要分析了虛擬驅動的動態加載模式、基于分隔符的TCP實時傳輸方法、基于地址映射的內核態與用戶態間的阻塞式數據交換機制。通過上述關鍵技術的研究,使硬件抽象層得以實時、高效地運行,并且已穩定運行于高性能IPv6 路由器中。






評論