使用TI的Vision AccelerationPac,實現汽車可視探測

引言
到2013年9月,谷歌的自主駕駛汽車已在計算機控制下成功行駛了500000多英里,并且沒有發生過一起交通事故[1]。谷歌具有革命性的無人駕駛汽車項目旨在利用攝像頭、雷達傳感器和激光測距儀(以及谷歌的地圖數據庫)監測和引導汽車行駛,從而提高汽車駕駛的安全性和效率。谷歌的無人駕駛汽車原型車使用了價值150,000美元的機器人組件,包括價值70,000美元的激光雷達系統,因此距離商用還有很長的路要走。2013年8月,尼桑汽車公司宣布計劃于2020年前推出無人駕駛汽車,以實現零交通事故死亡率。自主駕駛汽車商用化進展的重點工作是,如何讓自主駕駛汽車價格更低、可靠性和安全性更高。實現自主駕駛汽車的關鍵技術之一是計算機視覺,其使用基于攝像頭的視覺分析,目的是提供高可靠、低成本的視覺解決方案。盡管基于攝像頭的傳感器成本低于其它技術,但其處理要求會急劇增加。今天的系統要求我們處理30幀每秒、1,280x800分辨率的圖像,通常會同時要求運行5種以上的算法。德州儀器最新的應用處理器TDA2x基于OMAP5技術,擁有頂級的Vision AccelerationPac,可以高效率、低成本、可編程和靈活地實現高級駕駛輔助系統(ADAS),以支持自主駕駛汽車的20/20視覺功能。Vision AccelerationPac是一種可編程加速器,擁有專用硬件單元和定制過程,可使用高級語言實現完全編程。它允許視覺開發人員使用標準處理器架構所不具備的一些高級性能。使用高級語言實現的Vision AccelerationPac可編程支持,允許終端汽車制造廠商在算法調整方面進行探索,做出一些具有創新性的解決方案。當這些算法遠未成熟時,這種功能特別重要,并且對于縮短產品上市時間也至關重要。
長眼睛的汽車
美國人口普查局的統計數據表明,在美國,平均每年發生600萬起機動車交通事故。16-24歲年青人的交通事故死亡率最高。該統計數據還表明,大多數交通事故的原因均為人為操作失誤。人們相信,給機動車加裝視覺和智能裝置可以減少人為操作失誤,降低交通事故發生率,從而挽救生命。另外,人們還認為,汽車視覺系統可以幫助緩解交通擁堵,提高公路通行能力,提高汽車燃油效率,并提高駕駛者的行車舒適性。
高級駕駛輔助系統(ADAS)是朝著完全自主駕駛汽車的目標邁出的關鍵性一步。ADAS系統包括但不限于自適應巡航控制、車道保持輔助、盲點探測、車道偏離警告、碰撞警告系統、智能速度自適應、交通標志識別、行人保護與物體探測、自適應燈光控制和自動泊車輔助系統。
攝像頭是一種低成本方法,涵蓋許多交通應用環境,可用于智能分析。立體前置攝像頭可用于自適應巡航控制,監控實時交通狀況,幫助保持與前車的最佳距離。前置攝像頭還可用于車道保持輔助,讓汽車保持在車道中間,也可用于交通標志識別和物體探測。側攝像頭可用于并道監控、盲點探測和行人感知。
攝像頭后臺數據分析功能,讓汽車擁有類似人類視覺的能力。實時視覺分析引擎需要對每一個視頻攝像幀進行分析,提取正確的信息來做出智能決策。它不僅僅需要超強的計算能力,在瞬間對數據進行處理,以讓快速運動的汽車做出正確的機動,還需要寬I/O來提供多個攝像頭的視覺分析引擎輸入,從而實現同步關聯。低功耗、低延遲和可靠性也是汽車視覺系統的幾個關鍵方面。
TI技術實現者—Vision AccelerationPac
TI的Vision AccelerationPac是一種可編程加速器,專門用于滿足汽車、機器視覺和機器人市場計算機視覺應用的處理、功耗、延遲和可靠性需要。Vision AccelerationPac包含一個或者多個嵌入式視覺引擎(EVE),用于實現嵌入式視覺系統的可編程性、靈活性、低延遲處理和功率效率以及小硅片面積,因此可實現性能與價格的優異結合。相同功率級別下,相比現有ADAS系統,每個EVE擁有8倍以上的高級視覺分析計算性能改善。詳情,請參看圖1。

圖1 Cortex-A15相同功率預算時計算性能為原來的8倍以上
圖2顯示了Vision AccelerationPac架構。
Vision AccelerationPac內有一個或者多個EVE,它是一種視覺優化處理引擎,包括一個32位自適應專用RISC處理器(ARP32)和一個512位矢量協處理器(VCOP),并使用內置機制和獨特的視覺專用指令,用于同時、低開銷處理。ARP32包括32KB的程序緩存,用于實現高效程序執行。它還擁有一個旨在簡化調試的內置仿真模塊,并與TI的Code Composer Studio?集成開發環境(IDE)兼容。共有3個并行平面內存接口,每個接口均有256比特加載與存儲帶寬,共提供768比特寬內存帶寬(是大多數處理器內部內存帶寬的6倍),并擁有共計96KB L1數據內存,可實現極低處理延遲的同步數據傳送。每個EVE還具有一個本地專用直接內存訪問(DMA),用于主處理器內存的數據進出傳輸,以實現快速數據傳送,同時還有一個內存管理單元(MMU),用于地址翻譯和內存保護。為了實現可靠運行,每個EVE還在所有數據內存上使用單比特誤差檢測,對程序內存使用雙比特誤差檢測。一個關鍵的架構級功能是DMA引擎、控制引擎(RISC CPU)和處理引擎(VCOP)的完全并發。例如,它讓ARP32 RISC CPU可以在處理一個中斷命令或者執行順序代碼的同時,VCOP執行一個循環并在底層對另一條語句解碼,并在沒有任何架構或者內存子系統停止工作的情況下傳送數據。另外,它還通過硬件郵箱方法,對處理器間通信提供嵌入式支持。大多數高功效視覺處理中,EVE僅使用400mW的最大總功耗,便實現了8GMAC處理性能和384Gbps數據帶寬。
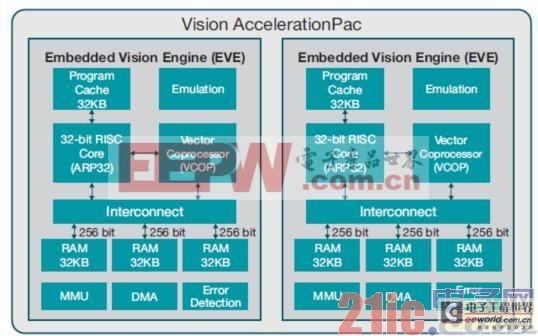
圖2 Vision AccelerationPac架構
VCOP矢量協處理器是一種帶嵌入式環路控制和地址生成的單指令多數據(SIMD)引擎。它提供每周期16個16位倍增器的雙8路SIMD,以及500MHz頻率持續數據流量下8GMACS每秒的速度,其由舍入和飽和相關加載/存儲與內置的零循環開銷維持。它可以三源運行,讓兩個矢量單元提高兩倍,每個周期多計算32個32位。VCOP還具有8個地址生成單元,每個均擁有4維地址功能,能夠存儲4個嵌套循環和3個內存接口的地址,從而實現4級嵌套循環零開銷。它大大減少了迭代像素操作所需的計算周期。矢量協處理器擁有許多專用通道,用于加速柱狀圖、加權直方圖和查詢表,并支持一般計算機視覺處理級,例如:梯度、方向、排序、位交錯/去交錯/置換、全景圖像和局部二進制模式。另外,矢量協處理器還具有一些實現靈活性和并發加載存儲運行的專用指令,旨在加速重要解碼和分散/集合運行區,從而實現非鄰近內存數據的高效處理。它最小化了傳統圖像處理程序所需的常見數據傳輸和拷貝,實現超快處理性能。同標準處理器架構相關的各種功能處理速度提高4到12倍是正常的。VCOP本身就支持分散/集合和重要處理區功能。排序是一種常見的計算機視覺功能,其發生在一些多用情況下,例如:追蹤目標特性識別和密集光流搜索匹配等。EVE極大加快了自定義指令支持排序,從而使EVE能夠在15.2μ秒內對2048個32位數據點進行排序。
利用標準TI代碼生成工具套件可對Vision AccelerationPac進行完全編程,允許直接編譯軟件,并在PC上運行來模擬。通過TI的實時操作系統BIOS(RTOS),ARP32 RISC內核可以完全運行C/C++程序。通過TI的VCOP內核C構建的C/C++專用子集,對VCOP矢量協處理器編程。VCOP內核C是一種模板化的C++矢量庫,其通過一種高級語言顯示相關硬件的各種功能。利用一些標準編譯器(例如:GNU GCC或者Microsoft? MSVC等),可以在一臺標準的PC或者工作站上評估和驗證寫入VCOP內核C的算法。它允許開發人員在算法開發過程初期融入矢量化和驗證位精確度,并對大量數據集進行測試,從而確保算法的穩健性。只需使用TI的代碼生成工具對源代碼進行重新編譯,這些算法便可直接運行在Vision AccelerationPac上。寫入VCOP內核C的程序有許多優點;它們經過優化后可使用Vision AccelerationPac架構和指令集,擁有特殊的循環結構,可對矢量數據進行操作,并且在C聲明和匯編語言之間有一個幾乎是一對一的映射,從而得到非常高效的代碼,代碼體積和內存占用較小。
共有超過100個Vision AccelerationPac編程舉例。相比VCOP內核C,使用ARM? NEON? SIMD的陣列添加簡單例子表明,在6個周期中,ARM可以增加4個32位值,從而獲得1.5周期每輸出的內循環性能,同時,VCOP充分使用其768位加載存儲帶寬,在一個周期內獲得8個輸出。該結果相當于1/8周期每輸出的吞吐量,其實現了12倍于ARM的總體周期到周期速度。
Vision AccelerationPac內部EVE的ARP32 RISC內核針對控制代碼和順序處理進行了優化。它支持運行SYS/BIOS、TI的實時操作系統,因此提供了對線程、信號和其它RTOS特性的支持。
EVE受到全套代碼生成工具的支持,包括TI的Code Composer Studio IDE中集成的優化編譯器即模擬器。EVE通過硬件計數器對非侵入式性能監控提供嵌入式支持。它允許用戶對多個性能信號進行監控,與此同時,在無需進行任何代碼修改的情況下,應用程序運行并允許深度監控應用程序的運行時間表現。


評論