數據融合技術在車牌字符識別中的應用研究

運用模糊理論進行模式識別時通常采用3 種方法:隸屬原則識別法、擇近原則識別法以及模糊聚類分析法。設計中選用了隸屬原則識別算法對3 個BP 網絡的識別結果進行最終決策。隸屬原則識別法的難點在于隸屬度函數的選擇。

由于每個BP 網絡提取的是字符的不同特征, 各網絡參數的設置也各不相同,導致3 個神經網絡對同一個測試字符的輸出向量和識別率各不相同,所以設計中是從這兩個方面出發確定隸屬度函數。3 個BP 網絡對同一個字符進行識別時的輸出向量構成一個3 行50 列(設計中所需識別的字符共計50 類)的矩陣M,統計出3 個BP 網絡的識別率后將其歸一化為一個1 行3 列的矩陣N,確定隸屬度函數可通過兩矩陣相乘Q=N[1×3]·M[3×50]得到,相乘結果Q[1×50]為一個行向量,取該向量中最大值所對應的字符作為模糊決策的最終結果,如式3 所示:
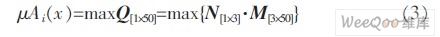
3 仿真結果及其分析
應用MATLAB 軟件對上述各個模塊所采用的算法進行了仿真,效果如圖2 所示。仿真結果表明,針對同一幅車牌圖像,3 個BP 網絡給出了不同的識別結果,但是通過決策層的模糊推理融合算法仍然能夠正確地識別。

設計*采集到實際的車輛圖像84 套, 其中因無法準確定位或字符分割的圖像共12 套, 在剩余的72 套圖像中,用其中的50 套作為神經網絡的訓練樣本,其余22 套作為測試樣本,對車牌識別,經實驗統計,其結果如表1 所示。
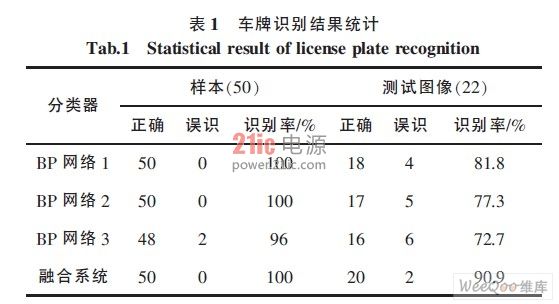
由以上統計結果可明確的看出,應用數據融合技術系統的識別率較單一識別方法有了較大的提高, 達到了90.9%。
4 結束語
基于數據融合理論, 將不同的識別方法有效地結合起來構成融合型車牌字符識別系統, 數據層應用了加權平均算法, 特征層選用了BP 神經網絡, 決策層采用了模糊推理算法。實驗證明, 該系統能有效的實現車牌字符識別, 字符識別率達到了90%以上, 較采用單一識別方法有了較大的提高。通過融合使信息資源得到了充分利用,各種方法互補,系統性能得到了很大提高。對于特征層融合應用的BP 神經網絡算法, 直接使用了前人的研究成果,可對網絡的參數設置及收斂速度進一步的研究,加以改善提高。







評論